HBase详解(03) - HBase架构和数据读写流程
RegionServer 架构
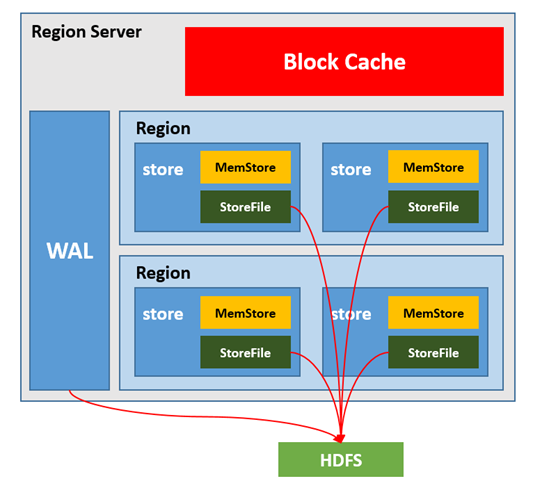
每个RegionServer可以服务于多个Region
每个RegionServer中有多个Store,
1个WAL和1个BlockCache
每个Store对应一个列族,包含MemStore和StoreFile
- StoreFile
将有序K-V的文件存储在HDFS上
保存实际数据的物理文件,StoreFile以Hfile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
- MemStore
MemStore:写缓存,K-V在Memstore中进行排序,达到阈值之后才会flush到StoreFile,每次flush生成一个新的StoreFile
由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
- WAL
WAL:Write Ahead Log,预写日志,防止RegionServer故障,导致MemStore中的数据丢失。
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)BlockCache
BlockCache:读缓存,每次新查询的数据会缓存在BlockCache中。方便下次查询。
写流程
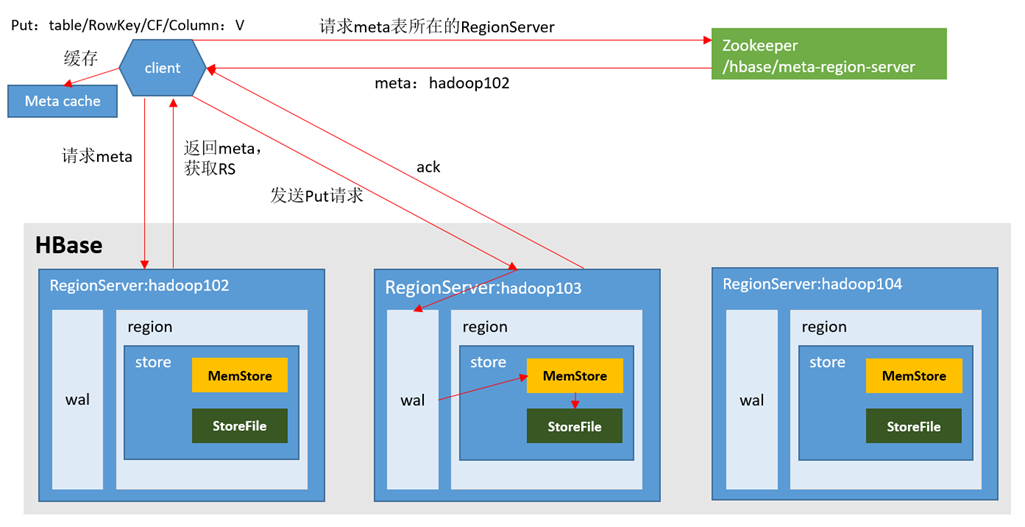
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)将数据顺序写入(追加)到WAL;
5)将数据写入对应的MemStore,数据会在MemStore进行排序;
6)向客户端发送ack;
7)等达到MemStore的刷写时机后,将数据刷写到HFile。
MemStore Flush
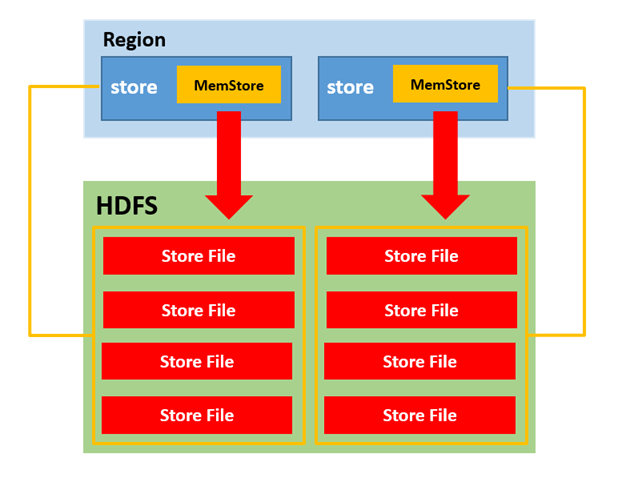
所有的flush都是以Region为单位刷新
1)MemStore级别
当 Region中
某个 MemStore 的大小达到了hbase.hregion.memstore.flush.size(默认值128M),会触发Region的刷写(若Region中有多个Store,只要有其中一个达到hbase.hregion.memstore.flush.size(默认值128M)值,就会触发flush,每个Store都会生成一个StroeFile文件,可能会生成多个小文件,所以一般情况下,一个Region只设置一个列簇(即一个Store))
2)Region级别
当处于写高峰的时候,会延迟触发第一个时机(MemStore级别)
当 Region 中的MemStore的总大小达到了hbase.hregion.memstore.flush.size(默认值128M)* hbase.hregion.memstore.block.multiplier(默认值4)时,会阻塞所有写入该 Region 的写请求,优先flush!这时候如果往 MemStore 写数据,会出现 RegionTooBusyException 异常。
