Python分页爬取数据的分析
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 向右奔跑
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
对爬虫爬取数据时的分页进行一下总结。分页是爬取到所有数据的关键,一般有这样几种形式: 1、已知记录数,分页大小(pagesize, 一页有多少条记录)
已知总页数(在页面上显示出总页数)
页面上没有总记录数,总页数,但能从分页条中找到总页数
滚动分页,知道总页数
滚动分页,不知道总页数
以上前三种情况比较简单,基本上看一下加载分页数据时的地址栏,或者稍微用Chrome -- network分析一下,就可以了解分页的URL。
一、页面分析,获取分页URL
典型的如豆瓣图书、电影排行榜的分页。
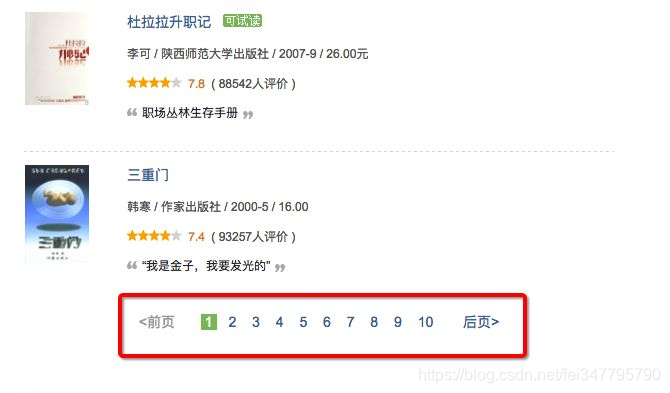
对于像以下这种分页,没有显示总记录数,但从分页条上看到有多少页的,一般的处理方法有两种:一是先把最后一页的页码抓取下来;二是一页一页的访问抓取,直到没有“下一页”。 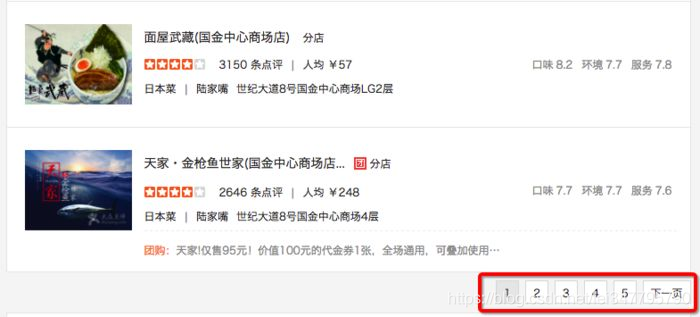
二、用抓包工具,查看分页URL
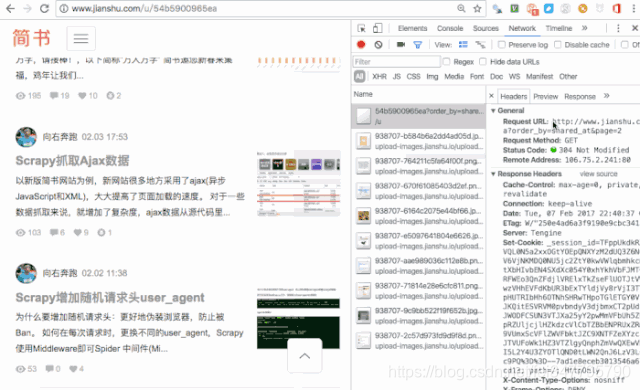
通过抓包工具,获取了分页的URL,再进行总页数的分析,一般是进行计算,如这里,有文章总数量,每页显示的文章数(页大小),就可以计算出总页数。 看一下这个,七日热门文章的分页,比较有意思。这么一长串,是不是比较崩溃。
