【十大经典数据挖掘算法】Apriori
【十大经典数据挖掘算法】系列
1. 关联分析
关联分析是一类非常有用的数据挖掘方法,能从数据中挖掘出潜在的关联关系。比如,在著名的购物篮事务(market basket transactions)问题中,
| TID | Iterms |
|---|---|
| 1 | {Bread, Milk} |
| 2 | {Bread, Diapers, Beer, Eggs} |
| 3 | {Milk, Diapers, Beer, Cola} |
| 4 | {Bread, Milk, Diapers, Beer} |
| 5 | {Bread, Milk, Beer, Cola} |
关联分析则被用来找出此类规则:顾客在买了某种商品时也会买另一种商品。在上述例子中,大部分都知道关联规则:{Diapers} → {Beer};即顾客在买完尿布之后通常会买啤酒。后来通过调查分析,原来妻子嘱咐丈夫给孩子买尿布时,丈夫在买完尿布后通常会买自己喜欢的啤酒。但是,如何衡量这种关联规则是否靠谱呢?下面给出了度量标准。
支持度与置信度
关联规则可以描述成:项集 → 项集。项集\(X\)出现的事务次数(亦称为support count)定义为:
\[
\sigma (X) = |t_i|X \subseteq t_i, t_i \in T|
\]
其中,\(t_i\)表示某个事务(TID),\(T\)表示事务的集合。关联规则\(X \longrightarrow Y\)的支持度(support):
\[
s(X \longrightarrow Y) = \frac{\sigma (X \cup Y)}{|T|}
\]
支持度刻画了项集\(X \cup Y\)的出现频次。置信度(confidence)定义如下:
\[
s(X \longrightarrow Y) = \frac{\sigma (X \cup Y)}{\sigma (X)}
\]
对概率论稍有了解的人,应该看出来:置信度可理解为条件概率\(p(Y|X)\),度量在已知事务中包含了\(X\)时包含\(Y\)的概率。
对于靠谱的关联规则,其支持度与置信度均应大于设定的阈值。那么,关联分析问题即等价于:对给定的支持度阈值min_sup、置信度阈值min_conf,找出所有的满足下列条件的关联规则:
\begin{aligned}
& 支持度 >= min\_sup \cr
& 置信度 >= min\_conf \cr
\end{aligned}
把支持度大于阈值的项集称为频繁项集(frequent itemset)。因此,关联规则分析可分为下列两个步骤:
- 生成频繁项集\(F=X \cup Y\);
- 在频繁项集\(F\)中,找出所有置信度大于最小置信度的关联规则\(X \longrightarrow Y\)。
暴力方法
若(对于所有事务集合)项的个数为\(d\),则所有关联规则的数量:
\[
\begin{aligned}
& \sum_{i}^d C_d^i \sum_{j}^{d-i} C_{d-i}^j \cr
= & \sum_{i}^d C_d^i ( 2^{d-i} -1) \cr
= & \sum_{i}^d C_d^i * 2^{d-i} - 2^d + 1 \cr
= & (3^d - 2^d) - 2^d +1 \cr
= & 3^d - 2^{d+1} + 1
\end{aligned}
\]
如果采用暴力方法,穷举所有的关联规则,找出符合要求的规则,其时间复杂度将达到指数级。因此,我们需要找出复杂度更低的算法用于关联分析。
2. Apriori算法
Agrawal与Srikant提出Apriori算法,用于做快速的关联规则分析。
频繁项集生成
根据支持度的定义,得到如下的先验定理:
- 定理1:如果一个项集是频繁的,那么其所有的子集(subsets)也一定是频繁的。
这个比较容易证明,因为某项集的子集的支持度一定不小于该项集。
- 定理2:如果一个项集是非频繁的,那么其所有的超集(supersets)也一定是非频繁的。
定理2是上一条定理的逆反定理。根据定理2,可以对项集树进行如下剪枝:

项集树共有项集数:\(\sum_{k=1}^d k \times C_{d}^k = d \cdot 2^{d-1}\)。显然,用穷举的办法会导致计算复杂度太高。对于大小为\(k-1\)的频繁项集\(F_{k-1}\),如何计算大小为\(k\)的频繁项集\(F_k\)呢?Apriori算法给出了两种策略:
\(F_k = F_{k-1} \times F_1\)方法。之所以没有选择\(F_{k-1}\)与(所有)1项集生成\(F_k\),是因为为了满足定理2。下图给出由频繁项集\(F_2\)与\(F_1\)生成候选项集\(C_3\):

