scrapy框架中的pipelines没有成功调用process_item方法
提示报错
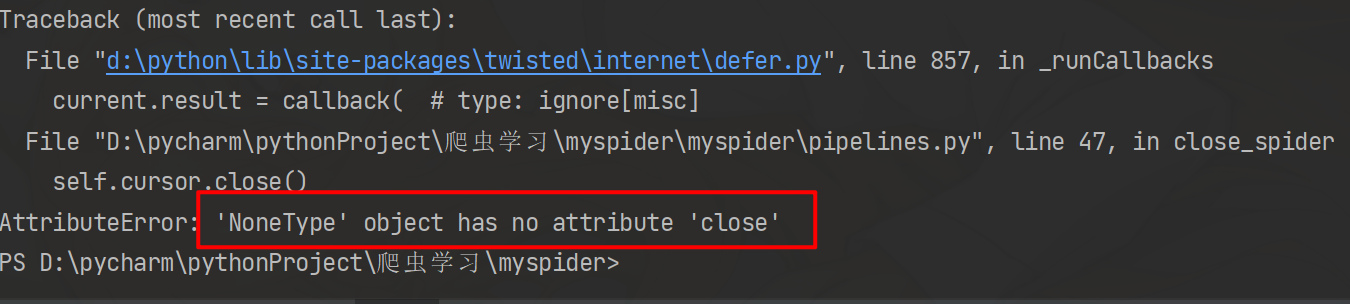
原因:
items没有接收到Spider的返回值,导致pipelines没有接收到items模块的返回值,检查Spider模块是否正确返回值,我这里的原因是,数据解析完成后没有yield item,导致pipelines不能执行数据处理操作
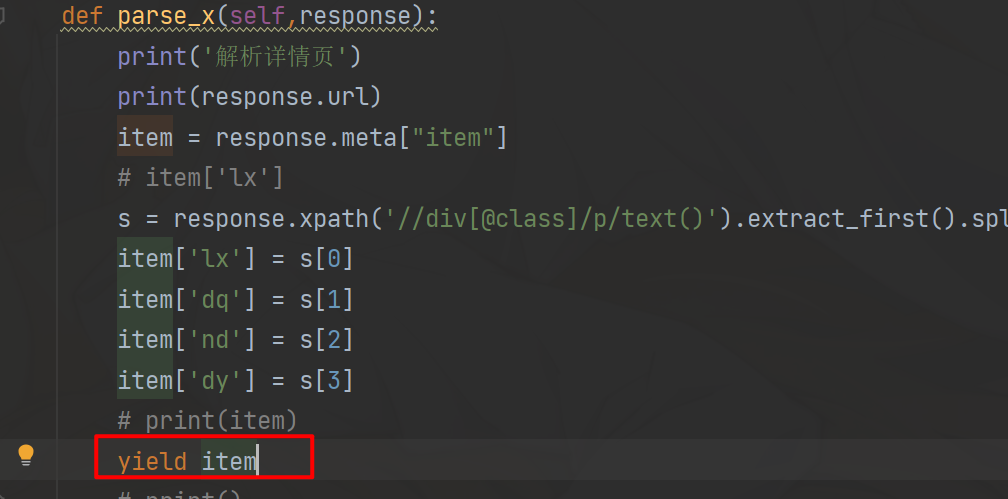
加上后就正常操作数据库了
scrapy框架中的pipelines没有成功调用process_item方法的更多相关文章
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- Scrapy框架中的CrawlSpider
小思考:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法二: ...
- scrapy框架中Spiders用法
scrapy框架中Spiders用法 Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据 总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以 ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Python的Django框架中forms表单类的使用方法详解
用户表单是Web端的一项基本功能,大而全的Django框架中自然带有现成的基础form对象,本文就Python的Django框架中forms表单类的使用方法详解. Form表单的功能 自动生成HTML ...
- DRF框架中链表数据通过ModelSerializer深度查询方法汇总
DRF框架中链表数据通过ModelSerializer深度查询方法汇总 一.准备测试和理解准备 创建类 class Test1(models.Model): id = models.IntegerFi ...
- scrapy框架中多个spider,tiems,pipelines的使用及运行方法
用scrapy只创建一个项目,创建多个spider,每个spider指定items,pipelines.启动爬虫时只写一个启动脚本就可以全部同时启动. 本文代码已上传至github,链接在文未. 一, ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
随机推荐
- SAP 内外交货单过账
* 交货单过账 DATA: LS_HEADER_DATA TYPE BAPIIBDLVHDRCON, LS_HEADER_CONTROL TYPE ...
- PHPStudy设置局域网访问
PHPStudy是一款轻量级PHP服务器,搭建环境迅速.但是与XAMPP之类服务器不同的是,PHPStudy默认只有本机才能设置域名.访问网站.需要更改vhost.conf中的文件,才可以使得内网可以 ...
- P8201 [传智杯 #4 决赛] [yLOI2021] 生活在树上(hard version)
个人思路: 首先,题目可以转化为是否存在 \(a,b\) 路径上一点 \(u\),满足 \(w_u = dis{1,a} \oplus dis{1,b} \oplus w_{lca(a,b)} \op ...
- String.prototype.replace--替换字符串
str.replace(regexp|substr, newSubStr|function) API本身不改变原本的字符串,只是返回新的字符串例子:用函数作为第二个参数function rep ...
- 基于.NET Core3.1的SQLiteHelper增删改帮助类
安装驱动包 install-package Microsoft.Data.Sqlite -version 3.1.7 install-package System.Data.SQLite.Core - ...
- 某个灰产远程调用的script源码
访问一个老域名,可能是释放了被所灰产的的注册了,跳转简单扒下他们的源码. 主要是三段script代码,第一段是百度自动推送代码,第二段是站长统计代码,第三段则是远程调用断码. <html xml ...
- Lua中对自定义二维表进行添加、修改、计算、删除、判断是否存在操作
引言: 最近刚稍微深入了解一下Lua,正好最近需要用到Lua中对表的操作,于是借助现有的了解实现了对一个简单的二维表进行添加.修改.计算.删除及判断存在的操作 表的创建及相关方法: 1. 创建表及自定 ...
- CString常用方法简介
CString常用方法简介 CString::Compare int Compare( LPCTSTR lpsz ) const; 返回值 字符串一样 返回0 小于lpsz 返回-1 大于lps ...
- vue-webpack代理
baseUrl 改为 '/api'
- python3.7 sorted 自定义排序
from functools import cmp_to_keyls=['9','23','3','56','78']sorted(ls, key=cmp_to_key(lambda x, y: in ...