Gradient descend 梯度下降法和归一化、python中的实现(未完善)
梯度下降法
通常就是将一组输入样本的特征$x^i$传入目标函数中,如$f(x) = wx + b$,再计算每个样本通过函数预测的值$f(x^i)$与其真实值(标签)$y^i$之差,然后计算所有差的平方和获得一个关于$w$损失函数$L(w)$:
$L(w) = \sum\limits_{i=0}^m [f(x^i) - y^i]^2 = \sum\limits_{i=0}^m (wx^i + b - y^i)^2 $
目标就是让通过调整$w$让这个损失函数尽量小。首先给$w$一个随机的初始值,然后每次朝着梯度的反方向更新一下$w$的位置,这样就能使损失函数达到一个局部最小点$w^*$。
$w^{t+1} = w^t - \eta\Delta L(w^t)$
梯度下降法常用方法
对于$\eta$的选取要灵活,因为如果过大,迭代可能会跳过了极小点,过小又导致迭代过慢。通常是让$\eta$刚开始大一些,随着迭代逐渐减小。如:
$\eta^{t} = \frac{\eta}{\sqrt{t+1}}$, $t$从$0$开始
Adagrad
为了平衡每次迭代函数下降的大小,Adagrad 方法在学习速率$\eta^t$下面再除以了一项$\sigma^t$:
$\eta^t = \eta^t / \sigma^t$
$\sigma^t = \sqrt{\sum\limits_{i=0}^t (g^i)^2/(t+1)}, g^i = \Delta L(w^i) $
$\sqrt{t+1}$与上面抵消掉得:
$\eta^{t} = \frac{\eta}{\sum\limits_{i=0}^t (g^i)^2}$
则$w^{t+1}$为:
$w^{t+1} = w^t - \frac{\eta}{\sqrt{\sum\limits_{i=0}^t (g^i)^2}}\Delta L(w^t)$
以下是用Adagrad实现的梯度下降python代码:
import numpy as np
import matplotlib.pyplot as plt
import pandas #x和y的数据集
x_data = np.array([338., 333., 328., 207., 226., 25., 179., 60., 208., 606.])
y_data = np.array([640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]) #设置下降参数w和b将要画的等高线图的范围
x_b = np.arange(-200,-100,1)
y_w = np.arange(-5,5,0.1)
X,Y = np.meshgrid(x_b,y_w)
#设置w、b参数网格并给所有网格点计算相应的损失函数(用于画损失函数的等高线图 )
Z_loss = np.zeros([len(x_b),len(y_w)])
for i in range(len(x_b)):
for j in range(len(y_w)):
w = y_w[j]
b = x_b[i]
for n in range(len(x_data)):
