Kafka 学习翻译 - 介绍
Kafka是一个分布式的流式平台。可以从几个方面理解:
1. 三个重要的能力:
能够实现流式的发布和订阅数据,类似于消息队列或者企业级的消息分发系统。
能够在提供一定容错性和持久性能力的基础上存储数据。
流式处理数据
2. 用途:a. 系统间实时交换数据。 b. 利用其构建一个流式数据处理系统。
3. Kafka以集群的形式运行,并且具有跨数据中心横向扩展的能力。Kafka以topics归类消息。每一条数据都由key,value,timestamp构成。
4. 四类核心API:
Producer\Consumer:发布或者订阅topics
Stream:以流式的方式消费指定的topic,并向指定的topic发布内容
Connector:允许应用以对topics重用
客户端与服务端的通信通过TCP协议完成,并且协议被设计成后向兼容的方式。
Topics And Logs
Kafka的topic可以有任意多个消费者。
对每个topic来说,Kafka集群维护的分区日志(partitioned logs)机制如下:
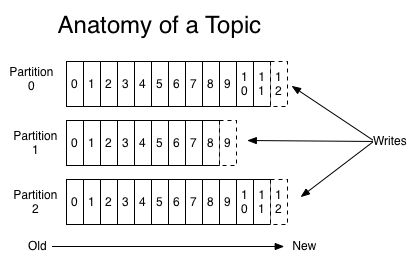
在每个分区中,数据都以不可改变的序列组织,新的数据追加在commit log尾部。每条记录均有一个offset唯一标识。
Kafka集群提供数据持久性保证,并且提供可配置的数据保留期限。
消费者记录所消费记录的当前offset,并且可以连续地或者跳跃地对记录进行消费。
上述机制使得消费者对Kafka集群的影响非常小,任意一个消费者的加入或者离开对于集群本身或者其他消费者都没有任何明显影响。
log的分区设计主要有如下目的。首先,分区使得可以log的大小不受单台服务器的限制。其次,这种设计也提供一定的并行性。
数据分布
Kafka集群中,每台服务器维护一定数量的分区,所有的分区平均分布在所有的机器上。对于每个分区来说,数据也被复制到一定数量的备份节点上,以提供一定的容错能力。
Geo-Replication
Kafka MirrorMaker 提供跨数据中心或者云端region的数据备份机制。可以利用这种机制实现数据的冷备份,或者双活场景中将数据放置在位置更近的机房中。
Producers
Producer向Topic发布数据,Producer负责选择将数据发送到topic的那个partion。可以通过轮询或者其他机制实现选择。
Comsumers
Comumer通过Group标识自己,每个topic中的一条记录都会被送到group中的一台consumer进行处理。
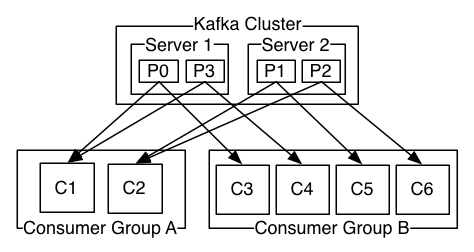
通常来说,topic的consumer group 数量都不会太大,但每个group中的consumer数通常是数个。
Kafka的消费机制通过将log的partitions分配各group中的每个消费者实例,使得在任意时间每个consumer都处理相当的partions。这种机制通过Kafka的通信协议动态维护。新加入的消费者节点或者挂掉的消费者节点都会引起重新分配。
Kafka仅提供分区内数据的顺序保证,对大多数应用来说够用了。如果需要topic的全局有序,则可以通过仅有一个partition来实现,这也意味着group中consumer的数量也是1。
多租户
Kafka支持多租户部署。
Guarantees
Kafka提供如下保证
同一个producer发送的数据以发送的数据追加记录。
consumer消费数据的顺序与其存储的顺序一致。
对于一个具有N个备份的topic,最大N-1个节点的故障不会引起数据丢失。
与传统企业级消息系统的比较
消息的分发通常有两种形式:队列模型或者发布-订阅模型。队列模型支持多个订阅者,但某条数据只会被某一个订阅者获取。发布-订阅模型中,消息广播到每个消费者中,因此,消费的整体能力不能够得到水平扩展。
Kafka的partition及consumer group设计使得其同时提供了这两种能力:水平扩展消费者群的处理能力 以及 某条消息被多个消费者处理。partition的设计使得同一个consumer group中可以扩展consumer来使得消费者群的处理能力得到提升。consumer group的设计使得某条消息可以发往多个group中的consumer,不同group间互不影响。
同时,这种设计机制也提供了一定程度的顺序性保证。在传统的消息系统中,要保证顺序性,则只能丢失消费者的水平扩展能力,如果要水平扩展消费者,由于每条记录被分发到不同的消费者中,则整体的顺序性得不到保证。而Kafka的partion设计使得在partition中,消息一定是被顺序送达消费者的,同时,对于有N个partion的topic,其最大的消费者数也能达到N。
Kafka提供的存储能力
作为任何一个消息系统,由于producer和consumer间是异步的,所有的消息都需要保存下来。
所有发往Kafka的数据都写盘并且复制到备份节点以提供容错能力。Kafka也允许producer在数据得到完全复制和写入硬盘后才得到成功响应。
Kafka存储的数据量也不会对其本身的性能造成影响。
Kafka提供的流式处理能力
除了读、写、存储这些基本的能力,Kafka被设计为能够实时处理数据流。
Kafka将如此场景视为流式处理:从输入的topic中流式获取数据,经过一定的处理并将流式结果写入输出的topic。Kafkati提供Stream API,支持对数据流的复杂处理。这使得对无序数据的处理,执行有状态的计算等成为可能。
Kafka 学习翻译 - 介绍的更多相关文章
- Kafka学习(一)kafka指南(about云翻译)
kafka 权威指南中文版 问题导读 1. 为什么数据管道是数据驱动企业的一个关键组成部分? 2. 发布/订阅消息的概念及其重要性是什么? 第一章 初识 kafka 企业是由数据驱动的.我们获取信息, ...
