scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
- 清理html数据
- 验证爬取的数据
- 去重并丢弃
- 将爬取的结果保存到数据库中或文件中
持久化存储
import pymysql
import redis # 只要涉及到持久化相关的操作,必须写在管道文件中 # 管道文件:需要接收爬虫文件提交过来的数据,并对数据进行持久化存储(IO操作)
class ThreePipeline(object):
fp = None # 只会被执行一次(开始爬虫的时候执行一次)
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('./job.txt', "w") # 链接数据库啊,数据库的写入等操作 # 只能处理item
# 和items联合使用的
# process_item核心方法被调用 将item中数据写入磁盘本地
# 爬虫每提交一次item,该方法就会被调用一次
def process_item(self, item, spider):
# 爬虫每提交一次item,该方法就会被调用一次
# print(item['company'])
self.fp.write(item['title'] + "\t" + item['salary'] + '\t' + item['salary'] + '\n') return item def close_spider(self, spider):
print('爬虫结束')
self.fp.close() # 注意:默认情况下管道机制并没有开启,需要手动在配置文件中手动开启 # 使用管道进行持久化存储的流程:
"""
1 获取解析到的数据值
2 将解析的数据值存储到item对象(item类中进行相关属性的声明)
3 通过yield关键字将item提交到管道
4 管道文件中进行持久化存储代码的编写(process_item)
5 在配置文件中开启管道
""" # 存入mysql
class MysqlPipeline(object):
conn = None
cursor = None def open_spider(self, spider):
print("mysql-start")
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='', db='spider')
print(self.conn) def process_item(self, item, spider):
self.cursor = self.conn.cursor()
sql = 'insert into boss values ("%s", "%s", "%s")' % (item['title'], item['salary'], item['company'])
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback() return item def close_spider(self, spider):
self.cursor.close()
self.conn.close()
print('mysql-end') # 存入redis
class RedisPipeline(object):
conn = None def open_spider(self, spider):
print('redis-start')
self.conn = redis.Redis(host='127.0.0.1', port=6379) def process_item(self, item, spider):
dic = {
"title": item['title'],
"salary": item['salary'],
"company": item['company']
}
self.conn.lpush('job_info', dic) return item def close_spider(self, spider):
print('redis-end') # 注意: 一定要保证每一个管道类的process_item方法有返回值
持久化存储-mysql-文件-redis
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
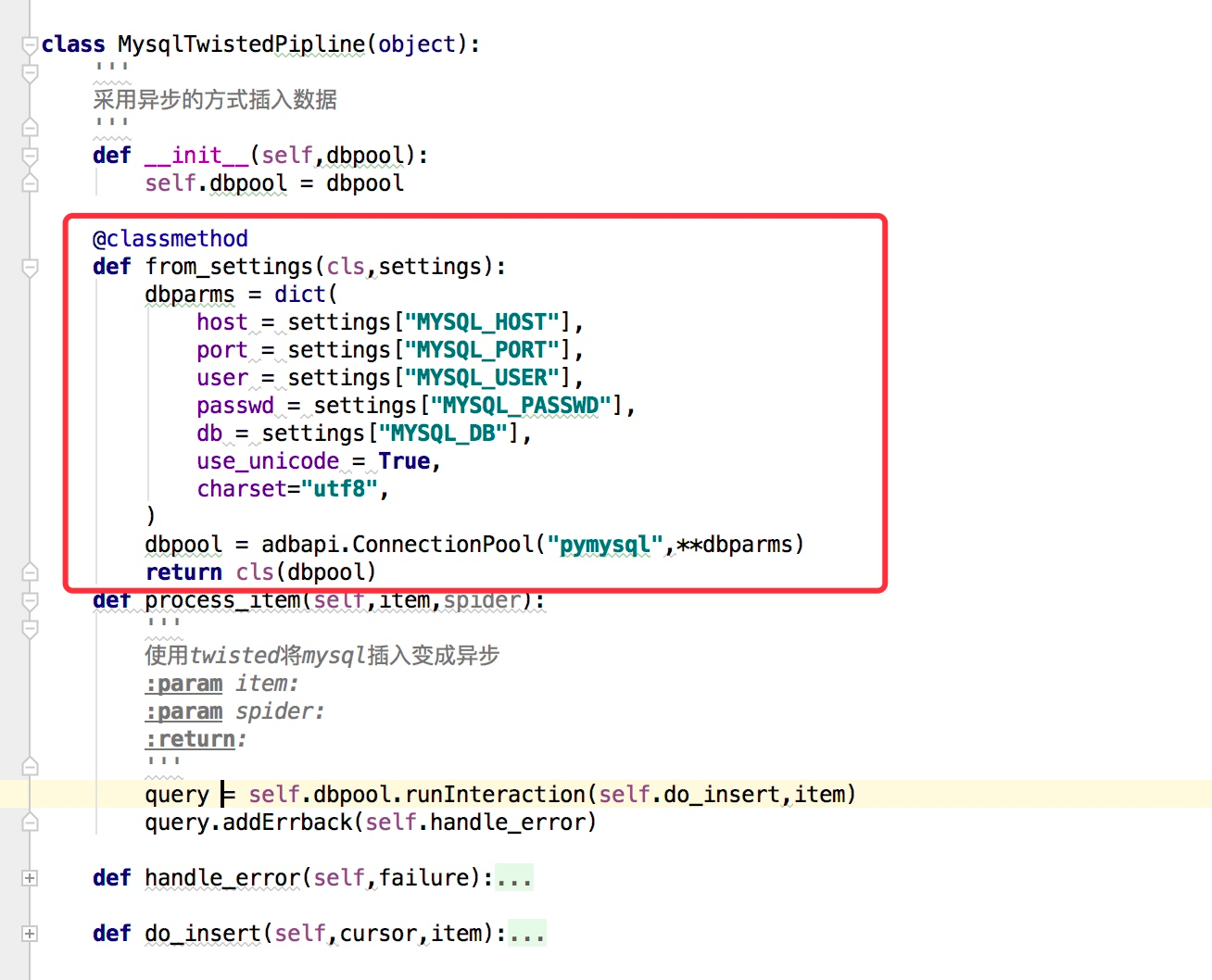
