论文解读(Graph-MLP)《Graph-MLP: Node Classification without Message Passing in Graph》
论文信息
论文标题:Graph-MLP: Node Classification without Message Passing in Graph
论文作者:Yang Hu, Haoxuan You, Zhecan Wang, Zhicheng Wang,Erjin Zhou, Yue Gao
论文来源:2021, ArXiv
论文地址:download
论文代码:download
1 介绍
本文工作:
不使用基于消息传递模块的GNNs,取而代之的是使用Graph-MLP:一个仅在计算损失时考虑结构信息的MLP。
任务:节点分类。在这个任务中,将由标记和未标记节点组成的图输入到一个模型中,输出是未标记节点的预测。
2 方法
2.1 GNN 框架
普通的 GNN 框架:
$\mathbf{X}^{(l+1)}=\sigma\left(\widehat{A} \mathbf{X}^{(l)} W^{(l)}\right)\quad\quad\quad(1)$
$\widehat{A}=\mathbf{D}^{-\frac{1}{2}}(A+I) \mathbf{D}^{-\frac{1}{2}}\quad\quad\quad(2)$
2.2 Graph-MLP
整体框架如下:
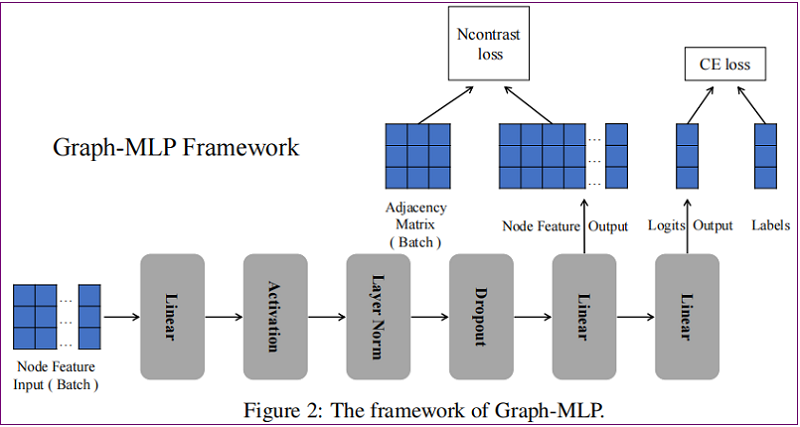
2.2.1 MLP-based Structure
结构: linear-activation-layer normalization-dropout-linear-linear
即:
$\begin{array}{c} \mathbf{X}^{(1)}=\text { Dropout }\left(L N\left(\sigma\left(\mathbf{X} W^{0}\right)\right)\right) \quad\quad\quad(3)\\ \mathbf{Z}=\mathbf{X}^{(1)} W^{1} \quad\quad\quad(4)\\ \mathbf{Y}=\mathbf{Z} W^{2}\quad\quad\quad(5) \end{array}$
其中:$Z$ 用于 NConterast 损失,$ Y$ 用于分类损失。
2.2.2 Neighbouring Contrastive Loss
在 NContast 损失中,每个节点的 $\text{r-hop}$ 邻居为正样本,其他节点为负样本。这种损失鼓励正样本更接近目标节点,并根据特征距离推动负样本远离目标节点。采样 $B$ 个邻居,第 $i$ 个节点的 NContrast loss 可以表述为:
${\large \ell_{i}=-\log \frac{\sum\limits _{j=1}^{B} \mathbf{1}_{[j \neq i]} \gamma_{i j} \exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{j}\right) / \tau\right)}{\sum\limits _{k=1}^{B} \mathbf{1}_{[k \neq i]} \exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{k}\right) / \tau\right)}} \quad\quad\quad(6)$
其中:$\gamma_{i j} $ 表示节点 $i$ 和节点 $j$ 之间的连接强度,这里定义为 $\gamma_{i j}=\widehat{A}_{i j}^{r}$。
$\gamma_{i j}$ 为非 $0$ 值当且仅当结点 $j$ 是结点 $i$ 的 $r$ 跳邻居,即:
$\gamma_{i j}\left\{\begin{array}{ll}=0, & \text { node } j \text { is the } r \text {-hop neighbor of node } i \\\neq 0, & \text { node } j \text { is not the } r \text {-hop neighbor of node } i \end{array}\right.$
而分类损失采用的是传统的交叉熵(用 $loss_{NC}$ 表示 ),因此综上所述Graph-MLP的总损失函数如下:
$\begin{aligned}\operatorname{loss}_{N C} &=\alpha \frac{1}{B} \sum\limits _{i=1}^{B} \ell_{i}\quad\quad\quad(7)\\\text { loss }_{\text {final }} &=\operatorname{loss}_{C E}+\operatorname{loss}_{N C}\quad\quad\quad(8) \end{aligned}$
2.2.3 Training
整个模型以端到端的方式进行训练。我们的模型不需要使用邻接矩阵,在计算训练期间的损失时只参考图结构信息。
在每个 $batch$ 中,我们随机抽取 $B$ 个节点并取相应的邻接信息 $\widehat{A} \in \mathbb{R}^{B \times B}$,和节点特征 $\mathbf{X} \in R^{\mathbb{R} \times d}$。对于某些节点 $i$,由于 $batch$ 抽样的随机性,可能会发生 $batch$ 中没有 positive samples。在这种情况下,将删除节点 $i$ 的损失。我们发现我们的模型对 positive samples 和 negative samples 的比例是稳健的,而没有特别调整的比例。
我们的算法如 Algorithm 1 所示:

