图数据库PageRank算法
目录:
定义:
假设对象A具有指向它的对象T1 ... Tn。参数d是阻尼系数,取值范围在0和1之间,通常将d设置为0.85。C(A)被定义为从对象A出去的连接数。
对象A的PageRank计算公式如下:
PR(A)=(−d)+d(PR(T1)/C(T1)+...+PR(Tn)/C(Tn))
当一个节点只有输出,没有输入的时候,因为d一般设置为0.85,所以:
PR(A)=(-d)+ d *()= 0.15
计算原理:
每个对象的PR取决于指向它的对象的PR。在指向一个对象的所有对象都计算出了PR,才能够计算出该页面的PR值。
当所有对象形成闭环时,PR(A)可以使用简单的迭代算法计算,并且对应于web的规范化链接矩阵的主特征向量。
基本上,每次计算都会对各对象的最终值进行更接近的估计。通过对这些对象进行大量重复的计算,直到结果变化很小为止。
示例1:
每个页面都有一个输出链接(输出计数为1,即C(A)= 1,C(B)= 1)

假设A的PR(A)初始值为1
d = 0.85 //默认值 PR(A)=( - d)+ d(PR(B)/ ) PR(B)=( - d)+ d(PR(A)/ ) //即 PR(A)= 0.15 + 0.85 * = PR(B)= 0.15 + 0.85 * =
假设A的PR(A)初始值为0
PR(A)= 0.15 + 0.85 * = 0.15 PR(B)= 0.15 + 0.85 * 0.15 = 0.2775 //完成一次迭代,继续第二次迭代 PR(A)= 0.15 + 0.85 * 0.2775 = 0.385875 PR(B)= 0.15 + 0.85 * 0.385875 = 0.47799375 //第三次迭代 PR(A)= 0.15 + 0.85 * 0.47799375 = 0.5562946875 PR(B)= 0.15 + 0.85 * 0.5562946875 = 0.622850484375 //结果数值不断上升,但当达到1.0时,停止增加。
假设A的PR(A)初始值为40,B的PR(B)初始值为40
//初始值
PR(A)=
PR(B)= //第一次迭代 PR(A)= 0.15 + 0.85 * = 34.25 PR(B)= 0.15 + 0.85 * 0.385875 = 29.1775 //第二次迭代 PR(A)= 0.15 + 0.85 * 29.1775 = 24.950875 PR(B)= 0.15 + 0.85 * 24.950875 = 21.35824375 //结果数值不断下降,但当达到1.0时,停止下降。
性质:
当没有节点只进不出时,PageRank计算结果符合“ 归一化概率分布 ”,所有节点的PageRank平均值为1.0。
示例2:

该实例不满足只进不出条件,第三列的节点只有输入,没有输出,所以PR的平均值不等于1.0
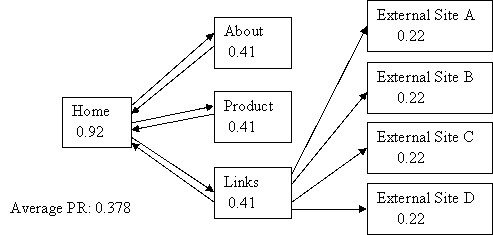
参考资料:
http://www.cs.princeton.edu/~chazelle/courses/BIB/pagerank.htm
图数据库PageRank算法的更多相关文章
- 数值分析:幂迭代和PageRank算法
1. 幂迭代算法(简称幂法) (1) 占优特征值和占优特征向量 已知方阵\(\bm{A} \in \R^{n \times n}\), \(\bm{A}\)的占优特征值是量级比\(\bm{A}\)所有 ...
- 数值分析:幂迭代和PageRank算法(Numpy实现)
1. 幂迭代算法(简称幂法) (1) 占优特征值和占优特征向量 已知方阵\(\bm{A} \in \R^{n \times n}\), \(\bm{A}\)的占优特征值是比\(\bm{A}\)的其他特 ...
- 图数据库-Neo4j-常用算法
本次主要学习图数据库中常用到的一些算法,以及如何在Neo4j中调用,所以这一篇偏实战,每个算法的原理就简单的提一下. 1. 图数据库中常用的算法 PathFinding & Search 一般 ...
