Semi-supervised learning for Text Classification by Layer Partitioning
本文是arxiv上一篇较短的文章,之所以看是因为其标题中半监督和文本分类吸引了我。不过看完之后觉得所做的工作比较少,但想法其实也挺不错。
大多数的半监督方法都选择将小扰动施加到输入向量或其表示中,这种方式在计算机视觉上比较成功,但对于离散型的文本却不适合。为了将这个方法应用于文本输入,本文将神经网络\(M\)进行拆分:\(M=U \circ F\)。其中\(F\)被冻结(freeze),用于特征提取和基于droput添加噪声,\(U\)则可以是任意的半监督算法。同时,论文还对\(F\)逐渐解冻(unfreeze),避免预训练模型的灾难性遗忘。
引言
大多数半监督算法依赖于一致性或者平滑约束,强制模型对输入及加了轻微扰动的输入的预测一致。在CV问题中,图片可以表示成稠密连续向量,然而在文本分类任务中,每个单词被表示成one-hot形式,这种方法不合适。即使使用word embedding,文本的潜在表示还是离散的。并且,给每个单词独立加入扰动的话,会导致扰动后的单词没有实际意义。
针对上述问题,本文提出将一个神经网络分解为两部分,即\(M = U \circ F\)。其中\(F\)作为特征编码器和扰动函数(比如可以使用语言模型),\(U\)可以是任意的半监督算法。\(F\)通常是领域无关的,而\(U\)则是领域特定的。这也是论文题目叫做layer partitionning的原因。
方法
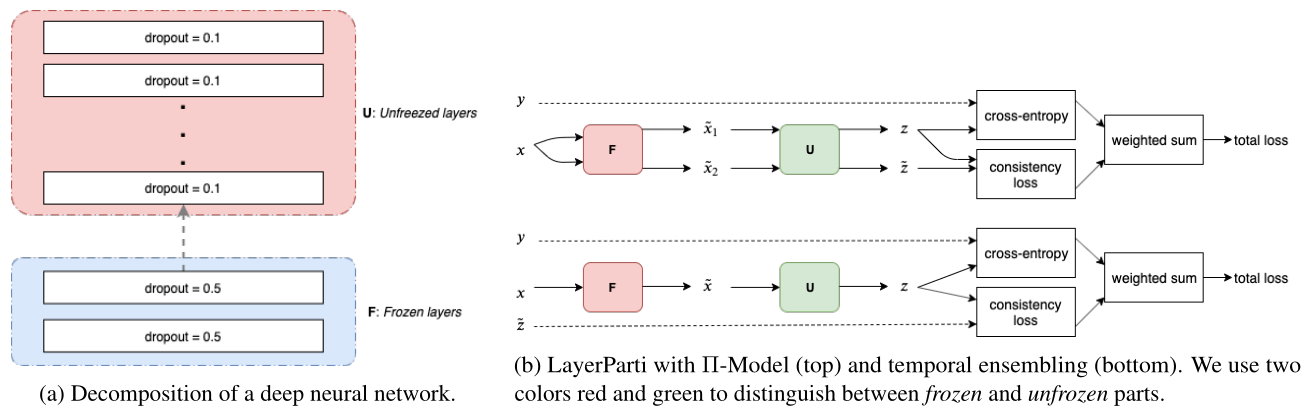
上图左边部分就是整个模型的示意图,论文使用ULMFiT作为\(F\)特征编码器,将每个输入转化到连续的向量空间,然后再由\(U\)(\(\prod\)模型,Temporal Emsebling等)进行学习。
同时\(F\)还用于给输入施加噪声。但作者没有使用通用的\(\tilde{x} \leftarrow x + \epsilon\)这种方式,而是使用dropout作为噪声。作者认为\(F\)在通用领域预训练,比通用的方式包含更多的文本信息,对到此加入噪声使happy变成sad这种方式可能会完全改变文本性质。
接下来就是如何训练\(U\)的事情了,论文列举了两个模型,分别是\(\prod\)-Model和temporal ensembling model。它们都是半监督学习算法,示意图如上图右边部分。
训练到一定程度,作者提出逐渐解冻\(F\)中的网络,这是因为此时\(U\)已经在\(\{F(x)\}\)上训练饱和,可以让\(F\)同样也学到一些任务相关的特定特征了。
实验
论文使用Internet Movie Dataset(IMDb)和TREC-6数据集,主要是进行情感分类。
Semi-supervised learning for Text Classification by Layer Partitioning的更多相关文章
- 论文翻译——Character-level Convolutional Networks for Text Classification
论文地址 Abstract Open-text semantic parsers are designed to interpret any statement in natural language ...