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断item中是否包含price以及price_excludes_vat,如果存在则调整了price属性,都让item['price'] = item['price'] * self.vat_factor,如果不存在则返回DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将item写入到MongoDB,同时这里演示了from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的item,假设item有一个唯一的id,但是我们spider返回的多个item中包含了相同的id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先
scrapy框架中Item Pipeline用法的更多相关文章
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python之爬虫(十八) Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- 6-----Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Scrapy框架中的Pipeline组件
简介 在下图中可以看到items.py与pipeline.py,其中items是用来定义抓取内容的实体:pipeline则是用来处理抓取的item的管道 Item管道的主要责任是负责处理有蜘蛛从网页中 ...
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python之爬虫(十六) Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
随机推荐
- ThinkPHP RBAC权限管理机制
RBAC是ThinkPHP很好用的后台权限管理的,话不多说,实现方法如下,也方便以后自己查询使用: 1.新建4个数据库表 self_role权限表 CREATE TABLE `self_role` ( ...
- windows server 2008 + IIS 7.5实现多用户FTP(多账号对应不同目录
在windows server 2003 + IIS 6 的时候,就已经能实现多用户FTP的功能,不过设置有写繁琐,如果站点多的话,设置账号.权限这些东西都要搞很久.Windows server 20 ...
- scroll或是其子类被添加进view时,界面自动上移
开发中经常会遇到ViewController添加scroll或是其子类被添加进controller.view时,scroll会自动下移大概64像素 解决: self.edgesForExtendedL ...
- 【mysql】mysql innodb 配置详解
MySQL innodb 配置详解 innodb_buffer_pool_size:这是InnoDB最重要的设置,对InnoDB性能有决定性的影响.默认的设置只有8M,所以默认的数据库设置下面Inno ...
- codeforces B. Bear and Strings 解题报告
题目链接:http://codeforces.com/problemset/problem/385/B 题目意思:给定一条只有小写英文组成的序列,需要找出至少包含一个“bear”的单词的子序列个数.注 ...
- 解决 Git 冲突的 14 个建议和工具
Git 非常善于合并代码.代码的合并在本地完成,快速而且灵活.正常情况下每次从不同分支合并内容时,冲突有可能会发生.通常解决冲突很简单,就如同知道(如何)选择(保留)重要的更改一样,而有时解决冲突则需 ...
- php排序方法之冒泡排序
//冒泡排序法 $arr = array(3,55,45,2,67,76,6.7,-65,85,4); function bubblingSort($arr){ for ( $i=0; $i<c ...
- UVA-10534 (LIS)
题意: 给定一个长为n的序列,求一个最长子序列,使得该序列的长度为2*k+1,前k+1个数严格递增,后k+1个数严格单调递减; 思路: 可以先求该序列最长单调递增和方向单调递增的最长序列,然后枚举那第 ...
- SecureCRT自动备份脚本-思科
利用SecureCRT脚本对思科设备进行批量备份: (1)新建文本文件(注意保存路径,本次测试路径为D:\backup\list.txt): x.x.x.x username password ena ...
- 【C/C++】产生随机数
#include<iostream> #include<Ctime> #include<Cstdlib> using namespace std; //产生n个st ...