使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息
转载请注明出处。
爬取目标:每个电影的评分、名称、时长、主演、和类型
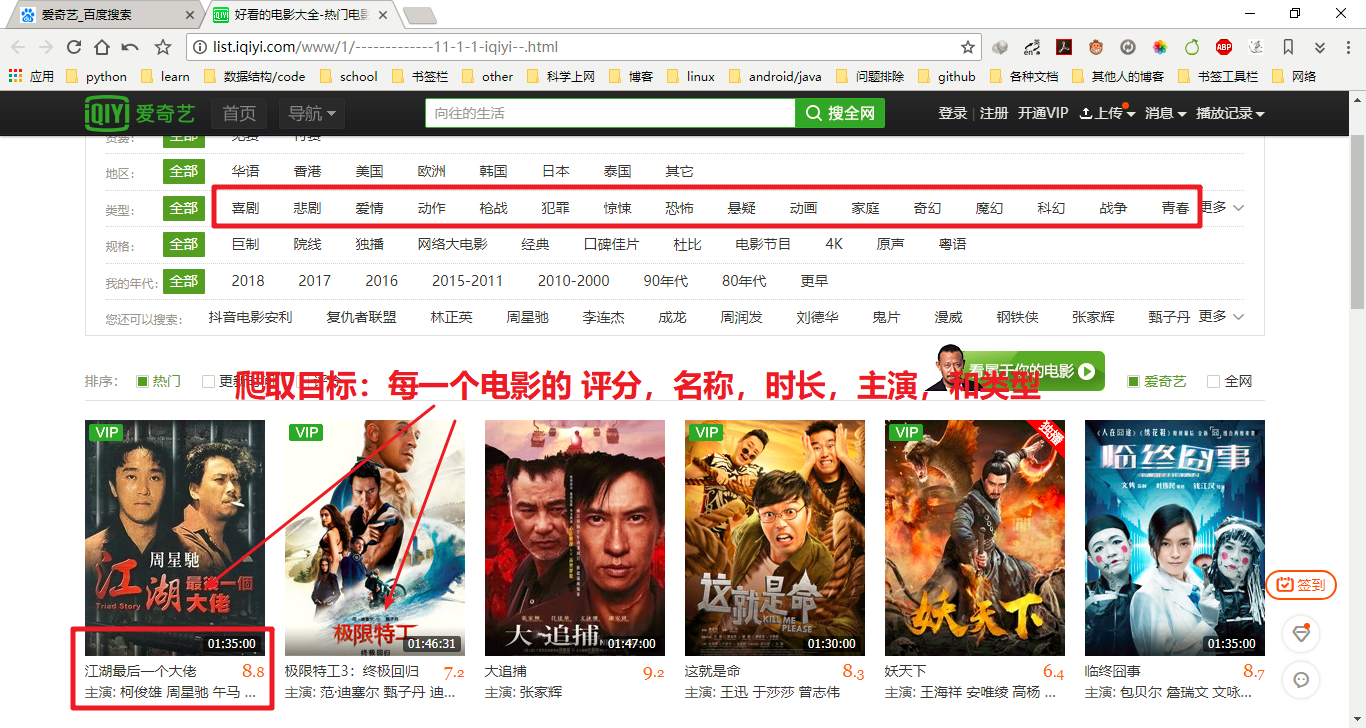
爬取思路:
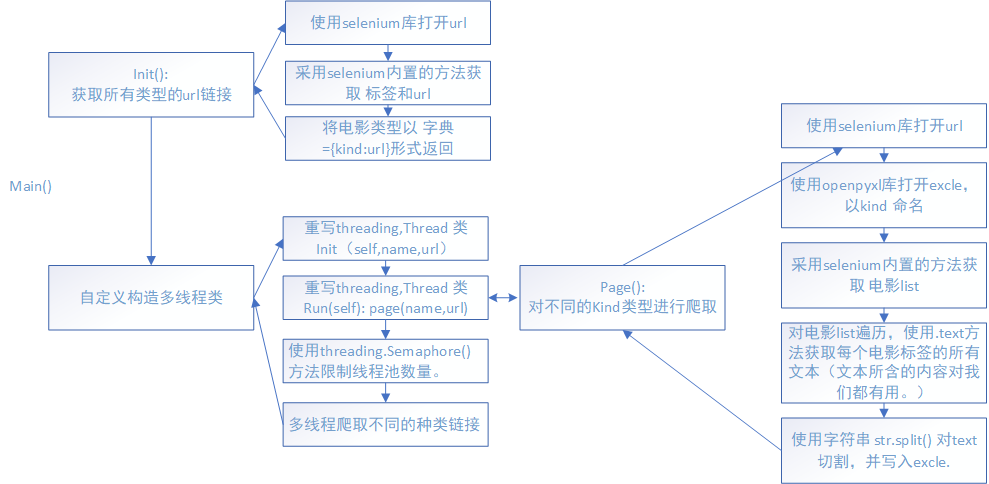
源文件:(有注释)
from selenium import webdriver
from threading import Thread
import threading
import time
import openpyxl #操作excel
#爱奇艺的看电影的url 不是首页。
url='http://list.iqiyi.com/www/1/-8------------11-1-1-iqiyi--.html'
#自定义一个线程类 实现多线程爬取
class M_Thread(Thread):
def __init__(self,name1,url):
Thread.__init__(self)
self.url=url
self.name1=name1
def run(self):
self.kind_movie=page(self.name1,self.url)
#page运行完后lock进行 让 当前movie 结束
# 初始化爬虫,从url中爬爬取各个种类相对于的连接。
def init():
# 浏览器 无界面 和有界面。
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.set_headless()
Brower = webdriver.Firefox(firefox_options=fireFoxOptions)
# Brower = webdriver.Firefox()
Brower.get(url)
#定位到种类标签 (发现不用Xpath容易出错)
kind=Brower.find_element_by_xpath("/html/body/div[3]/div/div/div[1]/div[4]/ul")
#a标签就是那个 连接
kinds=kind.find_elements_by_tag_name("a")
#将每个类型的页面连接储存到kinds_dict中
movie_kind_link={}
for a in kinds:
try:
if(a.text=="全部" or a.text==""): #去掉 全部类型 和一个空类型。
continue