- A brief introduction to weakly supervised learning(简要介绍弱监督学习)
by 南大周志华 摘要 监督学习技术通过学习大量训练数据来构建预测模型,其中每个训练样本都有其对应的真值输出.尽管现有的技术已经取得了巨大的成功,但值得注意的是,由于数据标注过程的高成本,很多任务很难 ...
- [Tensorflow] RNN - 04. Work with CNN for Text Classification
Ref: Combining CNN and RNN for spoken language identification Ref: Convolutional Methods for Text [1 ...
- #论文阅读# Universial language model fine-tuing for text classification
论文链接:https://aclweb.org/anthology/P18-1031 对文章内容的总结 文章研究了一些在general corous上pretrain LM,然后把得到的model t ...
- Text Classification
Text Classification For purpose of word embedding extrinsic evaluation, especially downstream task. ...
- Machine Learning Algorithms Study Notes(2)--Supervised Learning
Machine Learning Algorithms Study Notes 高雪松 @雪松Cedro Microsoft MVP 本系列文章是Andrew Ng 在斯坦福的机器学习课程 CS 22 ...
- 图像分类之特征学习ECCV-2010 Tutorial: Feature Learning for Image Classification
ECCV-2010 Tutorial: Feature Learning for Image Classification Organizers Kai Yu (NEC Laboratories Am ...
- Supervised Learning and Unsupervised Learning
Supervised Learning In supervised learning, we are given a data set and already know what our correc ...
- [转] Implementing a CNN for Text Classification in TensorFlow
Github上的一个开源项目,文档讲得极清晰 Github - https://github.com/dennybritz/cnn-text-classification-tf 原文- http:// ...
随机推荐
- KillTimer不能放在析构函数,可以放在DestroyWindow函数里
转自 https://www.cnblogs.com/huking/archive/2009/11/27/1612201.html KillTimer&析构函数 析构函数中不能用KillTim ...
- SpringData 简单的条件查询
今天在写springdata条件查询时,JpaRepository的findOne方法,不知道是因为版本的原因还是其他原因,总是查询不出来数据 //springdata jpa版本为1.5.15,配置 ...
- Java IO管道流
import java.io.IOException; import java.io.PipedInputStream; import java.io.PipedOutputStream; publi ...
- ZR#990
ZR#990 解法: 首先,一个 $ k $ 进制的数的末尾 $ 0 $ 的个数可以这么判断 while(x) { x /= k; cnt++;//cnt为0的个数 } 因为这道题的 $ 0 $ 的个 ...
- 2、ES6结构赋值和模板字符串
ES6允许按照一定的模式,从数组和对象中提取值,这被称为结构,即解开数据的结构 1.数组的解构赋值 let [a,b] = [1,2] let [a,b,c=100] = [1,2] //c的默认值为 ...
- Linux中的定时自动执行功能(at,crontab)
Linux中的定时自动执行功能(at,crontab) 概念 在Linux系统中,提供了两种提前对工作进行安排的方式 at 只执行一次 crontab 周期性重复执行 通过对这两个工具的应用可以让我们 ...
- 用样式表美化QTabwidget外观
没有仔细看是否正确,先保存到这里,以后研究一下 一.参考文章:http://bbs.csdn.net/topics/390632657?page=1 setStyleSheet("QTabW ...
- element-ui表格显示html格式
<el-table-column type="String" label="内容" prop="tpl" width="58 ...
- 模型稳定性指标—PSI
由于模型是以特定时期的样本所开发的,此模型是否适用于开发样本之外的族群,必须经过稳定性测试才能得知.稳定度指标(population stability index ,PSI)可衡量测试样本及模型开发 ...
- Tomcat 8.5.x RedisSessionManager show:Caused by: java.lang.NoSuchMethodError: com.crimsonhexagon.rsm.
Caused by: java.lang.NoSuchMethodError: com.crimsonhexagon.rsm.RedisSessionManager.getMaxInactiveInt ...