4.K均值算法应用
一、课堂练习
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_sample_image #导入图片数据
import PIL #引入PIL,但是下载不下来,如果没有的话,载入图片会报错
import sys
china=load_sample_image("china.jpg")
plt.imshow(china) #显示图片
plt.show() #显示
sys.getsizeof(china) #看一个变量占的内存大小
china.size
import matplotlib.image as img
img.imsave("D://china.jpg",china)
image=china[::3,::3] #把图片的尺寸变小,每隔三个取一个
X=china.reshape(-1,3) #任意行,3列 线性,
n_colors=64 #(255*255*255) #把255*255*255这么多颜色聚类成64
model=KMeans(n_colors)
model.fit(X)
predict=model.predict(X) #训练后预测
colors=model.cluster_centers_ #聚类中心,64类,64种颜色,3是rgb
#predict是每一个像素的类别,colors是具体的值,427行,[[640x3]]
new_img=colors[predict].reshape(china.shape)
sys.getsizeof(new_img) #现在占内存128 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.figure(figsize=(8,8))
plt.subplot(221)
plt.title("原图")
plt.imshow(china)
plt.subplot(222)
plt.title("64种颜色")
plt.imshow(new_img.astype(np.uint8))#转化为整型
plt.subplot(223)
plt.title("1/3的像素")
plt.imshow(new_img[::3,::3].astype(np.uint8)) #进行压缩 内存还是128,但是丢掉了很多像素


二、作业
1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import sys
from sklearn.cluster import KMeans
import numpy as np
Img_w=mpimg.imread('./机器学习/William.jpg') #读取图片
plt.imshow(Img_w)
plt.show()
print("图片大小为:",Img_w.size)
print("图片内存大小为:",sys.getsizeof(Img_w))#占内存大小为128
print("图片数据结构为:",Img_w)
print("图片线性化后:",Img_w.reshape(-1,3))
Img_w.shape
X_w=Img_w.reshape(-1,3)
w_model=KMeans(n_clusters=64) #构建模型,将255*255*255个颜色聚类成64个颜色
w_model.fit(X_w) #训练reshape后成线性的数据
w_predict=w_model.predict(X_w) #预测
colors_center=w_model.cluster_centers_
#w_predict是每一个像素的类别,colors_center是颜色具体的值,427行,[[640x3]]
new_w=colors_center[w_predict].reshape(Img_w.shape)
print("图片大小为:",new_w.size)
print("压缩后图片内存大小为:",sys.getsizeof(new_w))#占内存大小为128
print("图片大小为:",new_w[::6,::6].size)
print("压缩后图片内存大小为:",sys.getsizeof(new_w[::6,::6]))#占内存大小为128
mpimg.imsave("D://new_w.jpg",new_w.astype(np.uint8)) plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.figure(figsize=(8,8)) #自定义一个画布
plt.subplot(221) #是2x2的格子上第一块图形
plt.title("原图")
plt.imshow(Img_w)#转化为整型
plt.subplot(222) #是2x2的格子上第一块图形
plt.title("64种颜色")
plt.imshow(new_w.astype(np.uint8))#转化为整型
plt.subplot(223) #是2x2的格子上第2块图形
plt.title("1/6的像素")
plt.imshow(new_w[::6,::6].astype(np.uint8)) #进行压缩 内存还是128,但是丢掉了很多像素
对一张图片来说,最重要的就是像素(宽x高)和颜色(rgb),所以shape(70,70,3)是像素70x70,每个像素点又和颜色有关。





2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
数据:数据是找正在上信息系统的同学要的,是关于航空的数据,包括用户的信息、客户乘机信息、客户积分信息
研究内容:将乘客进行分类,如重要保持客户、重要发展客户、重要挽留客户、一般客户等等。
步骤:
读取数据->抽取相关属性数据->进行数据探索与预处理->建模和训练->可视化->预测
入会时间越久说明,一则说明乘客是忠实客户,需要重点保持联系等等、二则如果入会时间久但是其飞行次数和总公里等等不多,则说明客户可能是需要重要挽留客户。
入会时间不久,但是客户的飞行次数多,飞行总公里多,飞行平均间隔短,则可能说明客户是重要发展对象。
飞行次数和飞行总公里还有飞行平均间隔都可以突显乘客属于哪一类客户,而平均折扣与航空公司利益有关。
有些乘客可能飞行次数不多,但是他们的飞行总公里多,这样需要的钱会更多,折扣力度也会不同。
所以我选择了以上几个属性,并对其进行了数据预处理等操作。
import pandas as pd
import numpy as np
air=pd.read_csv("./机器学习/air_data.csv",engine='python',nrows=10000)#读取文件,抽取10000条数据
air.columns #得到其所有属性
df_air=air[['FFP_DATE','LOAD_TIME','FFP_TIER','FLIGHT_COUNT','SEG_KM_SUM','AVG_INTERVAL','avg_discount']]#从中找出自己需要的属性
df_air.isnull().sum()#查看是否有缺值 False则没有缺失值
df_air.describe(include="all") #统计性描述
df_air.loc[:,'LOAD_TIME']=pd.to_datetime(df_air.loc[:,'LOAD_TIME'])
df_air.loc[:,'FFP_DATE']=pd.to_datetime(df_air.loc[:,'FFP_DATE'])
df_air["入会时间"]=(df_air.loc[:,'LOAD_TIME']-df_air.loc[:,'FFP_DATE']).astype(np.int64)/(60*60*24*10**9)
df_air=df_air.rename(columns={"FFP_TIER":"会员等级","FLIGHT_COUNT":"飞行次数","SEG_KM_SUM":"飞行总公里","AVG_INTERVAL":"飞行平均间隔","avg_discount":"平均折扣"})
df_air=df_air[["入会时间","会员等级","飞行次数","飞行总公里","飞行平均间隔","平均折扣"]]
df_air.describe()