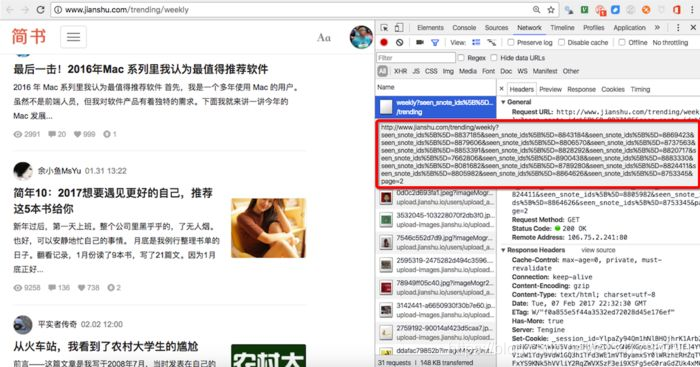
这时候一般要缩短参数,确定关键参数。分页关键的参数是page=2,直接把url减少成这样:

看到就是我们所需要的数据。 再回过头来理解一下,为什么采用了这样一串的URL,可以通过查看response,发现响应的是xml数据(一段网页数据),也就是这里采用了异步加载(AJAX)。
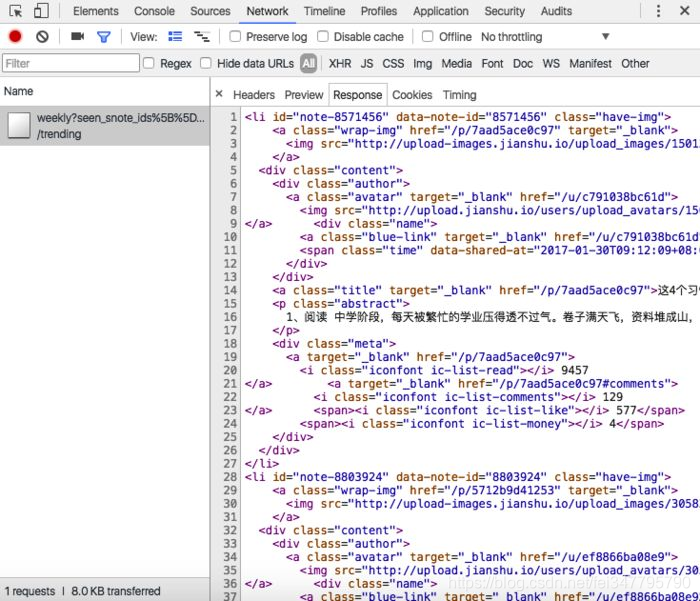
三、抓包分析,需要构造分页URL
这时候,通过抓包分析,还不能获取分页的URL。有时候是抓包到的URL直接放到地址栏也查看不到所要的分页数据,还有时候是分页的URL中有其他参数。
如简书用户“动态”数据分页url,抓包到的是

这里就要了解如何获取max_id这个值。还有一个问题就是要判断是否到了最后一页。 如简书“投稿请求”数据的分页:
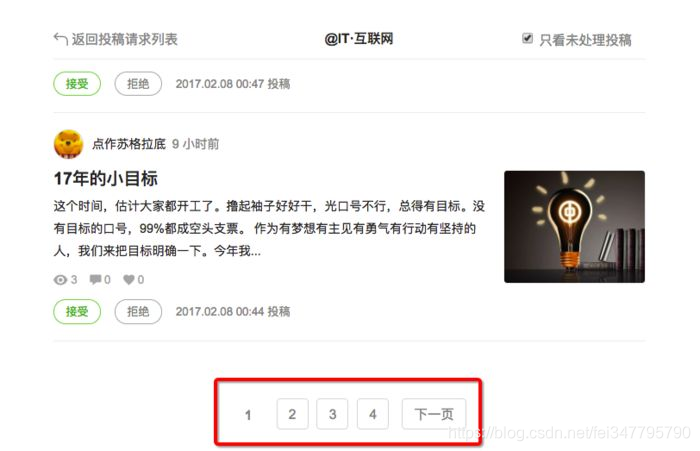
从抓包拿到的分页URL,访问时发现看到的不是我们所要的页面、数据。这时就是根据经验进行分析。基本方法还是结合网页源代码,查看chrome中的response。
Python分页爬取数据的分析的更多相关文章
- 如何分页爬取数据--beautisoup
'''本次爬取讲历史网站'''#!usr/bin/env python#-*- coding:utf-8 _*-"""@author:Hurrican@file: 分页爬 ...
- Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- python 网页爬取数据生成文字云图
1. 需要的三个包: from wordcloud import WordCloud #词云库 import matplotlib.pyplot as plt #数学绘图库 import jieba; ...
- python requests 爬取数据
import requests from lxml import etree import time import pymysql import json headers={ 'User-Agent' ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- Python scrapy爬取带验证码的列表数据
首先所需要的环境:(我用的是Python2的,可以选择python3,具体遇到的问题自行解决,目前我这边几百万的数据量爬取) 环境: Python 2.7.10 Scrapy Scrapy 1.5.0 ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫爬取天气数据并图形化显示
前言 使用python进行网页数据的爬取现在已经很常见了,而对天气数据的爬取更是入门级的新手操作,很多人学习爬虫都从天气开始,本文便是介绍了从中国天气网爬取天气数据,能够实现输入想要查询的城市,返回该 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
随机推荐
- 易优CMS:channel的基础用法
[基础用法] 名称:channel 功能:易优常用标记,可以循环嵌套标签.通常用于网站导航以获取站点栏目信息,方便网站会员分类浏览整站信息 语法: {eyou:channel type='top' r ...
- Flutter竟然发布了1.5版本!!!!
2018年2月,Flutter推出了第一个Beta版本,在2018年12月5日,Flutter1.0版本发布,当时用了用觉得这个东西非常好用,对于当时被RN搞的头皮发麻的我来说简直是看到了曙光.而在昨 ...
- Docker 系列之 基础入门
安装 Docker Windows 10 专业版以上版本 Docker for Windows Installer 在安装前,需要确保目标机器已经开启了硬件虚拟化和 HyperV :在安装的过程中建议 ...
- 10分钟彻底理解Redis的持久化机制:RDB和AOF
作者:张君鸿 juejin.im/post/5d09a9ff51882577eb133aa9 什么是Redis持久化? Redis作为一个键值对内存数据库(NoSQL),数据都存储在内存当中,在处理客 ...
- apt-get原理
apt-get 而这个步骤全要用户亲力亲为可能又有些麻烦,懒是科技发展的重要推动力.所以软件厂商自己编译好了很多二进制文件,只要系统和环境对应,下载之后就能直接安装. 但是如果下载了很多软件我想要管理 ...
- 在Asp.Net或.Net Core中配置使用MarkDown富文本编辑器有开源模板代码(代码是.net core3.0版本)
研究如何使用Markdown你们可能要花好几天才能搞定,但是看我的文章或者下载了源码,你搞定一般在10分钟之内.我先给各位介绍下它: Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯 ...
- JMeter资源监控插件PerfMon的使用
1.插件下载 首先下载jmeter的插件管理工具,下载地址:jmeter-plugins.org 如英文说明,把下载后的jar包放到jmeter的安装目录lib/ext文件夹下,重启jmeter,就会 ...
- 教你两招用纯CSS写Tab切换
说到Tab切换,你可能首先想到的就是使用jQuery,短短几行代码就可以轻松搞定一个Tab切换. 而今天所要分享的,是使用 0 行JS代码来实现Tab切换! 具体效果如下: Tab切换 方法一:模 ...
- 【论文阅读】Second-order Attention Network for Single Image Super-Resolution
概要 近年来,深度卷积神经网络(CNNs)在单一图像超分辨率(SISR)中进行了广泛的探索,并获得了卓越的性能.但是,大多数现有的基于CNN的SISR方法主要聚焦于更宽或更深的体系结构设计上,而忽略了 ...
- ffmpeg-python 任意提取视频帧
▶ 环境准备 1.安装 FFmpeg 音/视频工具 FFmpeg 简易安装文档 2.安装 ffmpeg-python pip3 install ffmpeg-python 3.[可选]安装 openc ...