解析网站爬取腾讯vip视频
今天用油猴脚本vip一件解析看神奇队长。想到了问题,这个页面应该是找到了视频的api的接口,通过接口调用获取到了视频的地址。
那自己找腾讯视频地址多费劲啊,现在越来越多的参数,眼花缭乱的。
那我就找到这个能够解析vip视频的,解析网站的视频地址,不就OK了。
network上发现,这个视频是通过ts流的形式。

并且还有视频地址和index.m3u8,但是我们怎么获得这些20190527/参数呢。(m3u8中有一部电影的所有ts流参数)
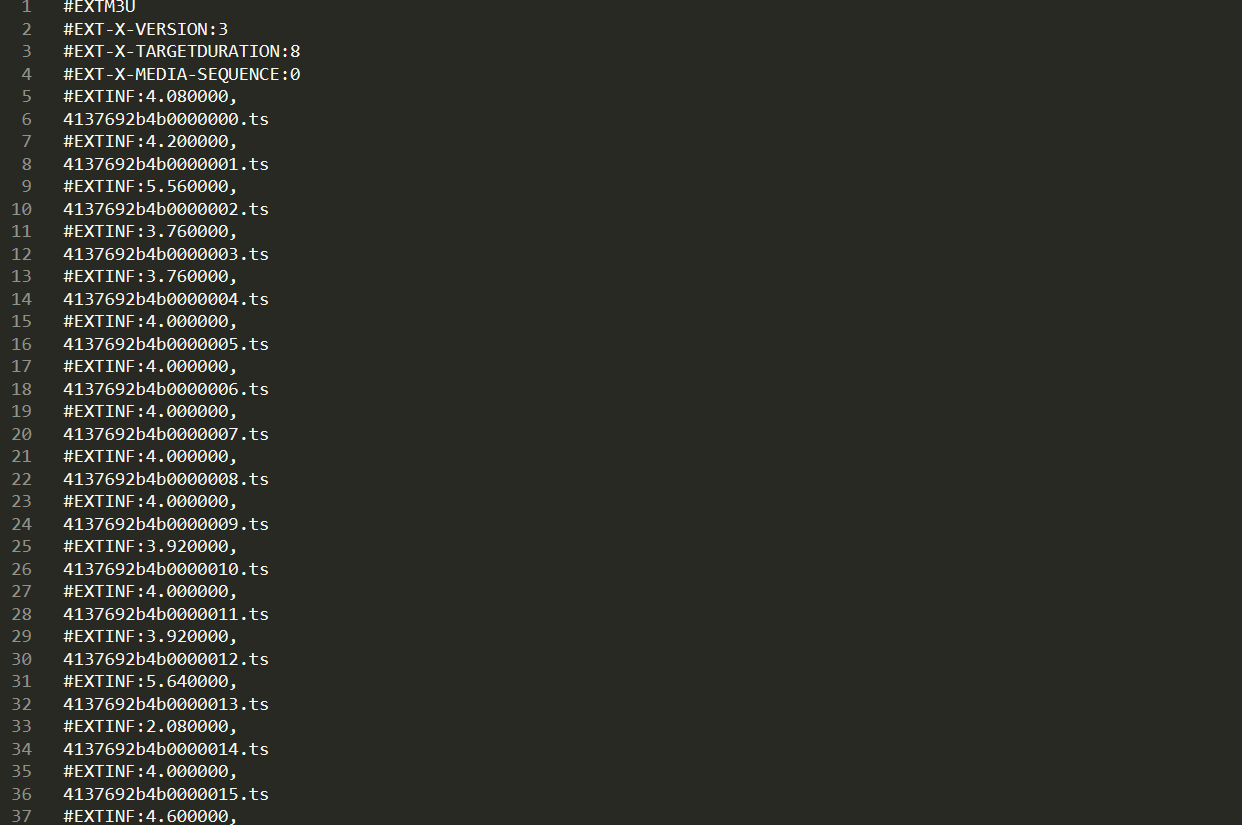
我找到了个api.php,即接口地址,访问,返回json数据。
url: http://p.p40.top/api.php?url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fxyne4253g35nak3%2Fm0031od9ekb.html


看到了视频流所在地址,然后访问地址,可以直接下载m3u8文件,文件中就是ts流参数了。
因此思路就是:用py模拟浏览器向解析网站的api.php请求你想看的vip视频的url即http://p.p40.top/api.php?url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fxyne4253g35nak3%2Fm0031od9ekb.html
然后正则匹配到m3u8的地址,去请求后,下载到本地,打开匹配ts流的数字id。
发现视频地址就是api返回的json数据的url+/1000k/hls/xxx

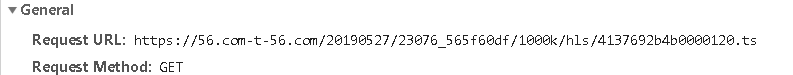
然后依次下载完ts流文件后,保存到本地。再转化成mp4,明儿实现。网上有些现成的。我试着改编下。
这样父母不需要怎么操作,我直接下下来本地给他们看就好了。嘿嘿
脚本如下:
# -*- coding: UTF-8 -*-
import requests
import re
import os,shutil
from urllib.request import urlretrieve
from multiprocessing import Pool def cbk(a,b,c):
'''''回调函数
@a:已经下载的数据块
@b:数据块的大小
@c:远程文件的大小
'''
per=100.0*a*b/c
if per>100:
per=100
print('%.2f%%' % per) def get_api_data(QQ_film_url): #正则匹配获取api返回的index.m3u8链接地址
api_url='http://p.p40.top/api.php'
user_agent={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
get_url=api_url+'?url='+QQ_film_url
print(get_url)
response=requests.get(get_url,headers=user_agent).text
pattern=re.compile('url.*?m3u8')
get_data=pattern.findall(response)[0][6:].replace('\\','')
return get_data def m3u8_download(m3u8_url):#获取下载m3u8文件
if os.path.exists('F:\\vip电影\\index.m3u8')!=True:#判断文件是否已经存在,存在则不操作。不存在才下载。
urlretrieve(url=m3u8_url, filename=path, reporthook=cbk)
else:
