Java - HashTable源码分析
java提高篇(二五)-----HashTable
在java中与有两个类都提供了一个多种用途的hashTable机制,他们都可以将可以key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相对应的value值。一个是前面提到的HashMap,还有一个就是马上要讲解的HashTable。对于HashTable而言,它在很大程度上和HashMap的实现差不多,如果我们对HashMap比较了解的话,对HashTable的认知会提高很大的帮助。他们两者之间只存在几点的不同,这个后面会阐述。
一、定义
HashTable在Java中的定义如下:
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable
从中可以看出HashTable继承Dictionary类,实现Map接口。其中Dictionary类是任何可将键映射到相应值的类(如 Hashtable)的抽象父类。每个键和每个值都是一个对象。在任何一个 Dictionary 对象中,每个键至多与一个值相关联。Map是"key-value键值对"接口。
HashTable采用"拉链法"实现哈希表,它定义了几个重要的参数:table、count、threshold、loadFactor、modCount。
table:为一个Entry[]数组类型,Entry代表了“拉链”的节点,每一个Entry代表了一个键值对,哈希表的"key-value键值对"都是存储在Entry数组中的。
count:HashTable的大小,注意这个大小并不是HashTable的容器大小,而是他所包含Entry键值对的数量。
threshold:Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor:加载因子。
modCount:用来实现“fail-fast”机制的(也就是快速失败)。所谓快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到迭代完成之后才告诉你(你已经出错了)。
三、主要方法
HashTable的API对外提供了许多方法,这些方法能够很好帮助我们操作HashTable,但是这里我只介绍两个最根本的方法:put、get。
首先我们先看put方法:将指定 key 映射到此哈希表中的指定 value。注意这里键key和值value都不可为空。
public synchronized V put(K key, V value) {
// Make sure the value is not null确保value不为null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
//确保key不在hashtable中
//首先,通过hash方法计算key的哈希值,并计算得出index值,确定其在table[]中的位置
//其次,迭代index索引位置的链表,如果该位置处的链表存在相同的key,则替换value,返回旧的value
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
//如果超过阀值,就进行rehash操作
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
//将值插入,返回的为null
Entry<K,V> e = tab[index];
// 创建新的Entry节点,并将新的Entry插入Hashtable的index位置,并设置e为新的Entry的下一个元素
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表(我们暂且理解为链表),若该链表中存在一个这个的key对象,那么就直接替换其value值即可,否则在将改key-value节点插入该index索引位置处。如下:
首先我们假设一个容量为5的table,存在8、10、13、16、17、21。他们在table中位置如下:
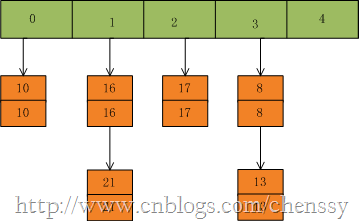
然后我们插入一个数:put(16,22),key=16在table的索引位置为1,同时在1索引位置有两个数,程序对该“链表”进行迭代,发现存在一个key=16,这时要做的工作就是用newValue=22替换oldValue16,并将oldValue=16返回。
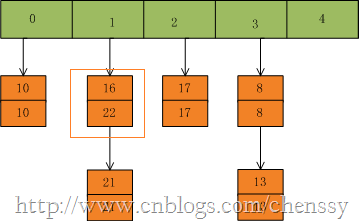
在put(33,33),key=33所在的索引位置为3,并且在该链表中也没有存在某个key=33的节点,所以就将该节点插入该链表的第一个位置。
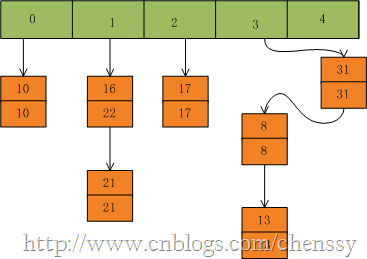
在HashTabled的put方法中有两个地方需要注意:
1、HashTable的扩容操作,在put方法中,如果需要向table[]中添加Entry元素,会首先进行容量校验,如果容量已经达到了阀值,HashTable就会进行扩容处理rehash()
在这个rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素一一复制到新的HashTable中,这个过程是比较消耗时间的,同时还需要重新计算hashSeed的,毕竟容量已经变了。这里对阀值啰嗦一下:比如初始值11、加载因子默认0.75,那么这个时候阀值threshold=8,当容器中的元素达到8时,HashTable进行一次扩容操作,容量 = 8 * 2 + 1 =17,而阀值threshold=17*0.75 = 13,当容器元素再一次达到阀值时,HashTable还会进行扩容操作,一次类推。
2、其实这里是我的一个疑问,在计算索引位置index时,HashTable进行了一个与运算过程(hash & 0x7FFFFFFF),为什么需要做一步操作,这么做有什么好处?如果哪位知道,望指导,LZ不胜感激!!下面是计算key的hash值,这里hashSeed发挥了作用。
相对于put方法,get方法就会比较简单,处理过程就是计算key的hash值,判断在table数组中的索引位置,然后迭代链表,匹配直到找到相对应key的value,若没有找到返回null。
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
Hashtable 遍历方式
Hashtable 有多种遍历方式:
//1、使用keys()
Enumeration<String> en1 = table.keys();
while(en1.hasMoreElements()) {
en1.nextElement();
} //2、使用elements()
Enumeration<String> en2 = table.elements();
while(en2.hasMoreElements()) {
en2.nextElement();
} //3、使用keySet()
Iterator<String> it1 = table.keySet().iterator();
while(it1.hasNext()) {
it1.next();
} //4、使用entrySet()
Iterator<Entry<String, String>> it2 = table.entrySet().iterator();
while(it2.hasNext()) {
it2.next();
}
四、HashTable与HashMap的区别
HashTable和HashMap存在很多的相同点,但是他们还是有几个比较重要的不同点。
第一:我们从他们的定义就可以看出他们的不同,HashTable基于Dictionary类,而HashMap是基于AbstractMap。Dictionary是什么?它是任何可将键映射到相应值的类的抽象父类,而AbstractMap是基于Map接口的骨干实现,它以最大限度地减少实现此接口所需的工作。
第二:HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null。如下:
当HashMap遇到为null的key时,它会调用putForNullKey方法来进行处理。对于value没有进行任何处理,只要是对象都可以。
而当HashTable遇到null时,他会直接抛出NullPointerException异常信息。
第三:Hashtable的方法是同步的,而HashMap的方法不是。所以有人一般都建议如果是涉及到多线程同步时采用HashTable,没有涉及就采用HashMap,但是在Collections类中存在一个静态方法:synchronizedMap(),该方法创建了一个线程安全的Map对象,并把它作为一个封装的对象来返回,所以通过Collections类的synchronizedMap方法是可以我们你同步访问潜在的HashMap。这样君该如何选择呢???