movie_kind_link[a.text] = a.get_attribute("href")
except:
print("error!")
continue
Brower.close()
return movie_kind_link #返回的是 种类:url 字典。
def page(name,link):
#每一个种类 都打开一个excle储存
wordbook=openpyxl.Workbook()
sheet1=wordbook.active
num=1
#初始化excle第一行
for qwe in ["电影名","时长","评分","类型","演员"]:
sheet1.cell(row=1,column=num,value=qwe)
num+=1
num=2
#本来一开始是用txt写的但是布局太丑。 优点是速度快!
# 采用过 用数据库存 ,但是同时写入大量数据 总是会出莫名奇妙的错误。暂时没解决
# file=open(name+".txt","w",encoding="utf-8")
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.set_headless()
Br = webdriver.Firefox(firefox_options=fireFoxOptions)
# Br = webdriver.Firefox()
# try:
Br.get(link)
print("正在打开 %s 页面"%name)
page = Br.find_element_by_class_name("mod-page")
page_href=[]
for aa in page.find_elements_by_tag_name("a"):
page_href.append(aa.get_attribute("href"))
for cc in page_href:
print("*****正在爬取 {} 的第 {} 页*****".format(name,page_href.index(cc)+1))
# time.sleep(1)
# 第一页不用重新打开
if(page_href.index(cc)!=0):
Br.get(cc)
#movie 即当前页面的 电影tag 列表
movie=Br.find_element_by_class_name("wrapper-piclist").find_elements_by_tag_name("li")
for bb in movie:
# try:
things=bb.text.split("\n")
"""
这里为什么要区分?