- MapReduce实现PageRank算法(稀疏图法)
前言 本文用Python编写代码,并通过hadoop streaming框架运行. 算法思想 下图是一个网络: 考虑转移矩阵是一个很多的稀疏矩阵,我们可以用稀疏矩阵的形式表示,我们把web图中的每一个 ...
- pagerank算法在数学模型中的运用(有向无环图中节点排序)
一.模型介绍 pagerank算法主要是根据网页中被链接数用来给网页进行重要性排名. 1.1模型解释 模型核心: a. 如果多个网页指向某个网页A,则网页A的排名较高. b. 如果排名高A的网页指向某 ...
- 图数据库|基于 Nebula Graph 的 BetweennessCentrality 算法
本文首发于 Nebula Graph Community 公众号 在图论中,介数(Betweenness)反应节点在整个网络中的作用和影响力.而本文主要介绍如何基于 Nebula Graph 图数据 ...
- 同步图计算实现pageRank算法
pageRank算法是Google对网页重要性的打分算法. 一个用户浏览一个网页时,有85%的可能性点击网页中的超链接,有15%的可能性转向任意的网页.pageRank算法就是模拟这种行为. Rv:定 ...
- 张洋:浅析PageRank算法
本文引自http://blog.jobbole.com/23286/ 很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看 ...
- 浅析PageRank算法
很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看了一些相关的资料(PS:在动车上看看书真是一种享受),趁热打铁,将所看 ...
随机推荐
- [Next] 初见next.js
next 简介 Next.js 是一个轻量级的 React 服务端渲染应用框架 next 特点 默认情况下由服务器呈现 自动代码拆分可加快页面加载速度 简单的客户端路由(基于页面) 基于 Webpac ...
- Spring boot 梳理 - WebMvcConfigurer接口 使用案例
转:https://yq.aliyun.com/articles/617307 SpringBoot 确实为我们做了很多事情, 但有时候我们想要自己定义一些Handler,Interceptor,Vi ...
- Android开发——Toolbar常用设置
本篇笔记用来记录常用的Toolbar设置,如Toolbar颜色设置,显示返回按钮,显示右边三个点按钮 之前Android 使用的ActionBar,Android5.0开始,谷歌官方推荐使用Toolb ...
- WebGL简易教程(六):第一个三维示例(使用模型视图投影变换)
目录 1. 概述 2. 示例:绘制多个三角形 2.1. Triangle_MVPMatrix.html 2.2. Triangle_MVPMatrix.js 2.2.1. 数据加入Z值 2.2.2. ...
- Kubernetes 系列(一):本地k8s集群搭建
我们需要做以下工作: (1)安装VMware,运行CentOs系统,一个做master,一个做node. (2)安装K8s. (3)安装docker和部分镜像会需要访问外网,所以你需要做些网络方面的准 ...
- Nullable Reference Types 可空引用类型
在写C#代码的时候,你可能经常会遇到这个错误: 但如果想避免NullReferenceException的发生,确实需要做很多麻烦的工作. 可空引用类型 Null Reference Type 所以, ...
- (4)一起来看下mybatis框架的缓存原理吧
本文是作者原创,版权归作者所有.若要转载,请注明出处.本文只贴我觉得比较重要的源码,其他不重要非关键的就不贴了 我们知道.使用缓存可以更快的获取数据,避免频繁直接查询数据库,节省资源. MyBatis ...
- 【Autofac打标签模式】AutoConfiguration和Bean
[ Autofac打标签模式]开源DI框架扩展地址: https://github.com/yuzd/Autofac.Annotation/wiki *:first-child { margin-to ...
- 使用foreach语句对数组成员进行遍历
/*** 使用foreach语句对数组成员进行遍历* **/ public class ForeachDemo { public static void main(String[] args) { i ...
- 【干货系列之萌新知识点】python与变量和运算符
一.注释 注释一行:# 为注释符 注释多行:'或者"为注释符 二.print输出 print()函数,作用是打印一些信息语屏幕上. 例如:print("hello world!&q ...