强化学习(3)-----DQN
看这篇https://blog.csdn.net/qq_16234613/article/details/80268564
1、DQN
原因:在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不现实。
通常做法是把Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作。如下式,通过更新参数 θ 使Q函数逼近最优Q值 。
Q(s,a;θ)≈Q′(s,a)
而深度神经网络可以自动提取复杂特征,因此,面对高维且连续的状态使用深度神经网络最合适不过了。
DRL是将深度学习(DL)与强化学习(RL)结合,直接从高维原始数据学习控制策略。而DQN是DRL的其中一种算法,它要做的就是将卷积神经网络(CNN)和Q-Learning结合起来,CNN的输入是原始图像数据(作为状态State),输出则是每个动作Action对应的价值评估Value Function(Q值)。
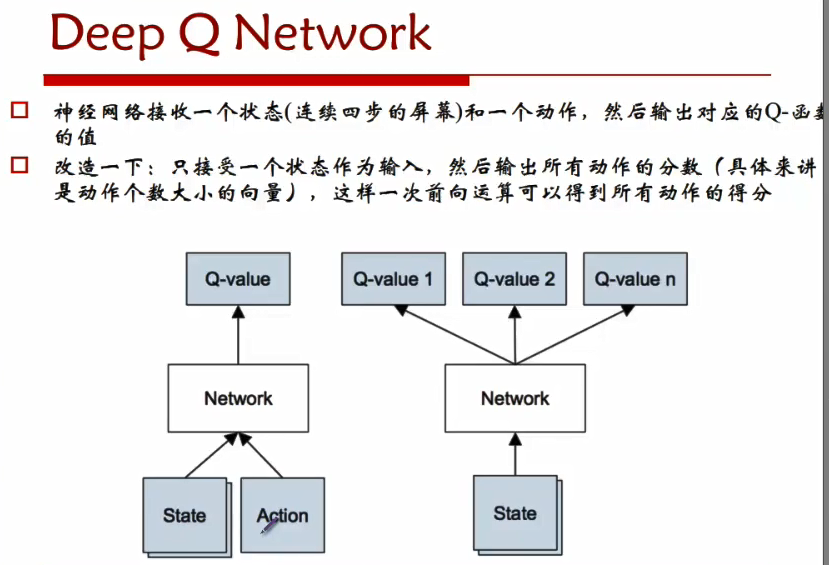
2、模型:

3、算法
2013版

2015版


其实就是反复试验,然后存储数据。接下来数据存到一定程度,就每次随机采用数据,进行梯度下降。 他根据每次更新所参与样本量的不同把更新方法分为增量法(Incremental Methods)和批处理法(Batch Methods)。前者是来一个数据就更新一次,后者是先攒一堆样本,再从中采样一部分拿来更新Q网络,称之为“经验回放”,实际上DeepMind提出的DQN就是采用了经验回放的方法。为什么要采用经验回放的方法?因为对神经网络进行训练时,假设样本是独立同分布的。而通过强化学习采集到的数据之间存在着关联性,利用这些数据进行顺序训练,神经网络当然不稳定。经验回放可以打破数据间的关联。
另外,为了保证算法稳定收敛,还使用了经验回放(experience replay)技术。所谓 t 时刻的经验 e_t ,就是 t 时刻的观测、行为、奖励和 t+1 时刻的观测集合。
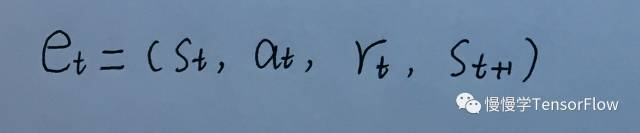
将时刻 1 到 t 所有经验都存储到 Dt 中,称为回放记忆(replay memory)。
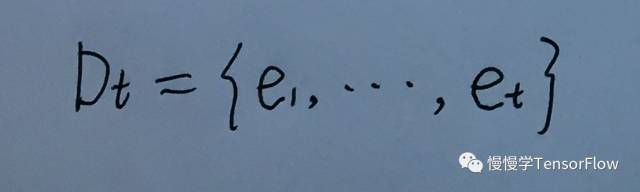
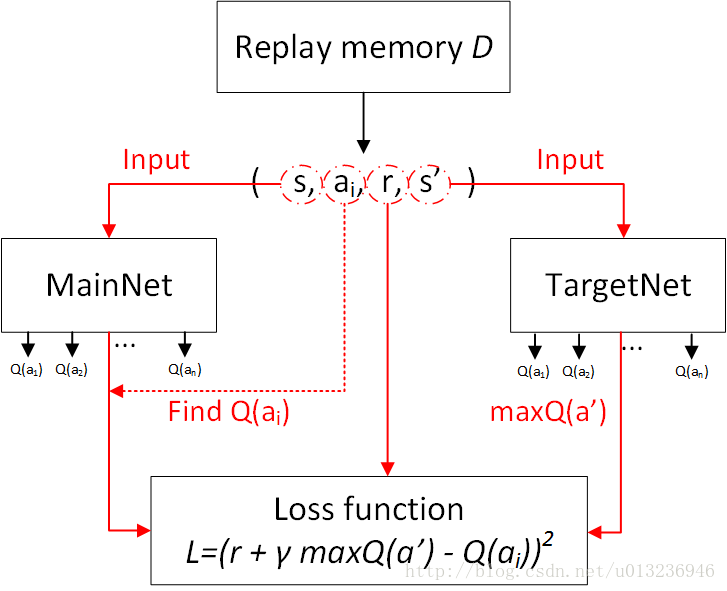
每次迭代,会从 D 中均匀采样得到一组经验,对当前权值使用 SGD 算法进行更新。这样避免了使用相邻经验的过度耦合(游戏中相邻几帧的观测都是非常近似的,容易造成训练发散)。训练 Q 网络时,输入(s, a) 变为序列输入
(s1, a1), (s2, a2), ..., (sn, an)。
主要流程图:

损失函数的构造:
强化学习(3)-----DQN的更多相关文章
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 【强化学习】DQN 算法改进
DQN 算法改进 (一)Dueling DQN Dueling DQN 是一种基于 DQN 的改进算法.主要突破点:利用模型结构将值函数表示成更加细致的形式,这使得模型能够拥有更好的表现.下面给出公式 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- 强化学习(十)Double DQN (DDQN)
在强化学习(九)Deep Q-Learning进阶之Nature DQN中,我们讨论了Nature DQN的算法流程,它通过使用两个相同的神经网络,以解决数据样本和网络训练之前的相关性.但是还是有其他 ...
- 强化学习(十一) Prioritized Replay DQN
在强化学习(十)Double DQN (DDQN)中,我们讲到了DDQN使用两个Q网络,用当前Q网络计算最大Q值对应的动作,用目标Q网络计算这个最大动作对应的目标Q值,进而消除贪婪法带来的偏差.今天我 ...
- 强化学习(九)Deep Q-Learning进阶之Nature DQN
在强化学习(八)价值函数的近似表示与Deep Q-Learning中,我们讲到了Deep Q-Learning(NIPS 2013)的算法和代码,在这个算法基础上,有很多Deep Q-Learning ...
- 强化学习(四)—— DQN系列(DQN, Nature DQN, DDQN, Dueling DQN等)
1 概述 在之前介绍的几种方法,我们对值函数一直有一个很大的限制,那就是它们需要用表格的形式表示.虽说表格形式对于求解有很大的帮助,但它也有自己的缺点.如果问题的状态和行动的空间非常大,使用表格表示难 ...
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 【转载】 强化学习(十一) Prioritized Replay DQN
原文地址: https://www.cnblogs.com/pinard/p/9797695.html ------------------------------------------------ ...
随机推荐
- Django框架详解之template
模板简介 将页面的设计和python的代码分离开会更干净简洁更容易维护.我们可以使用Django的模板系统来实现这种模式 python的模板:HTML代码+模板语法 模板包括在使用时会被值替换掉的变量 ...
- 路飞学城Python-Day24
12.粘包现象 客户端接收的信息指定了的字节,TCP协议没有丢失协议,只是只能接收指定的字节数,于是产生出了粘包现象 服务端接收命令只能接收1024字节,服务端执行命令结果以后传输给客户端,客户端再以 ...
- 10、Latent Relational Metric Learning via Memory-based Attention for Collaborative Ranking-----基于记忆注意的潜在关系度量协同排序
一.摘要: 本文模型 LRML(潜在相关度量学习)是一种新的度量学习方法的推荐.[旨在学习用户和项目之间的相关关系,而不是简单的用户和项目之间的push和pull关系,push和pull主要针对LMN ...
- pythone 学习笔记(粗略)
文档目录 概述 安装 基本语法 数据结构 4.1 数字和字符串类型 4.2 元祖 4.3 列表 4.4 字典 流程语句 5.1 分支结构 5.2 逻辑运算符(if) 5.3 循环 5.3.1 for ...
- cron 和anacron 、日志转储的周期任务
一.cron是开机自动启动的 [root@localhost ~]# chkconfig --list | grep "cron" crond 0:off 1:off 2:on 3 ...
- 浅谈 Qt 布局那些事
Qt 布局那些事是本文介绍的内容,直接进入主题.GridLayout是一个非常强大的布局管理器,它可以实现很多复杂的布局,名字中暗示它将所有控件放置在类似网格的布局中.^__^GridLayout有两 ...
- 简述vuex的数据传递流程
简述vuex的数据传递流程 当组件进行数据修改的时候我们需要调用dispatch来触发actions里面的方法.actions里面的每个方法中都会有一个commit方法,当方法执行的时候会通过comm ...
- MyBatis学习总结(1)——MyBatis快速入门
一.Mybatis介绍 MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以 ...
- 洛谷1417 烹调方案 dp 贪心
洛谷 1417 dp 传送门 挺有趣的一道dp题目,看上去接近于0/1背包,但是考虑到取每个点时间不同会对最后结果产生影响,因此需要进行预处理 对于物品x和物品y,当时间为p时,先加x后加y的收益为 ...
- 解决ORA-28002: 密码7天之后过期办法
https://www.douban.com/group/topic/46177516/ https://yq.aliyun.com/ziliao/42484 http://blog.csdn.net ...