print(path+'已存在') def get_ts():#通过m3u8文件,正则匹配需要的ts流
with open(path)as f:
data=f.read()
pattern=re.compile('.*.ts')
get_ts_data=re.findall(pattern,data)
return get_ts_data def ts_download(ts_list):#下载ts流
try:
ts_url = m3u8_url[:-10]+'{}'.format(ts_list)#获取ts流 url地址
urlretrieve(url=ts_url, filename=path[:-10] + r'\\' + '{}'.format(ts_url[-8:]))
except Exception:
print(ts_url+'保存文件错误') def pool(ts_list):#多进程爬取所有的ts流到文件夹中,参考的那个py脚本,没用过pool进程池
print('经过计算,需要下载%s个文件'%len(ts_list))
print(ts_list[0])
pool=Pool(16)
pool.map(ts_download,[i for i in ts_list])
pool.close()
pool.join()
print('下载完成')
ts_to_mp4() def ts_to_mp4():
print('dos实现ts合并为mp4')
str = 'copy /b ' + r'F:\vip电影' + '\*.ts ' + ' '+ r'F:\vip电影\gogogo' + '\jingqi.mp4'
os.system(str)
if os.path.exists('F:\\vip电影\\gogogo\\jingqi.mp4')==True:
print('good job') path = 'F:\\vip电影\\index.m3u8'
url = 'https://v.qq.com/x/cover/xyne4253g35nak3/m0031od9ekb.html'
m3u8_url = get_api_data(url)[:-10] + '1000k/hls/index.m3u8'
print(m3u8_url)
m3u8_download(m3u8_url)
ts_list = get_ts()
if __name__ == '__main__':
pool(ts_list)


成功,可能是多进程模块的问题,还是出现了将近15个文件错误。少了15个文件,但是为啥爬下来的时长比腾讯视频里的还长。
脚本还有很多地方都可以改进(锻炼自己写脚本的能力),改成类的调用,通过类中的self,一个函数接着一个函数调用。并且试试用多线程试试,多进程总有奇怪的问题,不统一。
看了一会儿,发现,观影视觉极差,我感觉丢失的不止是15个文件,音话都不同步了,是不是直接copy拼接命令有瑕疵。有待研究
解析网站爬取腾讯vip视频的更多相关文章
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- python 爬取腾讯视频的全部评论
一.网址分析 查阅了网上的大部分资料,大概都是通过抓包获取.但是抓包有点麻烦,尝试了F12,也可以获取到评论.以电视剧<在一起>为例子.评论最底端有个查看更多评论猜测过去应该是 Ajax ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- Python爬取腾讯新闻首页所有新闻及评论
前言 这篇博客写的是实现的一个爬取腾讯新闻首页所有的新闻及其所有评论的爬虫.选用Python的Scrapy框架.这篇文章主要讨论使用Chrome浏览器的开发者工具获取新闻及评论的来源地址. Chrom ...