爱奇艺很垃圾,有点电影评分不给,
但是在直接获取text在if判断和分元素去获取四个属性,我觉得还是if好用。
"""
if(len(things)==4):
sheet1.cell(row=num, column=1, value=things[2])
sheet1.cell(row=num, column=2, value=things[0])
sheet1.cell(row=num, column=3, value=things[1])
sheet1.cell(row=num, column=4, value=name)
sheet1.cell(row=num, column=5, value=things[3])
num+=1
elif (len(things) == 3):
sheet1.cell(row=num, column=1, value=things[1])
sheet1.cell(row=num, column=2, value="*")
sheet1.cell(row=num, column=3, value=things[0])
sheet1.cell(row=num, column=4, value=name)
sheet1.cell(row=num, column=5, value=things[2])
num +=1
else:
print("error (moive)")
# break
Lock_thread.release() # 解锁
wordbook.save(name+".xlsx")
Br.close()
if __name__=="__main__":
#控制线程最大数量为3
Lock_thread= threading.Semaphore(3) #控制线程数为3
#kind:link
dict=init()
# print(dict)
#多线程爬取
for name1,link in dict.items():
Lock_thread.acquire() #枷锁 ,在每一个page()运行完后解锁
thread_live=M_Thread(name1,link)
print(name1," begin")
thread_live.start()
time.sleep(3)
使用selenium 多线程爬取爱奇艺电影信息的更多相关文章
- Python爬取爱奇艺资源
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素“ ...
- 如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7 思路: 1.先选取你要爬取的电影 2.用vip解析工具解析,获取地址 3.写好脚本,下载片断 4.将片断利用电脑合成 需要的python模块: ##第一 ...
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- Python 爬虫实例(5)—— 爬取爱奇艺视频电视剧的链接(2017-06-30 10:37)
1. 我们找到 爱奇艺电视剧的链接地址 http://list.iqiyi.com/www/2/-------------11-1-1-iqiyi--.html 我们点击翻页发现爱奇艺的链接是这样的 ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 爬取爱奇艺电视剧url
----因为需要顺序,所有就用串行了---- import requests from requests.exceptions import RequestException import re im ...
- 使用Beautiful Soup爬取猫眼TOP100的电影信息
使用Beautiful Soup爬取猫眼TOP100的电影信息,将排名.图片.电影名称.演员.时间.评分等信息,提取的结果以文件形式保存下来. import time import json impo ...
- casperjs 抓取爱奇艺高清视频
CasperJS 是一个开源的导航脚本和测试工具,使用 JavaScript 基于 PhantomJS 编写,用于测试 Web 应用功能,Phantom JS是一个服务器端的 JavaScript A ...
- 爬取迷你mp4各个电影信息
网站:www.minimp4.com # coding=utf-8 import requests from lxml import etree class Minimpe_moves(object) ...
随机推荐
- noip2019集训测试赛(二十一)Problem B: 红蓝树
noip2019集训测试赛(二十一)Problem B: 红蓝树 Description 有一棵N个点,顶点标号为1到N的树.N−1条边中的第i条边连接顶点ai和bi.每条边在初始时被染成蓝色.高桥君 ...
- stm32片上ADC转换实验
原理图所示: BAT_DET 接到PB0 引脚,VSYS 是直流3.7V的电压.再来看下103的adc转换和引脚GPIO的关系 我们直接选用ADC1 根据上表格只能使用通道8 下面给我常用的ADC1寄 ...
- Mysql之rpm安装5.7版本遇见的问题
前言:环境是centos7.5的系统,用rpm方式安装mysql5.7 1.由于是centos7.5 所以需要将默认的mariadb给卸载 rpm -qa | grep mariadb 查看下是否有m ...
- 02 File类的方法练习——遍历文件夹
思路 需要遍历的文件夹 File 使用listFile列出下级文件及文件夹 判断得到的list是否为空,为空则输出当前文件夹名称 如果不为空,逐个判断是文件还是文件夹 如果是文件,输出文件名 如果是文 ...
- WUSTOJ 1305: 最短路(Java)
题目链接:
- Linux主要目录速查表
/:根目彔.一般根目录下只存放目录,在linux下有且只有一个根目彔,所有的东西都是从这里开始 当在终端里输入/home.其实是在告诉电脑,先从/(根目录)开始,再进入到honie目录 /bin./u ...
- bootstrap的tree使用
效果图: 先引用,顺序很重要 <script src="~/Content/bootstrap-table/bootstrap-table.min.js"></s ...
- elk docker-compose
version: '3.1' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:6.2.4 c ...
- springboot接收date类型参数
springboot接收日期类型参数,实现自动转换. 1. 当请求类型为json,date类型字段为 json 字段时,可以使用如下两种方法 1.1. 当前参数加两个注解(有些文章说接收只需要加 @D ...
- iOS - FMDB数据库的使用
下面不废话了直接上代码