2.2.4 Inference
在推断过程中,传统的图模型如 GNN 同时需要邻接矩阵和节点特征作为输入。不同的是,我们基于MLP的方法只需要节点特征作为输入。因此,当邻接信息被损坏或丢失时,Graph-MLP仍然可以提供一致可靠的结果。在传统的图建模中,图信息被嵌入到输入的邻接矩阵中。对于这些模型,图节点转换的学习严重依赖于内部消息传递,而内部消息传递对每个邻接矩阵输入中的连接都很敏感。然而,我们对图形结构的监督是应用于损失水平的。因此,我们的框架能够在节点特征转换过程中学习一个图结构的分布,而不需要进行前馈消息传递。这使得我们的模型在推理过程中对特定连接的敏感性较低。
3 实验
3.1 数据集

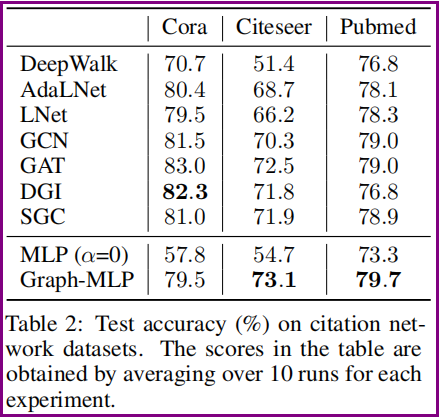
3.2 对引文网络节点分类数据集的性能
3.3 Graph-MLP 与 GNN 的效率

3.4 关于超参数的消融术研究

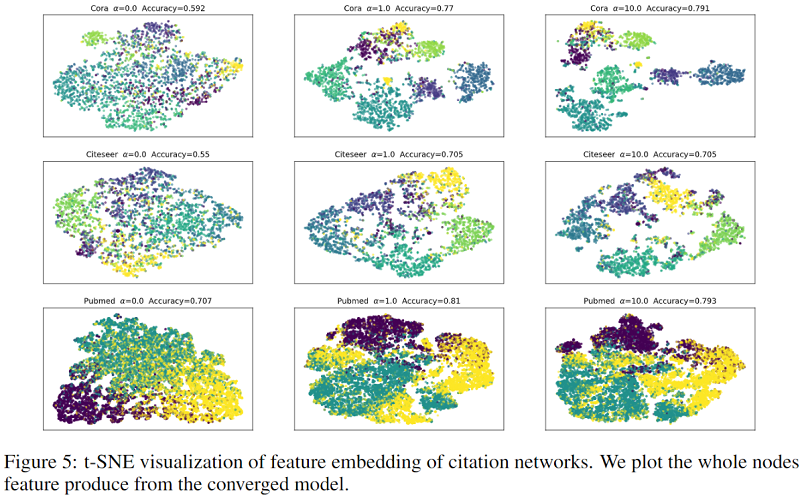
3.5 嵌入的可视化
3.6 鲁棒性
为了证明Graph-MLP在缺失连接下进行推断仍具有良好的鲁棒性,作者在测试过程中的邻接矩阵中添加了噪声,缺失连接的邻接矩阵的计算公式如下:
$A_{\text {corr }}=A \otimes mask +(1- mask ) \otimes \mathbb{N} \quad\quad\quad(9)$
$\operatorname{mask}\left\{\begin{array}{ll} =1, & p=1-\delta \\ =0, & p=\delta \end{array}\right.\quad\quad\quad(10)$
其中 $\delta$ 表示缺失率,$mask \in n \times n$ 决定邻接矩阵中缺失的位置,$mask$ 中的元素取 $1 / 0$ 的概率为 $1-\delta / \delta$ 。 $\mathbb{N} \in n \times n$ 中的元素取 $1 / 0$ 的 概率都为 $0.5$ 。