例子:当 Region 中的某个 MemStore 占用内存达到128M ,会触发flush ,此时是允许写入操作的;若写入操作大于 flush 的速度,当 Region 中的所有 MemStore 占用内存达到 128 * 4 = 512M 时,阻止所有写入该 Region 的写请求,直到Region 中的所有 MemStore ,flush完毕,才取消阻塞,允许写入。
3)RegionServer级别
当RegionServer中,所有Region中的MemStore的总大小达到java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)* hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)会flush,flush的时候根据每个Region中,总MemStore占用的大小进行降序排序,依次flush;flush的时候优先flush占用空间大的region,每flush一个region,会查看总的占用大小是否小于 java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)* hbase.regionserver.global.memstore.size.lower.limit(默认值0.95);如果还是大于,则继续flush region,若小于,则停止flush(注:此情况是允许memStore写入的)
当处于写高峰的时候,会延迟触发第三个时机(HRegionServer级别)
当RegionServer中,所有Region中的MemStore的总大小达到了 java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)时,会阻塞当前 RegionServer 的所有写请求(无法往Region中的MemStore写入数据),直到RegionServer中,所有Region中的MemStore的总大小
低于 java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)* hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)时,才取消阻塞(允许写入数据)
例子,如果 HBase 堆内存总共是 10G,按照默认的比例,那么触发 RegionServer级别的flush ,是 RegionServer 中所有的 MemStore 占用内存为:10 * 0.4 * 0.95 = 3.8G时触发flush,此时是允许写入操作的,若写入操作大于flush的速度,当占用内存达到 10 * 0.4 = 4G 时,阻止所有写入操作,直到占用内存低于 3.8G ,才取消阻塞,允许写入。
4)HLog级别
当WAL文件的数量超过hbase.regionserver.maxlogs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.maxlogs以下(该属性名已经废弃,现无需手动设置,最大值为32)。WAL 数量触发的刷写策略是,找到最旧的 un-archived WAL 文件,并找到这个 WAL 文件对应的 Regions,
然后对这些 Regions 进行刷写。