- Kafka学习之路
一直在思考写一些什么东西作为2017年开篇博客.突然看到一篇<Kafka学习之路>的博文,觉得十分应景,于是决定搬来这“他山之石”.虽然对于Kafka博客我一向坚持原创,不过这篇来自Con ...
- 【译】Kafka学习之路
一直在思考写一些什么东西作为2017年开篇博客.突然看到一篇<Kafka学习之路>的博文,觉得十分应景,于是决定搬来这“他山之石”.虽然对于Kafka博客我一向坚持原创,不过这篇来自Con ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- KafKa——学习笔记
学习时间:2020年02月03日10:03:41 官网地址 http://kafka.apache.org/intro.html kafka:消息队列介绍: 近两年发展速度很快.从1.0.0版本发布就 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- Kafka学习-入门
在上一篇kafka简介的基础之上,本篇主要介绍如何快速的运行kafka. 在进行如下配置前,首先要启动Zookeeper. 配置单机kafka 1.进入kafka解压目录 2.启动kafka bin\ ...
- kafka学习2:kafka集群安装与配置
在前一篇:kafka学习1:kafka安装 中,我们安装了单机版的Kafka,而在实际应用中,不可能是单机版的应用,必定是以集群的方式出现.本篇介绍Kafka集群的安装过程: 一.准备工作 1.开通Z ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
随机推荐
- 零零碎碎的java知识:static属性、普通属性、static代码块、普通代码块、构造函数
本文中结论仅经本机测试,不保证在别的环境下成立.如果有什么不成立的地方务必告诉我_(:_」∠)_ java的内存是动态分配的,其机制和c/c++相当不一样……emmm在此不表. static: ·st ...
- Java—IO流 字符流
java的文本(char)是16位无符号整数,是字符的unicode编码(双字节编码). 文件是byte byte byte ... 的数据序列. 文本文件是文本(char)序列按照某种编码方案(uf ...
- Markdown学习使用
本文记录Markdown的基础应用. 一.基础知识 Markdown 是一种标记语言 文件后缀名:.md 编辑工具:VSCode(visual studio code) VSCode中预览模式快捷键: ...
- python全栈学习笔记(二)网络基础之子网划分
阅读目录 一.ip地址基本知识 1.1 ip地址的结构和分类 1.2 特殊ip地址 1.3 子网掩码 1.4 ip地址申请 二.子网划分 2.1 子网划分概念 2.2 c类子网划分初探 2.3 子网划 ...
- Mysql 系统学习梳理_【All】
0.Linux学习---CentOS 7编译安装MySQL 8.0 1.Mysql学习---SQL语言的四大分类 2.Mysql学习---基础操作学习 3.Mysql学习---基础操作学习2 4.My ...
- linux配置sudo
编辑/etc/sudoers或者直接使用root用户运行visodu 添加如下两行:oracle ALL=(ALL) NOPASSWD: ALLoinstall ALL=( ...
- selenium+python 数据驱动-csv篇,可封装
#循环读取csv文件中的数据,可以作为用户名,密码等使用from selenium import webdriverimport csv#获取csv文件中password列with open(r'C: ...
- S/4HANA业务角色概览之订单到收款篇
大家好我叫Sean Zhang,中文名张正永.目前在S/4HANA产品研发部门任职产品经理,而这一阶段要从2017年算起,而在那之前接触更多还是技术类的,比如做过iOS.HANA.ABAP.UI5等等 ...
- Codeforces Round #423 (Div. 2)
codeforces 423 A. Restaurant Tables [水题] //注意,一个人选座位的顺序,先去单人桌,没有则去空的双人桌,再没有则去有一个人坐着的双人桌.读清题意. #inclu ...
- Android(java)学习笔记207:Android下的属性动画(Property Animation)
1. 属性动画(Property Animation)引入: 在手机上去实现一些动画效果算是件比较炫酷的事情,因此Android系统在一开始的时候就给我们提供了两种实现动画效果的方式,逐帧动画(fra ...