数据预处理完成以后,可以进行模型的构建和训练,选择聚类中心为5,按更加严谨的来说,是需要去测试究竟哪个聚类中心数是最好的。
分为5个聚类中心后,统计各个类别的数目,看看每一类用户有多少人。
from sklearn.cluster import KMeans
X_a=df_air.iloc[:,:]
model_a=KMeans(n_clusters=5)
model_a.fit(X_a)
Y_predicta=model_a.predict(X_a)
s = pd.Series(['客户群1','客户群2','客户群3','客户群4','客户群5'], index=[0,1,2,3,4]) #创建一个序列s
r1 = pd.Series(model_a.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(model_a.cluster_centers_) #找出聚类中心
r = pd.concat([s,r1,r2], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns =[u'聚类名称'] +[u'聚类个数'] + list(df_air.columns) #重命名表头
print(r)

可视化能够更好的帮助我们看模型构建训练完以后数据的分布。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.scatter(X_a.iloc[:,2],X_a.iloc[:,3],Y_predicta,c=Y_predicta,cmap="rainbow")
plt.xlabel("飞行次数")
plt.ylabel("飞行总公里")
plt.show()
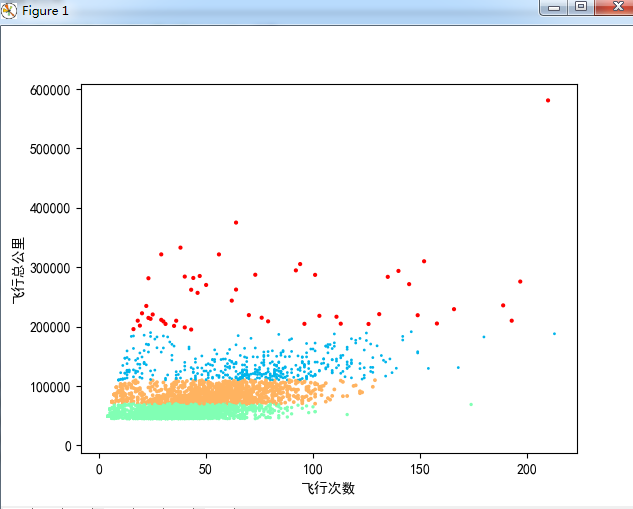
最后进行预测,假如给一个客户的信息,需要分到这5类中的一类客户。
# ["入会时间","会员等级","飞行次数","飞行总公里","飞行平均间隔","平均折扣"]
test=pd.DataFrame(np.array([[2000,5,240,304567,3.23333,0.92222]]))
model_a.predict(test.iloc[:,:])

借鉴资料: https://blog.csdn.net/a857553315/article/details/79177524
4.K均值算法应用的更多相关文章
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- spark Bisecting k-means(二分K均值算法)
Bisecting k-means(二分K均值算法) 二分k均值(bisecting k-means)是一种层次聚类方法,算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二.之后选择能最大程 ...
随机推荐
- JS 剑指Offer(五) 二叉树的重建
题目:输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树.假设输入的前序遍历和中序遍历的结果中都不含重复的数字. 题目分析:已知二叉树的前序和中序遍历,根据前序遍历和中序遍历的规则,前序遍历的第一 ...
- 手工注入——access手工注入实战和分析
今天进行了access手工注入,下面是我的实战过程和总结. 实战环境使用的是墨者学院的在线靶场.下面咱们直接进入主题. 第一步,判断注入点 通过‘ 或者 and 1=1 和 and 1=2 是否报错, ...
- PostgreSql 自定义函数:批量调整某个字段长度
CREATE or replace FUNCTION alterColumn(cloumnName VARCHAR(32), out v_retcode text)AS$BODY$ declare r ...
- Luogu1039 侦探推理
题目描述 明明同学最近迷上了侦探漫画<柯南>并沉醉于推理游戏之中,于是他召集了一群同学玩推理游戏.游戏的内容是这样的,明明的同学们先商量好由其中的一个人充当罪犯(在明明不知情的情况下),明 ...
- python的字符串、列表、字典和函数
一.字符串 在python中字符串无需通过像php中的explode或者javascript中的split进行分解即可完成切片,可以直接通过下标获取字符串中的每一个字符,下标从0开始,如果从厚望签署, ...
- spring boot 异步发送邮件
发送邮件由于是一个耗时的操作,有可能需要一个几十秒的操作,但是呢,接口 是一个瞬间完成的,为了不影响接口的性能,所以需要对发送邮件的操作进行异步操作,我们这里呢,首先我们要引入发送邮件的测试模块. & ...
- java中查询某个类已经创建了多少个对象了
这个代码主要是使用类的静态字段和构造函数,可以跟踪某个类所创建对象的个数.请写一个类,在任何时候都可以向它查询“你已经创建了多少个对象? 主要是在构造函数中用到了静态数据,进行显示已经构造了多少个类对 ...
- docker-compose错误
1.错误信息: ERROR: for gamehall Get https://hub.tondeen.com/v1/_ping: http: server gave HTTP response to ...
- Python 的while循环和for循环的使用
#循环 遍历 迭代 # while循环 a = 0while a <5: a =a+1 if a == 3: continueprint('我循环了')+str(a) # print ('我循环 ...
- Git应用详解第五讲:远程仓库Github与Git图形化界面
前言 前情提要:Git应用详解第四讲:版本回退的三种方式与stash 这一节将会介绍本地仓库与远程仓库的一些简单互动以及几款常用的Git图形化界面,让你更加方便地使用git. 一.Git裸库 简单来说 ...