Python分页爬取数据的分析
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 向右奔跑
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
对爬虫爬取数据时的分页进行一下总结。分页是爬取到所有数据的关键,一般有这样几种形式: 1、已知记录数,分页大小(pagesize, 一页有多少条记录)
已知总页数(在页面上显示出总页数)
页面上没有总记录数,总页数,但能从分页条中找到总页数
滚动分页,知道总页数
滚动分页,不知道总页数
以上前三种情况比较简单,基本上看一下加载分页数据时的地址栏,或者稍微用Chrome -- network分析一下,就可以了解分页的URL。
一、页面分析,获取分页URL
典型的如豆瓣图书、电影排行榜的分页。
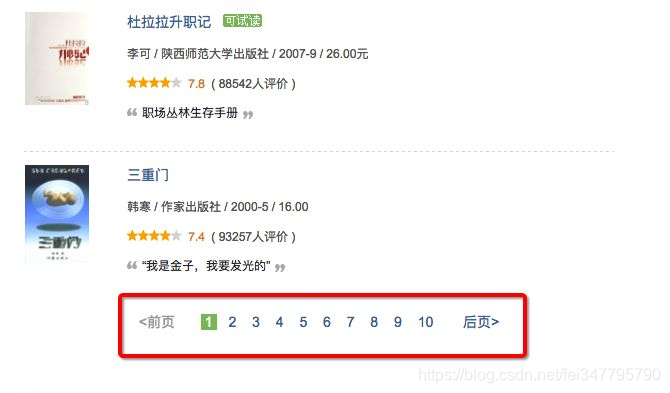
对于像以下这种分页,没有显示总记录数,但从分页条上看到有多少页的,一般的处理方法有两种:一是先把最后一页的页码抓取下来;二是一页一页的访问抓取,直到没有“下一页”。 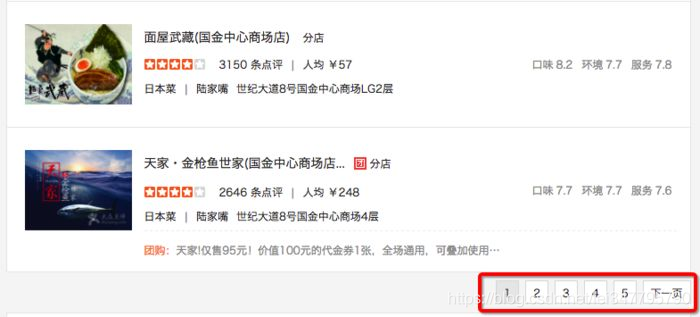
二、用抓包工具,查看分页URL
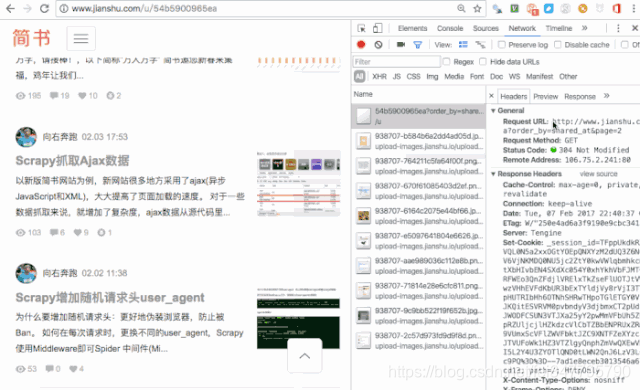
通过抓包工具,获取了分页的URL,再进行总页数的分析,一般是进行计算,如这里,有文章总数量,每页显示的文章数(页大小),就可以计算出总页数。 看一下这个,七日热门文章的分页,比较有意思。这么一长串,是不是比较崩溃。
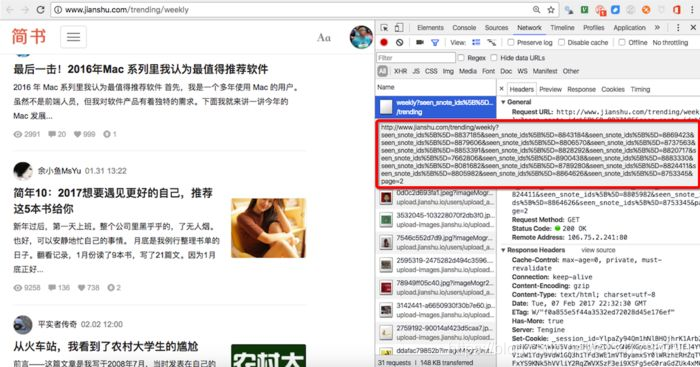
这时候一般要缩短参数,确定关键参数。分页关键的参数是page=2,直接把url减少成这样:

看到就是我们所需要的数据。 再回过头来理解一下,为什么采用了这样一串的URL,可以通过查看response,发现响应的是xml数据(一段网页数据),也就是这里采用了异步加载(AJAX)。
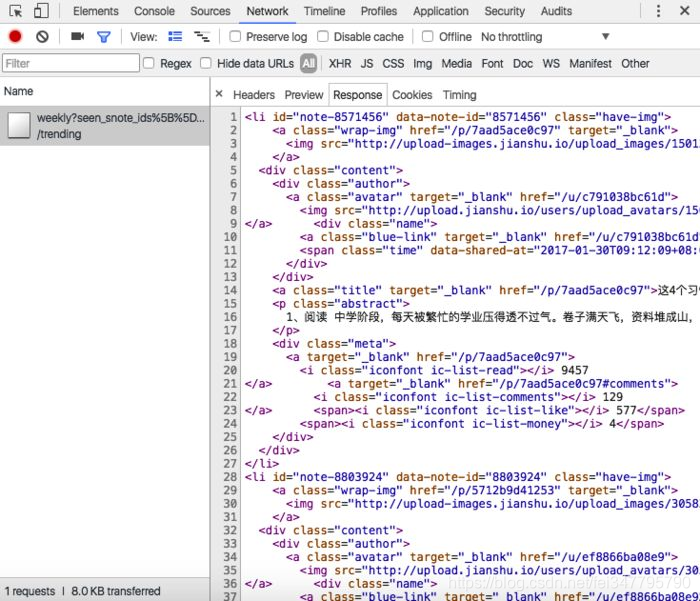
三、抓包分析,需要构造分页URL
这时候,通过抓包分析,还不能获取分页的URL。有时候是抓包到的URL直接放到地址栏也查看不到所要的分页数据,还有时候是分页的URL中有其他参数。
如简书用户“动态”数据分页url,抓包到的是

这里就要了解如何获取max_id这个值。还有一个问题就是要判断是否到了最后一页。 如简书“投稿请求”数据的分页:
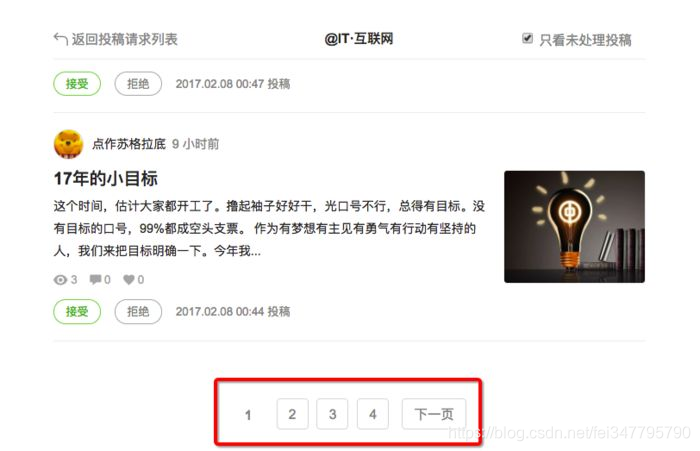
从抓包拿到的分页URL,访问时发现看到的不是我们所要的页面、数据。这时就是根据经验进行分析。基本方法还是结合网页源代码,查看chrome中的response。
Python分页爬取数据的分析的更多相关文章
- 如何分页爬取数据--beautisoup
'''本次爬取讲历史网站'''#!usr/bin/env python#-*- coding:utf-8 _*-"""@author:Hurrican@file: 分页爬 ...
- Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- python 网页爬取数据生成文字云图
1. 需要的三个包: from wordcloud import WordCloud #词云库 import matplotlib.pyplot as plt #数学绘图库 import jieba; ...
- python requests 爬取数据
