Flink+Kafka整合的实例
Flink+Kafka整合实例
1.使用工具Intellig IDEA新建一个maven项目,为项目命名为kafka01。
2.我的pom.xml文件配置如下。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.hrb.lhr</groupId>
<artifactId>kafka01</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.1.4</flink.version>
<slf4j.version>1.7.7</slf4j.version>
<log4j.version>1.2.17</log4j.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- explicitly add a standard loggin framework, as Flink does not (in the future) have
a hard dependency on one specific framework by default -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.9_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies> </project>
3.在项目的目录/src/main/java在创建两个Java类,分别命名为KafkaDemo和CustomWatermarkEmitter,代码如下所示。
import java.util.Properties;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer09;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema; public class KafkaDeme { public static void main(String[] args) throws Exception { // set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//默认情况下,检查点被禁用。要启用检查点,请在StreamExecutionEnvironment上调用enableCheckpointing(n)方法,
// 其中n是以毫秒为单位的检查点间隔。每隔5000 ms进行启动一个检查点,则下一个检查点将在上一个检查点完成后5秒钟内启动
env.enableCheckpointing(5000);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.192.12.106:9092");//kafka的节点的IP或者hostName,多个使用逗号分隔
properties.setProperty("zookeeper.connect", "10.192.12.106:2181");//zookeeper的节点的IP或者hostName,多个使用逗号进行分隔
properties.setProperty("group.id", "test-consumer-group");//flink consumer flink的消费者的group.id
FlinkKafkaConsumer09<String> myConsumer = new FlinkKafkaConsumer09<String>("test0", new SimpleStringSchema(),
properties);//test0是kafka中开启的topic
myConsumer.assignTimestampsAndWatermarks(new CustomWatermarkEmitter());
DataStream<String> keyedStream = env.addSource(myConsumer);//将kafka生产者发来的数据进行处理,本例子我进任何处理
keyedStream.print();//直接将从生产者接收到的数据在控制台上进行打印
// execute program
env.execute("Flink Streaming Java API Skeleton"); }
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark; public class CustomWatermarkEmitter implements AssignerWithPunctuatedWatermarks<String> { private static final long serialVersionUID = 1L; public long extractTimestamp(String arg0, long arg1) {
if (null != arg0 && arg0.contains(",")) {
String parts[] = arg0.split(",");
return Long.parseLong(parts[0]);
}
return 0;
} public Watermark checkAndGetNextWatermark(String arg0, long arg1) {
if (null != arg0 && arg0.contains(",")) {
String parts[] = arg0.split(",");
return new Watermark(Long.parseLong(parts[0]));
}
return null;
}
}
4.开启一台配置好zookeeper和kafka的Ubuntu虚拟机,输入以下命令分别开启zookeeper、kafka、topic、producer。(zookeeper和kafka的配置可参考https://www.cnblogs.com/ALittleMoreLove/p/9396745.html)
bin/zkServer.sh start
bin/kafka-server-start.sh config/server.properties
bin/kafka-topics.sh --create --zookeeper 10.192.12.106: --replication-factor --partitions --topic test0
bin/kafka-console-producer.sh --broker-list 10.192.12.106: --topic test0
5.检测Flink程序是否可以接收到来自Kafka生产者发来的数据,运行Java类KafkaDemo,在开启kafka生产者的终端下随便输入一段话,在IDEA控制台可以收到该信息,如下为kafka生产者终端和控制台。
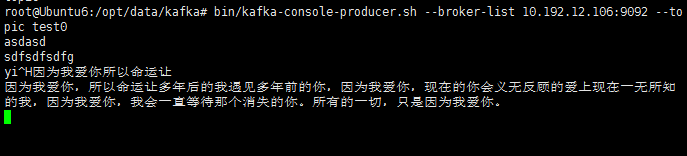
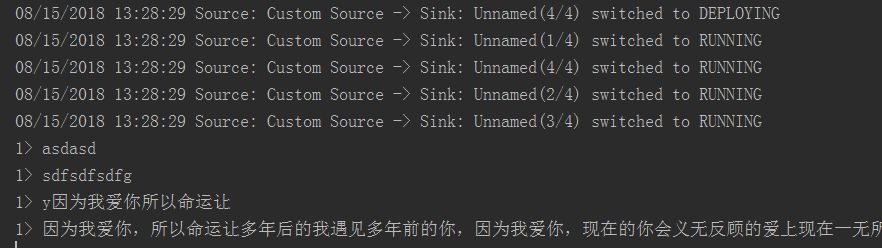
OK,成功的接收到了来自Kafka生产者的消息^.^。
Flink+Kafka整合的实例的更多相关文章
- 【译】Flink + Kafka 0.11端到端精确一次处理语义的实现
本文是翻译作品,作者是Piotr Nowojski和Michael Winters.前者是该方案的实现者. 原文地址是https://data-artisans.com/blog/end-to-end ...
