Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统;它提供的功能包括:配置维护、名字服务、分布式同步、组服务等; 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户; ZooKeeper 已经成为 Hadoop 生态系统中的基础组件。
Zookeeper可以选择Apache版本,也可以选择Cloudera版本。
1.下载Zookeeper
这里选择cdh版本的zookeeper-3.4.5-cdh5.10.0.tar.gz,将下载好的安装包上传至bigdata-pro01.kfk.com节点的/opt/softwares目录下。
[kfk@bigdata-pro01 ~]$ cd /opt/softwares/ [kfk@bigdata-pro01 softwares]$ rz [kfk@bigdata-pro01 softwares]$ ls hadoop-2.6..tar.gz jdk-8u60-linux-x64.tar.gz zookeeper-3.4.-cdh5.10.0.tar.gz //选择cdh版本的原因是带源码并且兼容性更佳
2.解压Zookeeper
[kfk@bigdata-pro01 softwares]$ tar -zxf zookeeper-3.4.-cdh5.10.0.tar.gz -C /opt/momdules/ [kfk@bigdata-pro01 softwares]$ cd ../momdules/ [kfk@bigdata-pro01 momdules]$ ls hadoop-2.6. jdk1..0_60 zookeeper-3.4.-cdh5.10.0 [kfk@bigdata-pro01 momdules]$ cd zookeeper-3.4.-cdh5.10.0/ [kfk@bigdata-pro01 zookeeper-3.4.-cdh5.10.0]$ ll total drwxr-xr-x kfk kfk Oct : bin -rw-rw-r-- kfk kfk Jan build.properties -rw-rw-r-- kfk kfk Jan build.xml -rw-rw-r-- kfk kfk Jan CHANGES.txt drwxr-xr-x kfk kfk Oct : cloudera -rw-rw-r-- kfk kfk Jan cloudera-pom.xml drwxr-xr-x kfk kfk Oct : conf drwxr-xr-x kfk kfk Jan contrib drwxr-xr-x kfk kfk Oct : dist-maven drwxr-xr-x kfk kfk Oct : docs -rw-rw-r-- kfk kfk Jan ivysettings.xml -rw-rw-r-- kfk kfk Jan ivy.xml drwxr-xr-x kfk kfk Oct : lib drwxr-xr-x kfk kfk Oct : libexec -rw-rw-r-- kfk kfk Jan LICENSE.txt -rw-rw-r-- kfk kfk Jan NOTICE.txt -rw-rw-r-- kfk kfk Jan README_packaging.txt -rw-rw-r-- kfk kfk Jan README.txt drwxr-xr-x kfk kfk Jan recipes drwxr-xr-x kfk kfk Oct : sbin drwxr-xr-x kfk kfk Jan share drwxr-xr-x kfk kfk Oct : src -rw-rw-r-- kfk kfk Jan zookeeper-3.4.-cdh5.10.0.jar -rw-rw-r-- kfk kfk Jan zookeeper-3.4.-cdh5.10.0.jar.md5 -rw-rw-r-- kfk kfk Jan zookeeper-3.4.-cdh5.10.0.jar.sha1
3.修改配置
1)修改配置文件zoo.cfg
[kfk@bigdata-pro01 zookeeper-3.4.-cdh5.10.0]$ cd conf/ [kfk@bigdata-pro01 conf]$ ls configuration.xsl log4j.properties zoo_sample.cfg
然后用notepad++进行连接。

文件内容解析:
#这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔 tickTime= #配置 Zookeeper 接受客户端初始化连接时最长能忍受多少个心跳时间间隔数。 initLimit= #Leader 与 Follower 之间发送消息,请求和应答时间长度 syncLimit= #数据目录需要提前创建 dataDir=/opt/modules/zookeeper-3.4.-cdh5.10.0/zkData #访问端口号 clientPort= #server.每个节点服务编号=服务器ip地址:集群通信端口:选举端口 server.=bigdata-pro01.kfk.com:: server.=bigdata-pro02.kfk.com:: server.=bigdata-pro03.kfk.com::
新建一个数据目录:
[kfk@bigdata-pro01 zookeeper-3.4.-cdh5.10.0]$ mkdir -p zkData [kfk@bigdata-pro01 zookeeper-3.4.-cdh5.10.0]$ cd zkData/ [kfk@bigdata-pro01 zkData]$ pwd /opt/momdules/zookeeper-3.4.-cdh5.10.0/zkData
然后修改文件中的目录:
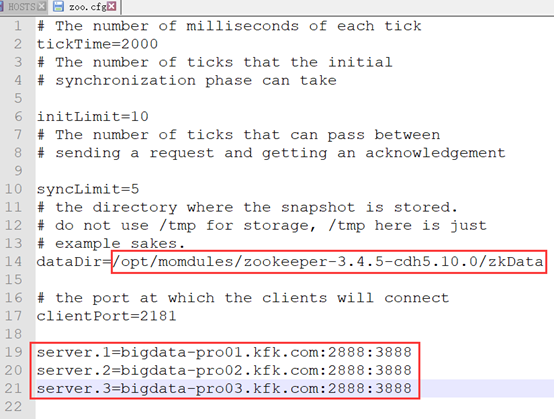
创建myid文件(内容为节点编号1/2/3):

