Flink+Kafka整合的实例
Flink+Kafka整合实例
1.使用工具Intellig IDEA新建一个maven项目,为项目命名为kafka01。
2.我的pom.xml文件配置如下。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.hrb.lhr</groupId>
<artifactId>kafka01</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.1.4</flink.version>
<slf4j.version>1.7.7</slf4j.version>
<log4j.version>1.2.17</log4j.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- explicitly add a standard loggin framework, as Flink does not (in the future) have
a hard dependency on one specific framework by default -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.9_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies> </project>
3.在项目的目录/src/main/java在创建两个Java类,分别命名为KafkaDemo和CustomWatermarkEmitter,代码如下所示。
import java.util.Properties;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer09;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema; public class KafkaDeme { public static void main(String[] args) throws Exception { // set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//默认情况下,检查点被禁用。要启用检查点,请在StreamExecutionEnvironment上调用enableCheckpointing(n)方法,
// 其中n是以毫秒为单位的检查点间隔。每隔5000 ms进行启动一个检查点,则下一个检查点将在上一个检查点完成后5秒钟内启动
env.enableCheckpointing(5000);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.192.12.106:9092");//kafka的节点的IP或者hostName,多个使用逗号分隔
properties.setProperty("zookeeper.connect", "10.192.12.106:2181");//zookeeper的节点的IP或者hostName,多个使用逗号进行分隔
properties.setProperty("group.id", "test-consumer-group");//flink consumer flink的消费者的group.id
FlinkKafkaConsumer09<String> myConsumer = new FlinkKafkaConsumer09<String>("test0", new SimpleStringSchema(),
properties);//test0是kafka中开启的topic
myConsumer.assignTimestampsAndWatermarks(new CustomWatermarkEmitter());
DataStream<String> keyedStream = env.addSource(myConsumer);//将kafka生产者发来的数据进行处理,本例子我进任何处理
keyedStream.print();//直接将从生产者接收到的数据在控制台上进行打印
// execute program
env.execute("Flink Streaming Java API Skeleton"); }
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark; public class CustomWatermarkEmitter implements AssignerWithPunctuatedWatermarks<String> { private static final long serialVersionUID = 1L; public long extractTimestamp(String arg0, long arg1) {
if (null != arg0 && arg0.contains(",")) {
String parts[] = arg0.split(",");
return Long.parseLong(parts[0]);
}
return 0;
} public Watermark checkAndGetNextWatermark(String arg0, long arg1) {
if (null != arg0 && arg0.contains(",")) {
String parts[] = arg0.split(",");
return new Watermark(Long.parseLong(parts[0]));
}
return null;
}
}
4.开启一台配置好zookeeper和kafka的Ubuntu虚拟机,输入以下命令分别开启zookeeper、kafka、topic、producer。(zookeeper和kafka的配置可参考https://www.cnblogs.com/ALittleMoreLove/p/9396745.html)
bin/zkServer.sh start
bin/kafka-server-start.sh config/server.properties
bin/kafka-topics.sh --create --zookeeper 10.192.12.106: --replication-factor --partitions --topic test0
bin/kafka-console-producer.sh --broker-list 10.192.12.106: --topic test0
5.检测Flink程序是否可以接收到来自Kafka生产者发来的数据,运行Java类KafkaDemo,在开启kafka生产者的终端下随便输入一段话,在IDEA控制台可以收到该信息,如下为kafka生产者终端和控制台。
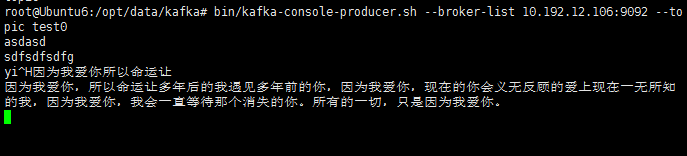
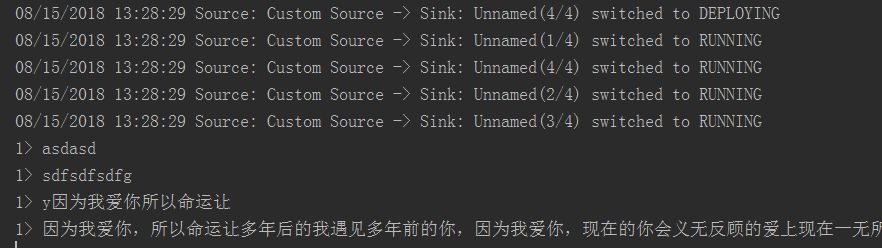
OK,成功的接收到了来自Kafka生产者的消息^.^。
Flink+Kafka整合的实例的更多相关文章
- 【译】Flink + Kafka 0.11端到端精确一次处理语义的实现
本文是翻译作品,作者是Piotr Nowojski和Michael Winters.前者是该方案的实现者. 原文地址是https://data-artisans.com/blog/end-to-end ...