import requests from lxml import etree import time import pymysql import json headers={ 'User-Agent' ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- Python scrapy爬取带验证码的列表数据
首先所需要的环境:(我用的是Python2的,可以选择python3,具体遇到的问题自行解决,目前我这边几百万的数据量爬取) 环境: Python 2.7.10 Scrapy Scrapy 1.5.0 ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫爬取天气数据并图形化显示
前言 使用python进行网页数据的爬取现在已经很常见了,而对天气数据的爬取更是入门级的新手操作,很多人学习爬虫都从天气开始,本文便是介绍了从中国天气网爬取天气数据,能够实现输入想要查询的城市,返回该 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
随机推荐
- oracle 中 insert select 和 select insert 配合使用
Insert Into select 与 Select Into 哪个更快? 在平常数据库操作的时候,我们有时候会遇到表之间数据复制的情况,可能会用到INSERT INTO SELECT 或者 SEL ...
- Luogu P1583 魔法照片
题目描述 一共有n(n≤20000)个人(以1--n编号)向佳佳要照片,而佳佳只能把照片给其中的k个人.佳佳按照与他们的关系好坏的程度给每个人赋予了一个初始权值W[i].然后将初始权值从大到小进行排序 ...
- Cypress安装使用(E2E测试框架)
一.简介 Cypress是为现代网络打造的下一代前端测试工具,解决了开发人员和QA工程师在测试现代应用程序时面临的关键难点问题. Cypress包含免费的.开源的.可本地安装的Test Runner ...
- 传统jdbc存在的问题总结
1.数据库连接创建.释放频繁造成系统资源浪费,影响系统性能,可使用数据库连接池解决此问题. 2.sql语句中在代码中硬编码,代码不易维护,sql变动需要改变java代码. 3.使用preparedSt ...
- SpringCloud的入门学习之概念理解、Hystrix断路器
1.分布式系统面临的问题,复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败. 2.什么是服务雪崩? 答:多个微服务之间调用的时候,假设微服务A调用微服务B和微服务 ...
- C# webclient progresschanged downlodfileCompleted
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- 应届生offer指南
通用技术 1.一般公司对应届生都要考察编程能力,所以应聘之前先刷刷题.我做面试官出的编程题两年没有变过.就是这道
- Java工程师学习指南
java学习指南-四个部分:分别是入门篇,初级篇,中级篇,高级篇 第一步是打好Java基础,掌握Java核心技术, ...
- View和ViewGroup
1.继承关系 2.组合关系 3.View 的绘制流程 3.1.创建R.attrs.styleable,申明需要用到的属性值,在使用时可以根据属性进行定义 3.2.extends View ,依次 ...
- MSSQL 删除重复数据
--删除重复数据,无标识列情况 if object_id(N'test',N'U') is not null drop table test go create table test( id INT, ...