5)定期刷写
到达自动刷写的时间,也会触发MemStore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时),指的是当前 MemStore 1小时会进行一次刷写。如果设定为0,则关闭定时自动刷写。
6)手动刷写
可以通过 shell 命令"flush 'table'"或者"flush 'regionname'"分别对一个Region或者多个Region进行flush
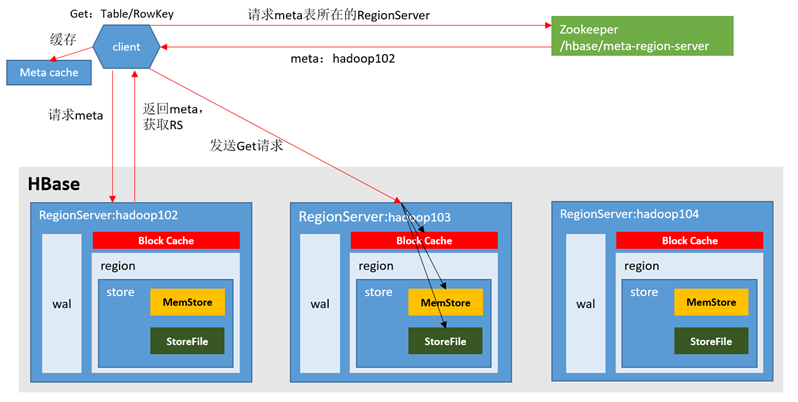
读流程
- 整体流程
- Merge细节
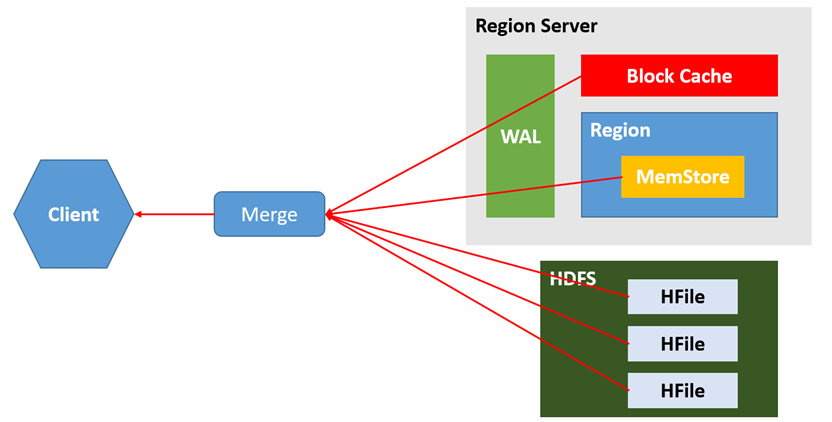
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)分别在MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5)将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
6)将合并后的最终结果返回给客户端。
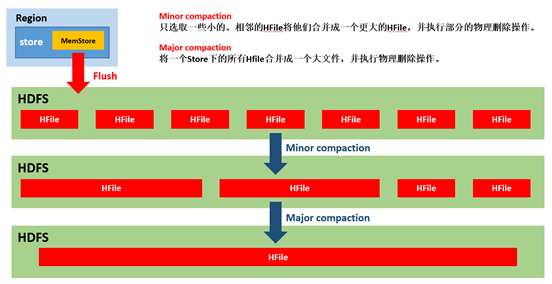
StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据。
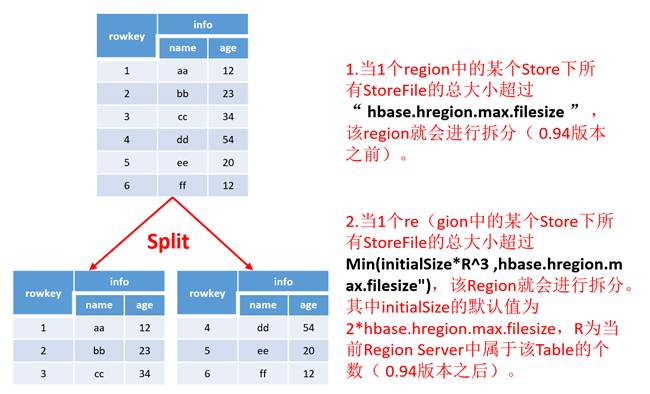
Region Split
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
Region Split时机:
1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,该Region就会进行拆分(0.94版本之前)。
2.当1个region中的某个Store下所有StoreFile的总大小超过Min(initialSize*R^3 ,hbase.hregion.max.filesize"),该Region就会进行拆分。其中initialSize的默认值为2*hbase.hregion.memstore.flush.size,R为当前Region Server中属于该Table的Region个数(0.94版本之后)。
具体的切分策略为:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了。
3.Hbase 2.0引入了新的split策略:如果当前RegionServer上该表只有一个Region,按照2 * hbase.hregion.memstore.flush.size分裂,否则按照hbase.hregion.max.filesize分裂。
HBase详解(03) - HBase架构和数据读写流程的更多相关文章
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- [转帖]HBase详解(很全面)
HBase详解(很全面) very long story 简单看了一遍 很多不明白的地方.. 2018-06-08 16:12:32 卢子墨 阅读数 34857更多 分类专栏: HBase [转自 ...