- Kafka设计解析(二十二)Flink + Kafka 0.11端到端精确一次处理语义的实现
转载自 huxihx,原文链接 [译]Flink + Kafka 0.11端到端精确一次处理语义的实现 本文是翻译作品,作者是Piotr Nowojski和Michael Winters.前者是该方案 ...
- Kafka设计解析(二十)Apache Flink Kafka consumer
转载自 huxihx,原文链接 Apache Flink Kafka consumer Flink提供了Kafka connector用于消费/生产Apache Kafka topic的数据.Flin ...
- 【译】Apache Flink Kafka consumer
Flink提供了Kafka connector用于消费/生产Apache Kafka topic的数据.Flink的Kafka consumer集成了checkpoint机制以提供精确一次的处理语义. ...
- SpringBoot Kafka 整合集成 示例教程
1.使用IDEA新建工程,创建工程 springboot-kafka-producer 工程pom.xml文件添加如下依赖: <!-- 添加 kafka 依赖 --> <depend ...
- flume与kafka整合
flume与kafka整合 前提: flume安装和测试通过,可参考:http://www.cnblogs.com/rwxwsblog/p/5800300.html kafka安装和测试通过,可参考: ...
- 5 kafka整合storm
本博文的主要内容有 .kafka整合storm .storm-kafka工程 .storm + kafka的具体应用场景有哪些? 要想kafka整合storm,则必须要把这个storm-kafk ...
- 【原创】Kafka Consumer多线程实例续篇
在上一篇<Kafka Consumer多线程实例>中我们讨论了KafkaConsumer多线程的两种写法:多KafkaConsumer多线程以及单KafkaConsumer多线程.在第二种 ...
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
随机推荐
- 工作笔记—hibernate之QueryCriteria
本人用的是sg-uap虚拟环境 //查询方法 //参数 RequestCondition 配合 controller 的 @QueryRequestParam注解可以将前台传入整个对象进行接收 //参 ...
- Linux ->> UBuntu 14.04 LTE下安装Hadoop 1.2.1(伪分布模式)
Hadoop的运行模式可分为单机模式.伪分布模式和分布模式. 首先无论哪种模式都需要安装JDK的,这一步之前的随笔Ubuntu 14.04 LTE下安装JDK 1.8中已经做了.这里就不多说了. 其次 ...
- June 19th 2017 Week 25th Monday
Everyone is dissatisfied with his own fortune. 人对自己的命运总是感到不满足. We always want more, even when we hav ...
- 【海龟汤策略】反趋势交易策略源代码分享(基于BOTVS)
策略介绍: 海龟之汤,简称“龟汤”,是个与海龟交易法则相反的交易策略,它利用了跟势交易(特别是海龟方式)在很多假突破方面的缺陷来获利(把海龟做成汤吃掉).上世纪八十年代早期,有个非常著名的交易员团体— ...
- ROC曲线手画
绘图过程很简单:给定m个正例子,n个反例子,根据学习器预测结果进行排序,先把分类阈值设为最大,使得所有例子均预测为反例,此时TPR和FPR均为0,在(0,0)处标记一个点,再将分类阈值依次设为每个样例 ...
- 记录linux查询命令的一个网站
http://man.linuxde.net/ 另外下面是对常用命令的总结 https://www.cnblogs.com/soyxiaobi/p/9717483.html
- Linux修改权限命令chmod用法详解
Linux系统中的每个文件和目录都有访问许可权限,用它来确定谁可以通过何种方式对文件和目录进行访问和操作. 文件或目录的访问权限分为只读,只写和可执行三种.以文件为例,只读权限表示只允许读其内容,而禁 ...
- 小技巧:快速清除项目中的svn相关文件!
习惯使用svn作为源代码管理工具,安全可靠 但是这些.svn字样的文件夹及文件也会随着源代码一同被deploy到Tomcat中,除了看着碍眼,也会占用Tomcat的性能 每次都是在项目部署目录里,搜索 ...
- Codeforces Round #538 (Div. 2) D. Flood Fill 【区间dp || LPS (最长回文序列)】
任意门:http://codeforces.com/contest/1114/problem/D D. Flood Fill time limit per test 2 seconds memory ...
- JavaScript小游戏--2048(移动端)
HTML5中新添加了很多事件,但是由于他们的兼容问题不是很理想,应用实战性不是太强,所以在这里基本省略,咱们只分享应用广泛兼容不错的事件,日后随着兼容情况提升以后再陆续添加分享.今天为大家介绍的事件主 ...