- 5分钟掌握智联招聘网站爬取并保存到MongoDB数据库
前言 本次主题分两篇文章来介绍: 一.数据采集 二.数据分析 第一篇先来介绍数据采集,即用python爬取网站数据. 1 运行环境和python库 先说下运行环境: python3.5 windows ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 基于webmagic的种子网站爬取
代码地址如下:http://www.demodashi.com/demo/12175.html 1. 概述 因为无聊,闲来没事做,故突发奇想,爬个种子,顺便学习爬虫.本文将介绍使用Spring/Myb ...
随机推荐
- 《利用Hyper-V搭建虚拟机》一篇管够,持续更新
开门见山:win10+Hyper-V+ContOS7.X 万物皆有目的:没钱买云服务器,但平时在家想持续学习,可以考虑在自己windows上搭建一台虚拟机,然后装上Linux,调试通网络进行开发. 涉 ...
- 最新SCI影响因子发布!Nature屠榜,AI领域Top 1000期刊盘点
[导读]2018年度SCI期刊影响因子最新发布,Nature.Science.Cell三大神刊排名前列.新智元摘取其中有关人工智能.机器学习.计算机视觉.机器人学等领域的期刊并做简要介绍,希望对读者选 ...
- coding++ :Layui-监听事件
在使用layui的form表单做验证提交的时候,如果结合vue,或者是三级联动的时候,就需要做事件监听了. 具体语法: form.on('event(过滤器值)', callback); 可以用于监听 ...
- return console.log()结果为undefined现象的解答
console.log总是出现undefined--麻烦的console //本文为作者自己思考后总结出的一些理论知识,若有错误,欢迎指出 bug出现 需求如下:新建一个car对象,调用其中的de ...
- Spring - 事务管理概述
什么是事务管理? 第一个问题:什么是事务? 事务一般是相对数据库而言的,对于数据库一次操作就属于一个事务, 一次操作可以是几句 SQL 语句,也可以是若干行 JDBC 的 Java 语句.事务既然 ...
- Git之旅
ithub安装,我选择的是windows下的版本. git配置用户信息 安装完成后,还需要最后一步设置,在命令行输入: $git config --global user.name "You ...
- Django-on_delete
一.外键的删除 关于on_delete的总结 1.常见的使用方式(设置为null) class BookModel(models.Model): """ 书籍表 &quo ...
- A 大地魂力
时间限制 : - MS 空间限制 : - KB 评测说明 : 1s,256m 问题描述 奶牛贝西认为,要改变世界,就必须吸收大地的力量,贝西把大地的力量称为魂力.要吸取大地的魂力就需要在地上开出 ...
- H - Bone Collector
H - Bone Collector Many years ago , in Teddy's hometown there was a man who was called "Bone Co ...
- 我是如何从通信转到Java软件开发工程师的?
我的读者里面有绝大部分都是在校学生,有本科的,也有专科的,我在微信里收到很多读者的提问,大部分问题都跟如何学习编程有关,有换专业自学的.有迷茫不知道如何学习的.有报培训班没啥效果的等等,我能感受到他们 ...