结论:从上图可以看出随着缺失率的增加,GCN的推断性能急剧下降,而Graph-MLP却基本不受影响。
论文解读(Graph-MLP)《Graph-MLP: Node Classification without Message Passing in Graph》的更多相关文章
- 论文解读(GraphSMOTE)《GraphSMOTE: Imbalanced Node Classification on Graphs with Graph Neural Networks》
论文信息 论文标题:GraphSMOTE: Imbalanced Node Classification on Graphs with Graph Neural Networks论文作者:Tianxi ...
- 论文解读(DropEdge)《DropEdge: Towards Deep Graph Convolutional Networks on Node Classification》
论文信息 论文标题:DropEdge: Towards Deep Graph Convolutional Networks on Node Classification论文作者:Yu Rong, We ...
- 论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息 论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning ...
- 论文解读( N2N)《Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization》
论文信息 论文标题:Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximiz ...
- 论文解读(soft-mask GNN)《Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks》
论文信息 论文标题:Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks论文作者:Mingqi Yang, Ya ...
- 论文解读(Graphormer)《Do Transformers Really Perform Bad for Graph Representation?》
论文信息 论文标题:Do Transformers Really Perform Bad for Graph Representation?论文作者:Chengxuan Ying, Tianle Ca ...
- 论文解读(SEP)《Structural Entropy Guided Graph Hierarchical Pooling》
论文信息 论文标题:Structural Entropy Guided Graph Hierarchical Pooling论文作者:Junran Wu, Xueyuan Chen, Ke Xu, S ...
- 论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
论文信息 论文标题:Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering论文作者:Chaki ...
- 论文解读(GraphMAE)《GraphMAE: Self-Supervised Masked Graph Autoencoders》
论文信息 论文标题:GraphMAE: Self-Supervised Masked Graph Autoencoders论文作者:Zhenyu Hou, Xiao Liu, Yukuo Cen, Y ...
随机推荐
- Java有了synchronized,为什么还要提供Lock
摘要:在Java中提供了synchronized关键字来保证只有一个线程能够访问同步代码块.既然已经提供了synchronized关键字,那为何在Java的SDK包中,还会提供Lock接口呢? 本文分 ...
- java方法学习
java方法学习 方法概念 什么是方法 方法就是完成某些事情的过程,如:实现两个数相加,用方法add(数值1,数值2). 1.System.out.print(),System是系统的一个类,out是 ...
- LGP3092题解
看 DP 的时候翻到的题,发现这题的坑鸽子了一年半 这个状态感觉比较厉害,还是来记录一下吧. 首先硬币数量很少让我们想到状压,可以想出来一个十分 navie 的状态:\(dp[S][n]\) 表示用过 ...
- Java数组(Array)和列表(ArryList)有什么区别?
Array和ArryList的不同点 Array可以包含基本类型和对象类型,ArrayList只能包含对象类型 Array大小是固定的,ArrayList的大小动态变化的 ArrayList提供了更多 ...
- mysql(mariadb)安装
mysql(mariadb)安装 前言 MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可. 开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将My ...
- [源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache 目录 [源码解析] TensorFlow 分布式环境(4) --- WorkerCache 1. WorkerCa ...
- 常用写法java
迭代器遍历[List.Set.Map] 遍历List方法一:普通for循环 1 for(int i=0;i<list.size();i++){//list为集合的对象名 2 String tem ...
- Mybatis 是如何进行分页的?分页插件的原理是什么?
Mybatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内 存分页,而非物理分页.可以在 sql 内直接书写带有物理分页的参数来完成物理分 页功能,也可以使用 ...
- SpringDataRedis的Keyspaces设置
前言 原文:https://docs.spring.io/spring-data/redis/docs/2.3.2.RELEASE/reference/html/#redis.repositories ...
- 请说出作用域public,private,protected,以及不写时的区别?
这四个作用域的可见范围如下表所示.说明:如果在修饰的元素上面没有写任何访问修饰符,则表示friendly.作用域 当前类 同一package 子孙类 其他packagepublic ...