- Kafka设计解析(二十二)Flink + Kafka 0.11端到端精确一次处理语义的实现
转载自 huxihx,原文链接 [译]Flink + Kafka 0.11端到端精确一次处理语义的实现 本文是翻译作品,作者是Piotr Nowojski和Michael Winters.前者是该方案 ...
- Kafka设计解析(二十)Apache Flink Kafka consumer
转载自 huxihx,原文链接 Apache Flink Kafka consumer Flink提供了Kafka connector用于消费/生产Apache Kafka topic的数据.Flin ...
- 【译】Apache Flink Kafka consumer
Flink提供了Kafka connector用于消费/生产Apache Kafka topic的数据.Flink的Kafka consumer集成了checkpoint机制以提供精确一次的处理语义. ...
- SpringBoot Kafka 整合集成 示例教程
1.使用IDEA新建工程,创建工程 springboot-kafka-producer 工程pom.xml文件添加如下依赖: <!-- 添加 kafka 依赖 --> <depend ...
- flume与kafka整合
flume与kafka整合 前提: flume安装和测试通过,可参考:http://www.cnblogs.com/rwxwsblog/p/5800300.html kafka安装和测试通过,可参考: ...
- 5 kafka整合storm
本博文的主要内容有 .kafka整合storm .storm-kafka工程 .storm + kafka的具体应用场景有哪些? 要想kafka整合storm,则必须要把这个storm-kafk ...
- 【原创】Kafka Consumer多线程实例续篇
在上一篇<Kafka Consumer多线程实例>中我们讨论了KafkaConsumer多线程的两种写法:多KafkaConsumer多线程以及单KafkaConsumer多线程.在第二种 ...
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
随机推荐
- mongodb 3.4 YUM安装
1:配置yum源vi /etc/yum.repos.d/mongodb-org-3.4.repo加入以下内容: [mongodb-org-3.4] name=MongoDB Repository ba ...
- java代码修改了之后运行仍然是原程序
有的时候java代码改了之后但是运行的程序却没有发生改动,这是什么情况呢?可能懂得的人都觉得十分简单,但对于我这样的小白来说确实很费力.java代码更改后需要编译生成.class文件,说的直白点,这个 ...
- MongoDB安装步骤
安装C:\Users\Administrator>d:\mongo\bin\mongod -dbpath=D:\ND.Monodb\ND.Monodb.db -logpath=D:\ND.Mon ...
- [问题记录]libpomelo编译报错:ssize_t重定义
1. 时间:2015/01/16 描述:添加libpomelo到cocos2dx项目,报错如下图所示: 解决: 修改代码,源代码: #if !defined(_SSIZE_T_) && ...
- 【jQuery】jQuery中的事件捕获与事件冒泡
在介绍之前,先说一下JavaScript中的事件流概念.事件流描述的是从页面中接受事件的顺序. 一.事件冒泡( Event Bubbling) IE 的事件流叫做事件冒泡,即 ...
- ZT sem_init sem_wait sem_post sem_destroy
sem_init() 2009-06-26 16:43:11| 分类: linux |字号 订阅 信号量的数据类型为结构sem_t,它本质上是一个长整型的数.函数sem_init()用来 ...
- 10个出色的NoSQL数据库(转)
随着大数据的不断发展,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速.现今的计算机体系结构在数据存储方面要有庞大的水平扩展性,而NoSQL也正是致力于改变这一现状.目前G ...
- MQ中将消息发送至远程队列的配置
MQ中将消息发送至远程队列的配置 摘自MQ资源管理器帮助文档V7 在开始学习本教程之前,您需要从系统管理员处了解标识网络上接收机器的名称:IP地址.MQ的端口号.队列管理器.接收(远程机器)或者是发送 ...
- Ajax回退刷新页面问题的解决办法
在脚本之家看到一篇文章,觉得以后可能会用上,但是竟然不能收藏,所以只能将其转到博客园. 以下是原文地址: http://www.jb51.net/article/87856.htm 这篇文章主要介 ...
- UVa 11082 - Matrix Decompressing(最大流)
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...