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- 《Android游戏开发详解》一1.7 控制流程第1部分——if和else语句
本节书摘来异步社区<Android游戏开发详解>一书中的第1章,第1.7节,译者: 李强 责编: 陈冀康,更多章节内容可以访问云栖社区"异步社区"公众号查看. 1.7 ...
- 大数据学习day11------hbase_day01----1. zk的监控机制,2动态感知服务上下线案例 3.HDFS-HA的高可用基本的工作原理 4. HDFS-HA的配置详解 5. HBASE(简介,安装,shell客户端,java客户端)
1. ZK的监控机制 1.1 监听数据的变化 (1)监听一次 public class ChangeDataWacher { public static void main(String[] arg ...
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- HBase详解
1. hbase简介 1.1. 什么是hbase HBASE是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群. H ...
- Hive集成HBase详解
摘要 Hive提供了与HBase的集成,使得能够在HBase表上使用HQL语句进行查询 插入操作以及进行Join和Union等复杂查询 应用场景 1. 将ETL操作的数据存入HBase 2. HB ...
- Hadoop之Hbase详解
1.什么是Hbase HBASE是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统, hbase是列式的分布式数据库 1.2.HBASE优势: 1)线性扩展,随着数据量增多可以通过节点扩展进行支撑 ...
- HBase数据读写流程(1.3.1)
===数据写入流程=== 源码:https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/ha ...
随机推荐
- springboot H2 linux下搭建使用
这次研究是H2数据库了,关键还是再Linux下进行搭建部署的,被这个数据库快弄死了弄了4天时间,现在大致可以用了,还有些细节需要修正. 我这边使用的是springboot集成模式.直接使用代码启停方式 ...
- 运行eeui项目不出现 WiFI真机同步 IP地址
从git上 clone项目之后,安装依赖 npm install eeui环境配置 npm install eeui-cli -g 问题:npm run dev 后项目一直不出现 WiFI真 ...
- 跨平台客户端Blazor方案尝试
一.方案选择 Electron/MAUI + Blazor(AntDesgin blazor) BlazorApp:Blazor Razor页面层,抽象独立层,被BlazorAppElectron/B ...
- Sublime Text - Linux Package Manager Repositories
Linux Package Manager Repositories http://www.sublimetext.com/docs/linux_repositories.html Sublime T ...
- 二、.Net Core搭建Ocelot
上一篇文章介绍了Ocelot的基本概念:https://www.cnblogs.com/yangleiyu/p/15043762.html 本文介绍在.net core中如何使用ocelot. Oce ...
- xlwings 模块总结
基本使用 在子线程中使用时,有时需要在子线程函数中加入以下.有时不需要加入,目前还不明白具体的原因 import pythoncom # 导入的库 pythoncom.CoInitialize() # ...
- Golang 实现时间戳和时间的转化
何为时间戳: 时间戳是使用数字签名技术产生的数据,签名的对象包括了原始文件信息.签名参数.签名时间等信息.时间戳系统用来产生和管理时间戳,对签名对象进行数字签名产生时间戳,以证明原始文件在签名时间之前 ...
- Oracle收集统计信息的一些思考
一.问题 Oracle在收集统计信息时默认的采样比例是DBMS_STATS.AUTO_SAMPLE_SIZE,那么AUTO_SAMPLE_SIZE的值具体是多少? 假设采样比例为10%,那么在计算单个 ...
- spring源码解析(一) 环境搭建(各种坑的解决办法)
上次搭建spring源码的环境还是两年前,依稀记得那时候也是一顿折腾,奈何当时没有记录,导致两年后的今天把坑重踩了一遍,还遇到了新的坑,真是欲哭无泪;为了以后类似的事情不再发生,这次写下这篇博文来必坑 ...
- Perl printf 函数
转载 Perl printf 函数