Z_loss[j][i] += (y_data[n] - x_data[n] * w - b) ** 2
#梯度下降迭代次数
itera_time = 100000
#初始化w和b
w = -4.
b = -120.
#初始化列表,存w和b的迭代经过,用于画图
w_history = [w]
b_history = [b]
#设置Adagrad学习率的上半部分
lr = 1
#初始化Adagrad学习率的下半部分
lr_b = 0.
lr_w = 0.
#进行梯度下降
for i in range(itera_time):
#每次迭代计算梯度
b_grad = 0.;
w_grad = 0.;
for n in range(len(x_data)):
b_grad += -2. * (y_data[n] - w*x_data[n] - b)
w_grad += -2. * (y_data[n] - w*x_data[n] - b) * x_data[n]
#给Adagrad学习率的下半部分加上每次迭代的梯度平方
lr_b += b_grad**2
lr_w += w_grad**2
#w和b改变一次位置
w -= w_grad * lr / np.sqrt(lr_w)
b -= b_grad * lr / np.sqrt(lr_b)
#存入这次迭代
w_history.append(w);
b_history.append(b);
#画等高线图
plt.contourf(X,Y,Z_loss,alpha=0.5,levels=50,cmap = 'jet')
#标出最优解
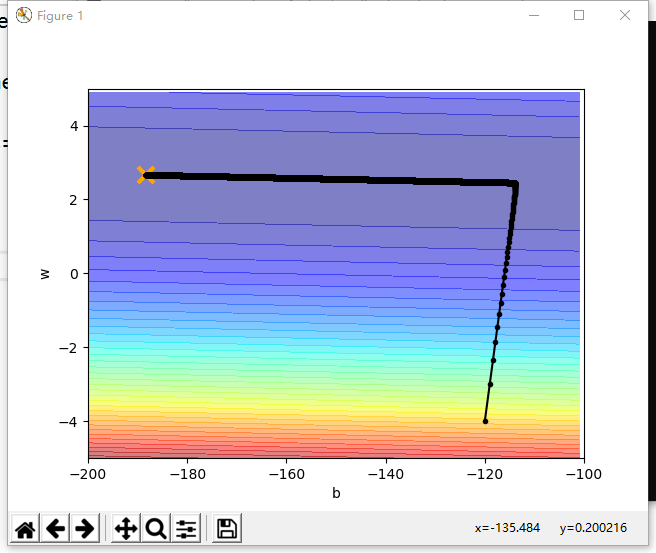
plt.plot([-188.4],[2.67],'x',ms=12,mew=3,color='orange')
#画出迭代经过
plt.plot(b_history,w_history,'o-',ms=3,lw=1.5,color='black')
#设置图像x、y轴显示宽度
plt.ylim(-5,5)
plt.xlim(-200,-100)
plt.ylabel("w")
plt.xlabel("b")
plt.show()
以下是代码的运行结果图,可以看到参数w和b最终迭代到了最优点:
归一化
还有重要的一点是,最好在开始迭代之前,先把输入的各个参数的分布进行归一化(Feature scaling)。
比如输入样本有两个元素$x1$和$x2$,它们的分布如下图:
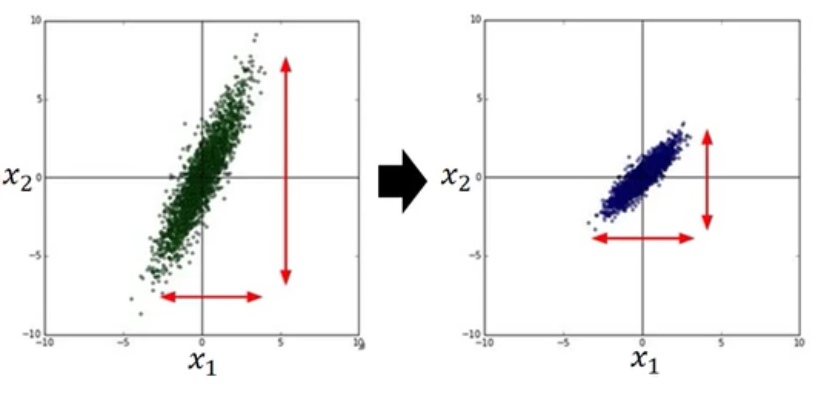
当梯度下降法进行的时候,它们迭代的路径就会有如下差别(因为是线性相乘的$wx$,所以$x2$的分布宽导致了$w2$方向的函数更加窄):

可以明显看到,归一化后的迭代会更平滑,更直接,没归一化的迭代会随着等高线扭曲前进,增加迭代次数。
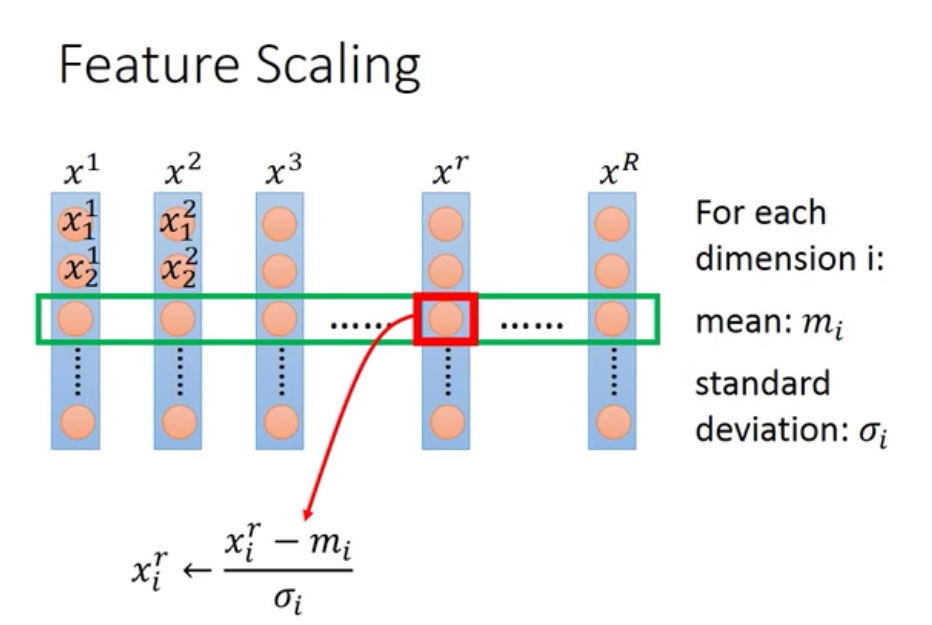
归一化的方法就是对于输入的每一个维度都单独计算它们的平均值和标准差,然后把每个元素都减去均值后再除以标准差:
那么归一化后的样本传入函数以后,优化完毕的参数还需要反归一化,具体怎么做呢?
