爬虫实战【11】Python获取豆瓣热门电影信息
之前我们从猫眼获取过电影信息,而且利用分析ajax技术,获取过今日头条的街拍图片。
今天我们在豆瓣上获取一些热门电影的信息。
页面分析
首先,我们先来看一下豆瓣里面选电影的页面,我们默认选择热门电影,啥都不点了。
【插入图片,豆瓣热门电影页面】
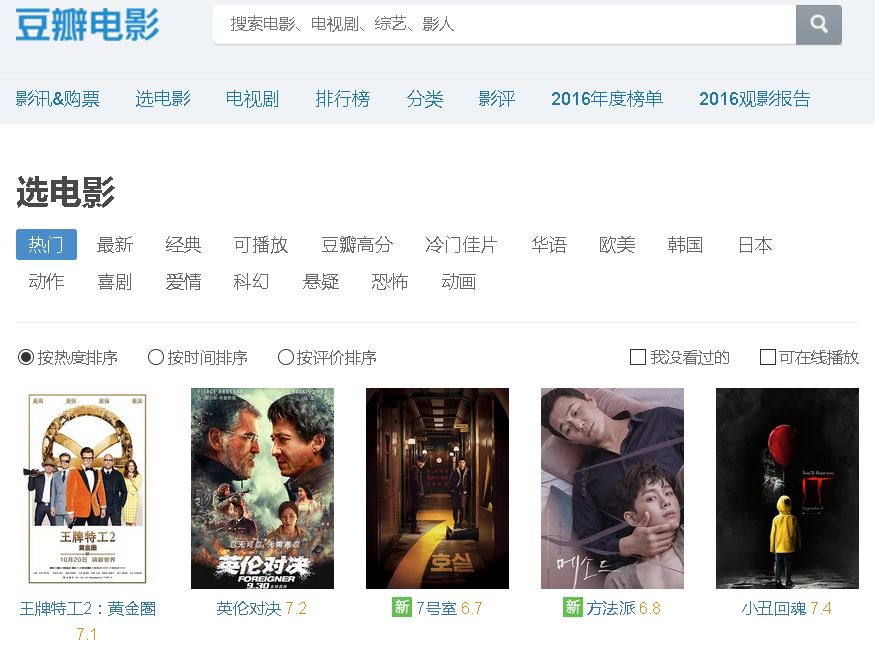
在选电影这个框中其实有很多标签的,这个其实可以在url设置,后面讲,现在就用热门好了。
下面每部电影罗列出来,包括电影封面,评分,电影名称等信息。
最下面是加载更多选项,其实看到这个加载更多,我就意识到这个页面肯定是用ajax技术实现的,就跟今日头条街拍那次一样,只不过不采用向下滚动,而是点击按钮加载的方式。
是不是这样的?我们看一下源代码。
果然都是一些js,我就不放图了,大家自己看一下就好了。
那么来看一下XHR了,果然下面有几个json文件,哈哈,猜测是正确的。
【插入图片,XHR分析】
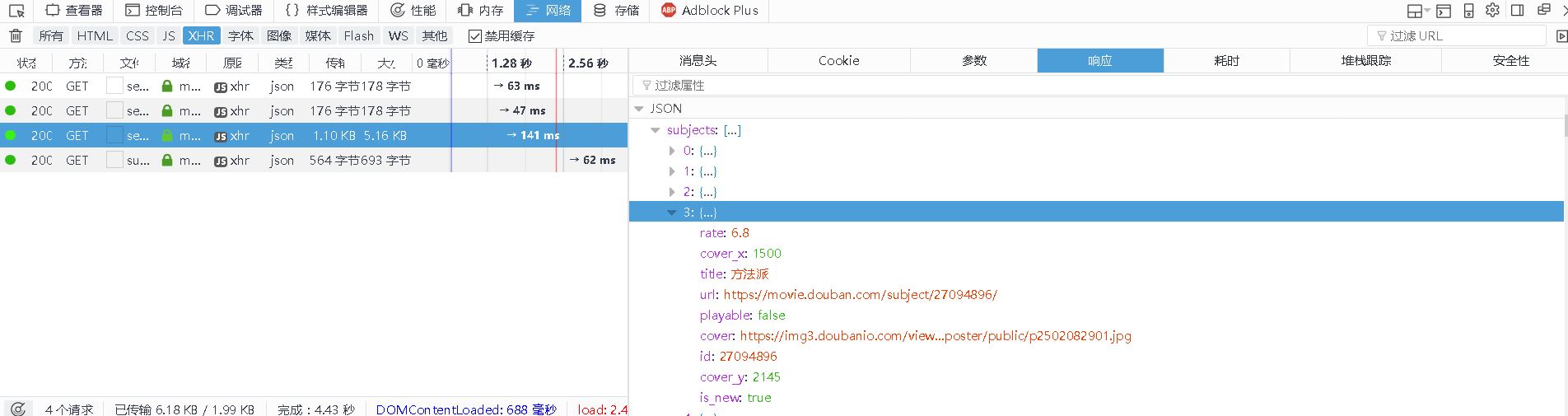
这次的json信息很简介,一个subjects下面就是各个电影的具体内容了,我们通过json的loads方法,就能够得到里面的信息了。
仍然是通过requests库来获取json信息,消息头的话,我们来看一下:
【插入图片,消息头分析】

这个url的前面部分是固定的,后面是一些参数,我们可以用urlencode来编码。
如果我们想要加载不同的页面,只要改变这个url里面的page_start参数就好了
【插入图片,加载更多】
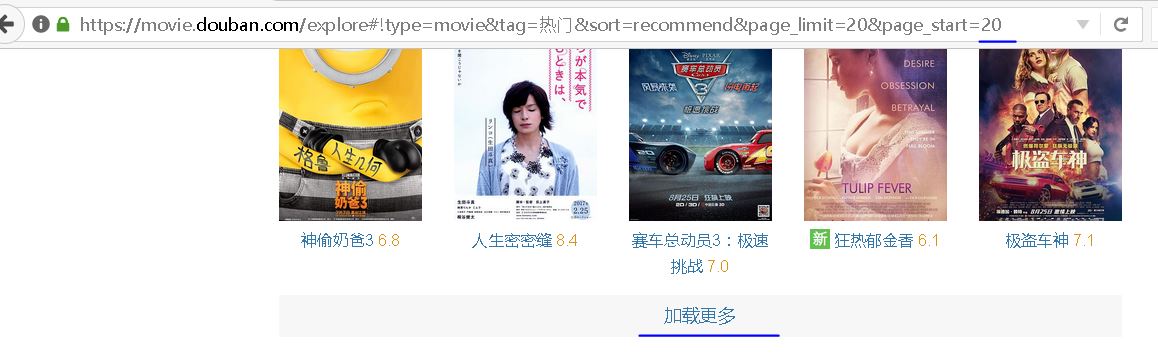
获取到某条电影信息后,我们就保存到mongodb数据库中。
代码展示
import requests
from urllib.parse import urlencode
import json
import pymongo
'''MONGO设置'''
MONGO_URL = 'localhost'
MONGO_DB = 'douban'
MONGO_Table = '热门'
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def get_movie_page(start_number):
data = {
'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': 20,
'page_start': start_number
}
url = 'https://movie.douban.com/j/search_subjects?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
# print(response.text)
return response.text
except Exception:
print('请求出错!')
return None
def parse_index_movie(html):
movie = json.loads(html)
result = []
if movie and 'subjects' in movie.keys():