\(F_k = F_{k-1} \times F_{k-1}\)方法。选择前\(k-2\)项均相同的\(f_{k-1}\)进行合并,生成\(F_{k-1}\)。当然,\(F_{k-1}\)的所有\(f_{k-1}\)都是有序排列的。之所以要求前\(k-2\)项均相同,是因为为了确保\(F_k\)的\(k-2\)项都是频繁的。下图给出由两个频繁项集\(F_2\)生成候选项集\(C_3\):

生成频繁项集\(F_k\)的算法如下:

关联规则生成
关联规则是由频繁项集生成的,即对于\(F_k\),找出项集\(h_m\),使得规则\(f_k-h_m \longrightarrow h_m\)的置信度大于置信度阈值。同样地,根据置信度定义得到如下定理:
定理3:如果规则\(X \longrightarrow Y-X\)不满足置信度阈值,则对于\(X\)的子集\(X'\),规则\(X' \longrightarrow Y-X'\)也不满足置信度阈值。
根据定理3,可对规则树进行如下剪枝:
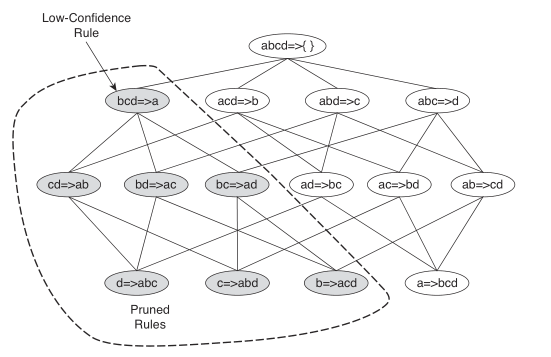
关联规则的生成算法如下:

3. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
【十大经典数据挖掘算法】Apriori的更多相关文章
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
- 【十大经典数据挖掘算法】AdaBoost
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 集成学习 集成学习(ensem ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】k-means
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
- 【十大经典数据挖掘算法】kNN
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 顶级数据挖掘会议ICDM ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
随机推荐
- c#控制打印机杂项
因项目中需要用到控制打印机的相关信息,此贴将网络寻找的资料做了些整理 1. C# 如何设置系统的默认打印机 using System.Runtime.InteropServices; [DllIm ...
- 三种观察者模式的C#实现
系列主题:基于消息的软件架构模型演变 说起观察者模式,估计在园子里能搜出一堆来.所以写这篇博客的目的有两点: 观察者模式是写松耦合代码的必备模式,重要性不言而喻,抛开代码层面,许多组件都采用了Publ ...
- HTML5特性速记图
今天推荐大家一张HTML5特性速记图,供大家平时查阅,也可以打印放在电脑旁帮助速记.速查.此图笔者收集于网络图片.
- 防刷票机制研究和.NET HttpRequest Proxy
最近应朋友之约 测试他做的投票网站 防刷票机制能力如何,下面有一些心得和体会. 朋友网站用PHP写的,走的是HttpRequest,他一开始认为IP认证应该就差不多了.但说实话这种很low,手动更换代 ...
- C语言 · 最小乘积(基本型)
问题描述 给两组数,各n个. 请调整每组数的排列顺序,使得两组数据相同下标元素对应相乘,然后相加的和最小.要求程序输出这个最小值. 例如两组数分别为:1 3 -5和-2 4 1 那么对应乘积取和的最小 ...
- Linux压缩命令
Linux常见的压缩格式有.zip..gz..bz2..tar..tar.gz..tar.bz2:常用的压缩命令有zip.tar.这里列举了各压缩命令的使用示例.更多的用法请使用命令 --help查阅 ...
- 自定义模拟一个Spring IOC容器
一.模拟一个IOC容器: 介绍:现在,我们准备使用一个java project来模拟一个spring的IOC容器创建对象的方法,也就是不使用spring的jar自动帮助我们创建对象,而是通过自己手动书 ...
- 【已解决】WinPhone模拟器报错:模拟器没法确定来宾虚拟机通信的主机ID地址。某些功能已被禁用
先看警告 再看错误信息 计算机管理打不开就==>Win+R ==>compmgmt.msc 发现,dnt在管理员权限组里面,也在Hyper-V权限组里面 看看Hyper-V的驱动有木有被禁 ...
- 《JS设计模式笔记》 4,桥接模式
//桥接模式的作用在于将实现部分和抽象部分分离开来,以便两者可以独立的变化. var singleton=function(fn){ var result; return function(){ re ...
- Rust初步(五):Rust与C#性能比较
我学习Rust的目的并不是说期望用它来取代掉现有的开发平台或语言.相反,我认为当前绝大部分研发团队,都不可能只用一个平台或者一个语言. 当组织增长,他们越来越依赖大量的编程语言.不同的编程语言有不同的 ...