4.分发各个节点
将Zookeeper安装配置分发到其他两个节点,具体操作如下所示:
scp -r zookeeper-3.4.-cdh5.10.0/ bigdata-pro02.kfk.com:/opt/momdules/ scp -r zookeeper-3.4.-cdh5.10.0/ bigdata-pro03.kfk.com:/opt/momdules/
然后修改各个节点的数据存储目录下的myid文件内容为节点对应编号。
#bigdata-pro02.kfk.com节点 vi myid #bigdata-pro03.kfk.com节点 vi myid
5.启动Zookeeper服务
1)各个节点使用如下命令启动Zookeeper服务
bin/zkServer.sh start
2)查看各个节点服务状态
bin/zkServer.sh status

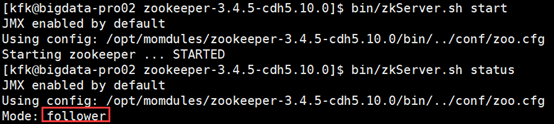
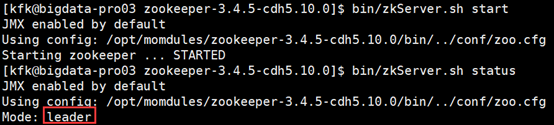
3)查看Zookeeper目录树结构
bin/zkCli.sh


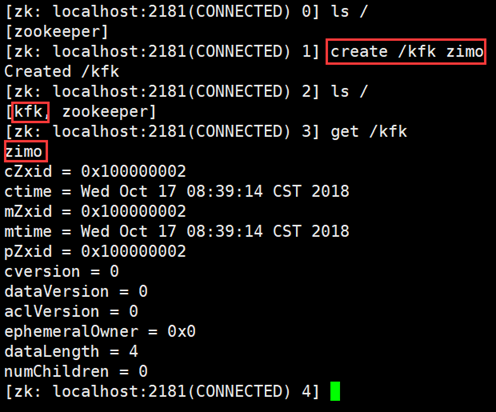
4)关闭各个节点服务
bin/zkServer.sh stop
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!同时也欢迎转载,但必须在博文明显位置标注原文地址,解释权归博主所有!
Zookeeper分布式集群部署的更多相关文章
- ZooKeeper分布式集群部署及问题
ZooKeeper为分布式应用系统提供了高性能服务,在许多常见的集群服务中被广泛使用,最常见的当属HBase集群了,其他的还有Solr集群.Hadoop-2中的HA自己主动故障转移等. 本文主要介绍了 ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- solr 集群(SolrCloud 分布式集群部署步骤)
SolrCloud 分布式集群部署步骤 安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux ...
- 在 Linux 多节点安装配置 Apache Zookeeper 分布式集群
规划: 三台物理服务器就形成了(法定人数).对于高可用性集群,您可以使用高于3的任何奇数.例如,如果设置5台服务器,则集群可以处理两个故障节点等. 物理服务器需要开启的端口 2888 , 3888 和 ...
- SolrCloud 分布式集群部署步骤
https://segmentfault.com/a/1190000000595712 SolrCloud 分布式集群部署步骤 solr solrcloud zookeeper apache-tomc ...
- Zookeeper分布式集群搭建
实验条件:3台安装linux的机子,配置好Java环境. 步骤1:下载并分别解包到每台机子的/home/iHge2k目录下,附上下载地址:http://mirrors.cnnic.cn/apache/ ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
随机推荐
- C++11新标准:decltype关键字
一.decltype意义 有时我们希望从表达式的类型推断出要定义的变量类型,但是不想用该表达式的值初始化变量(如果要初始化就用auto了).为了满足这一需求,C++11新标准引入了decltype类型 ...
- java反射机制的进一步理解
承上一篇. JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法:这种动态获取的信息以及动态调用对象的方法的功能称为java语 ...
- Oracle数据库网闸配置注意事项
1.数据库用户需要的权限 grant select any dictionary to coss; grant alter any procedure to coss; grant create tr ...
- php excel开发01
启用cache
- Oracle中With As 、Group By 语法
比如有下面三张表,用With as .Group By语法解决几个问题; with as : 可以用来创建临时表,作为过度的表: group by: 按照某个字段来分类: 对应字段如下: Sa ...
- 使用Tensorflow object detection API——训练模型(Window10系统)
[数据标注处理] 1.先将下载好的图片训练数据放在models-master/research/images文件夹下,并分别为训练数据和测试数据创建train.test两个文件夹.文件夹目录如下 2. ...
- CF708A Letters Cyclic Shift 模拟
You are given a non-empty string s consisting of lowercase English letters. You have to pick exactly ...
- Qt 学习之路 2(11):布局管理器
Home / Qt 学习之路 2 / Qt 学习之路 2(11):布局管理器 Qt 学习之路 2(11):布局管理器 豆子 2012年9月4日 Qt 学习之路 2 70条评论 所谓 GUI 界 ...
- nginx的使用(启动、重启、关闭)
1. 首先利用配置文件启动nginx. 命令: nginx -c /usr/local/nginx/conf/nginx.conf 重启服务: service nginx restart 2. 快速停 ...
- springmvc 4.x 转json
<bean class="org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter&q ...