for item in movie.get('subjects'):
film = {
'rate': item.get('rate'),
'title': item.get('title'),
'url': item.get('url'),
'cover': item.get('cover')
}
result.append(film)
save_to_db(film)
return result
def save_to_db(film):
try:
if db[MONGO_Table].insert(film):
print('保存成功', film)
except Exception:
print('保存出错', film)
pass
def main():
for i in range(100):
html = get_movie_page(i*20)
parse_index_movie(html)
if __name__ == '__main__':
main()
【插入图片,mongo数据】
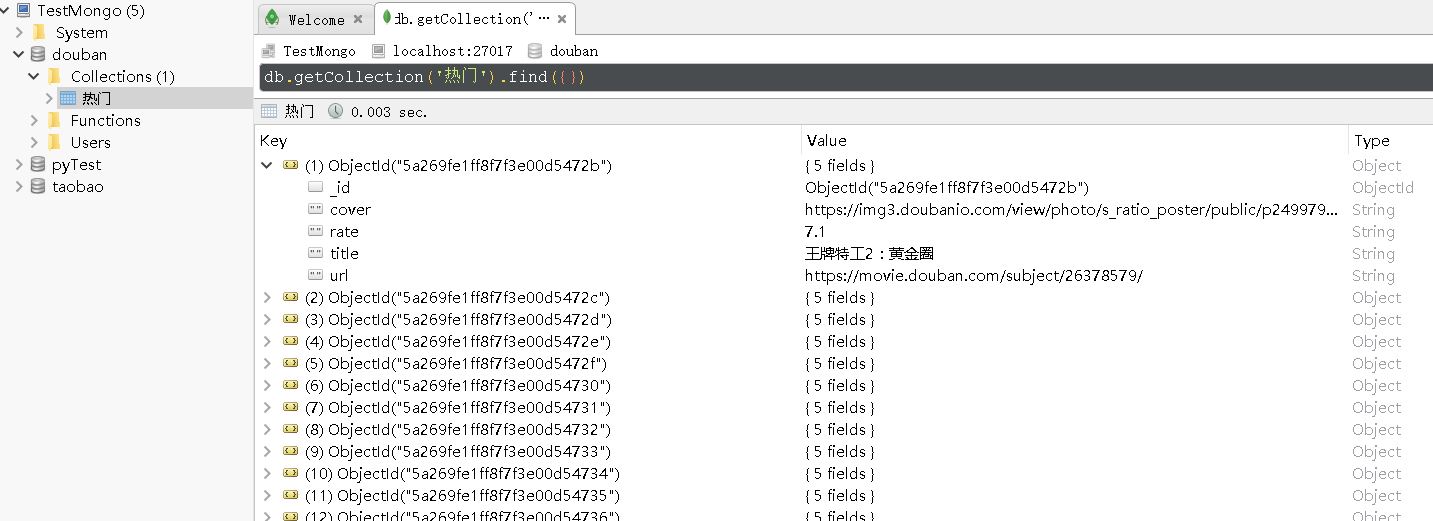
至此,我们得到了200多部热门电影的信息,尤其是每部电影的url,有了这个信息,我们就能打开每部电影的评论页面,获取到该部电影的短评。
这个留给明天再将。
爬虫实战【11】Python获取豆瓣热门电影信息的更多相关文章
- Python获取时光网电影数据
Python获取时光网电影数据 一.前言 有时候觉得电影真是人类有史以来最伟大的发明,我喜欢看电影,看电影可以让我们增长见闻,学习知识.从某种角度上而言,电影凭借自身独有的魅力大大延长了人类的&quo ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- python获取系统内存占用信息的实例方法
psutil是一个跨平台库(http://code.google.com/p/psutil/),能够轻松实现获取系统运行的进程和系统利用率(包括CPU.内存.磁盘.网络等)信息.它主要应用于系统监控, ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- 003.[python学习] 简单抓取豆瓣网电影信息程序
声明:本程序仅用于学习爬网页数据,不可用于其它用途. 本程序仍有很多不足之处,请读者不吝赐教. 依赖:本程序依赖BeautifulSoup4和lxml,如需正确运行,请先安装.下面是代码: #!/us ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
- 80 行代码爬取豆瓣 Top250 电影信息并导出到 CSV 及数据库
一.下载页面并处理 二.提取数据 观察该网站 html 结构 可知该页面下所有电影包含在 ol 标签下.每个 li 标签包含单个电影的内容. 使用 XPath 语句获取该 ol 标签 在 ol 标签中 ...
- python获取港股通每日成交信息
接口:ggt_daily 描述:获取港股通每日成交信息,数据从2014年开始 限量:单次最大1000,总量数据不限制 积分:用户积2000积分可调取,5000积分无限制,请自行提高积分,具体请参阅本文 ...