Java - HashTable源码分析的更多相关文章
- Java入门系列之集合Hashtable源码分析(十一)
前言 上一节我们实现了散列算法并对冲突解决我们使用了开放地址法和链地址法两种方式,本节我们来详细分析源码,看看源码中对于冲突是使用的哪一种方式以及对比我们所实现的,有哪些可以进行改造的地方. Hash ...
- 并发-HashMap和HashTable源码分析
HashMap和HashTable源码分析 参考: https://blog.csdn.net/luanlouis/article/details/41576373 http://www.cnblog ...
- Java 集合源码分析(一)HashMap
目录 Java 集合源码分析(一)HashMap 1. 概要 2. JDK 7 的 HashMap 3. JDK 1.8 的 HashMap 4. Hashtable 5. JDK 1.7 的 Con ...
- 史上最简单的的HashTable源码分析
HashTable源码分析 1.前言 Hashtable 一个元老级的集合类,早在 JDK 1.0 就诞生了 1.1.摘要 在集合系列的第一章,咱们了解到,Map 的实现类有 HashMap.Link ...
- Java Reference 源码分析
@(Java)[Reference] Java Reference 源码分析 Reference对象封装了其它对象的引用,可以和普通的对象一样操作,在一定的限制条件下,支持和垃圾收集器的交互.即可以使 ...
- java集合源码分析(三):ArrayList
概述 在前文:java集合源码分析(二):List与AbstractList 和 java集合源码分析(一):Collection 与 AbstractCollection 中,我们大致了解了从 Co ...
- java集合源码分析(六):HashMap
概述 HashMap 是 Map 接口下一个线程不安全的,基于哈希表的实现类.由于他解决哈希冲突的方式是分离链表法,也就是拉链法,因此他的数据结构是数组+链表,在 JDK8 以后,当哈希冲突严重时,H ...
- [Java] Hashtable 源码简要分析
Hashtable /HashMap / LinkedHashMap 概述 * Hashtable比较早,是线程安全的哈希映射表.内部采用Entry[]数组,每个Entry均可作为链表的头,用来解决冲 ...
- JAVA的HashTable源码分析
Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长.Hashtable ...
随机推荐
- C# json字符串转为对象
方法1: using System.Web.Script.Serialization; string ss = "{\"NewsCount\":\"3482\& ...
- Effective C++笔记:继承与面向对象设计
关于OOP 博客地址:http://www.cnblogs.com/ronny 转载请注明出处! 1,继承可以是单一继承或多重继承,每一个继承连接可以是public.protected或private ...
- 获取当前人IP地址
/*** 获取访问的IP地址* @date 2018年11月26日上午11:31:49* @user : taoshao* @param request* @return*/public String ...
- Linux Shell常用脚本整理
轮询检测Apache状态并启用钉钉报警◆ #!/bin/bash shell_user="root" shell_domain="apache" shell_l ...
- RabbitMQ在mac上的安装
1.官网下载rabbitmq-server-3.6.3, 地址http://www.rabbitmq.com/install-standalone-mac.html.2.tar -zxvf rabbi ...
- 安装fastdfs文件系统
1.下载源码包 需要下载的源码包: fastDFS源代码:FastDFS_v5.01.tar.gz fastDFS的nginx模块源代码:fastdfs-nginx-module_v1.15.tar. ...
- [Vue] vue-cli3.0安装
1. node.js安装https://nodejs.org/en/download/ 2.npm的安装 由于新版的nodejs已经集成了npm,所以之前npm也一并安装好了.同样可以通过输入 &qu ...
- mybatis四大接口之 ParameterHandler
1. 继承结构 只有一个默认的实现类 2. ParameterHandler 获取参数对象: 设置参数对象: public interface ParameterHandler { Object g ...
- Python小白学习之路(二十四)—【装饰器】
装饰器 一.装饰器的本质 装饰器的本质就是函数,功能就是为其他函数添加附加功能. 利用装饰器给其他函数添加附加功能时的原则: 1.不能修改被修饰函数的源代码 2.不能修改被修饰函数的调用 ...
- Dell R730服务器 Raid5配置
Dell R730服务器,有7块5t硬盘,默认做的RAID5.我们的目的是取其中6块硬盘做RAID5,留一块硬盘做热备. 一块SSD系统盘. 在这里,我具体解释一下 ①6块硬盘做成RAID5 ②6块硬 ...