。。。。。。

Gradient descend 梯度下降法和归一化、python中的实现(未完善)的更多相关文章
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 梯度下降(Gradient Descent)
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- [Python]数据挖掘(1)、梯度下降求解逻辑回归——考核成绩分类
ps:本博客内容根据唐宇迪的的机器学习经典算法 学习视频复制总结而来 http://www.abcplus.com.cn/course/83/tasks 逻辑回归 问题描述:我们将建立一个逻辑回归模 ...
- 梯度下降(Gradient Descent)相关概念
梯度,直观理解: 梯度: 运算的对像是纯量,运算出来的结果会是向量在一个标量场中, 梯度的计算结果会是"在每个位置都算出一个向量,而这个向量的方向会是在任何一点上从其周围(极接近的周围,学过 ...
- [AI]神经网络章2 神经网络中反向传播与梯度下降的基本概念
反向传播和梯度下降这两个词,第一眼看上去似懂非懂,不明觉厉.这两个概念是整个神经网络中的重要组成部分,是和误差函数/损失函数的概念分不开的. 神经网络训练的最基本的思想就是:先“蒙”一个结果,我们叫预 ...
- 线性回归 Linear regression(2)线性回归梯度下降中学习率的讨论
这篇博客针对的AndrewNg在公开课中未讲到的,线性回归梯度下降的学习率进行讨论,并且结合例子讨论梯度下降初值的问题. 线性回归梯度下降中的学习率 上一篇博客中我们推导了线性回归,并且用梯度下降来求 ...
- 多变量线性回归时使用梯度下降(Gradient Descent)求最小值的注意事项
梯度下降是回归问题中求cost function最小值的有效方法,对大数据量的训练集而言,其效果要 好于非迭代的normal equation方法. 在将其用于多变量回归时,有两个问题要注意,否则会导 ...
- 梯度下降法实现(Python语言描述)
原文地址:传送门 import numpy as np import matplotlib.pyplot as plt %matplotlib inline plt.style.use(['ggplo ...
- Stanford大学机器学习公开课(二):监督学习应用与梯度下降
本课内容: 1.线性回归 2.梯度下降 3.正规方程组 监督学习:告诉算法每个样本的正确答案,学习后的算法对新的输入也能输入正确的答案 1.线性回归 问题引入:假设有一房屋销售的数据如下: 引 ...
随机推荐
- Redis为什么要自己实现一个SDS
Redis是使用C语言开发的,在C语言中没有字符串这种数据类型,字符串大都是通过字符数组实现的,但是使用字符数组有以下不足: 1. 字符数组的长度都是固定,容易发生空指针2. 获取字符数组的长度的时候 ...
- SMBUS与I2C
SMBUS(系统管理总线)基于I2C总线,主要用于电池管理系统中.它工作在主/从模式:主器件提供时钟,在其发起一次传输时提供一个起始位,在其终止一次传输时提供一个停止位:从器件拥有一个唯一的7或10位 ...
- 实验一  GIT 代码版本管理
实验一 GIT 代码版本管理 实验目的: 1)了解分布式分布式版本控制系统的核心机理: 2) 熟练掌握git的基本指令和分支管理指令: 实验内容: 1)安装git 2)初始配置git ,git ...
- idea提交项目到码云
1.安装Git 2.在码云上创建项目 3.在IDEA提交项目到码云
- BUUCTF知识记录
[强网杯 2019]随便注 先尝试普通的注入 发现注入成功了,接下来走流程的时候碰到了问题 发现过滤了select和where这个两个最重要的查询语句,不过其他的过滤很奇怪,为什么要过滤update, ...
- Python使用pyautogui控制鼠标键盘
官方文档:https://pyautogui.readthedocs.io/en/latest/# 安装pyautogui模块 在 Windows 上,不需要安装其他模块. 在 OS X 上,运行 s ...
- char、pchar、string互相转换
1.string转换成pchar 可以使用pchar进行强制类型转换,也可以使用StrPCopy函数 var s:string; p,p1:PChar; begin s:='Hello Delphi' ...
- Java面向对象编程 -1.2
类与对象简介 类是某一类事物的共性的抽象概念 而对象描述的是一个具体的产物 类是一个模板,而对象才是类可以使用的实例,先有类再有对象 在类之中一般都会有两个组成: 成员属性(Filed) :有些时候为 ...
- Duilib热键
转载:https://www.zhaokeli.com/article/8288.html 在initwindow中注册热键 //生成热键标识,需要保存起来退出时销毁使用 int m_HotKeyId ...
- 第2节 Scala中面向对象编程:9、getClass和classOf;10、调用父类的constructor;11、抽象类和抽象字段;
6.3.4. Scala中getClass 和 classOf Class A extends class B B b=new A b.getClass ==classOf[A] B b ...