- python 获取淘宝商品信息
python cookie 获取淘宝商品信息 # //get_goods_from_taobao import requests import re import xlsxwriter cok='' ...
随机推荐
- 整站下载工具Teleport Pro
http://zmingcx.com/download-tools-teleport-pro-full-stop.html Teleport Pro是一款功能强大的离线浏览器,不论规模多大的网站,只要 ...
- 从1KW条数据中筛选出1W条最大的数
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using S ...
- Java 继承、多态与类的复用
摘要: 本文结合Java的类的复用对面向对象两大特征继承和多态进行了全面的介绍. 首先,我们介绍了继承的实质和意义,并探讨了继承,组合和代理在类的复用方面的异同.紧接着,我们依据继承引入了多态.介绍了 ...
- MOS管基本构造和工作原理
(一)http://v.youku.com/v_show/id_XMTM2NzcwMjE5Ng==.html (二)http://v.youku.com/v_show/id_XMTM2NzcwMjMw ...
- Laravel建站03--建立前台文章列表和文章详情
经过了前面的开发环境搭建和数据库配置.git配置的准备工作以后,现在可以开始动作做点什么了. 先从简单的开始,那就先来个文章列表和详情页吧. 这期间可以学习到路由.建立model.controller ...
- SignalR IOS Android
http://www.dotblogs.com.tw/toysboy21/archive/2014/03/24/144505.aspx https://www.youtube.com/watch?v= ...
- 未设置BufferSize导致FTP下载速度过慢的问题
開始下载前设置BufferSize就可以解决: ftpClient.setBufferSize(1024*1024); 查看commons-net的源代码.能够发现假设未设置该參数.将会一个字节一个字 ...
- (WPF)依赖属性
属性触发器: <Button MinWidth=" 75" Margin="10"> <Button.Style> <Style ...
- redis-cli 常用命令
1.连接操作相关的命令 quit:关闭连接(connection) auth:简单密码认证 2.对value操作的命令 exists(key):确认一个key是否存在 del(key):删除一个key ...
- The Definitive Guide To Django 2 学习笔记(一) Views and UrL confsRL
1.如何找到django在Ubuntu下的安装路径: 进入python命令行,import django,print(django.__path__) 2.使用django-admin.py 创建项目 ...