java集合之hashMap,初始长度,高并发死锁,java8 hashMap做的性能提升
众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。
HashMap数组每一个元素的初始值都是Null。

对于HashMap,我们最常使用的是两个方法:Get 和 Put。
1.put方法的原理
比如调用 hashMap.put("apple", 0) ,插入一个Key为“apple"的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index): length表示 初始化时候,HashMap的容量
hash = Hash(“apple”)
index = hash & (length - 1)
假定最后计算出的index是2,那么结果如下:

但是,因为HashMap的长度是有限的,当插入的Entry越来越多时,再完美的Hash 函数也难免会出现index冲突的情况,比如:

这个时候该怎么办呢,我们可以利用链表来解决。
HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可:

需要注意的是,新来的Entry节点插入链表时,使用的是“头插法”。至于为什么不插入链表尾部,是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大。且插入到最后的话,那时间复杂度也会上升。
2.get方法的原理
首先会把输入的Key做一次Hash映射,得到对应的index:
hash = Hash("apple")
index = hash & (length-1)
由于刚才所说的Hash冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我们要查找的Key是“apple”:
第一步,我们查看的是头节点Entry6,Entry6的Key是banana,显然不是我们要找的结果。
第二步,我们查看的是Next节点Entry1,Entry1的Key是apple,正是我们要找的结果。
问题:
问题1:HashMap的初始长度,为什么?HashMap的最大容量?
问题2:高并发下 HashMap 可能会出现死锁?
问题3:java8中,HashMap的结构有什么样的优化?
解答:
问题1:HashM安排的初始长度,为什么?
初始长度是 16,每次扩展或者是手动初始化,长度必须是 2的幂。
因为: index = HashCode(Key) & (length - 1), 如果 length是 2的 幂的话,则 length - 1就是 全是 1的二进制数,比如 16 - 1 = 1111,这样相当于是 坐落在长度为 length的hashMap上的位置只和 HashCode的后四位有关,这只要给出的HashCode算法本身分布均匀,算出的index就是分布均匀的。
因为HashMap的key是int类型,所以最大值是2^31次方,但是查看源码,当到达 2^30次方,即
MAXIMUM_CAPACITY,之后,便不再进行扩容。
问题2:高并发情况下,为什么HashMap出现死锁?
我们看到默认HashMap的初始长度是16,比较小,每一次push的时候,都会检查当前容量是否超过 预定的 threshold,如果超过,扩大HashMap容量一倍,整个表里的所有元素都需要按照新的hash算法被算一遍,这个代价较大。提到死锁,对于HashMap来说,貌似只能和链表操作有关。
正常ReHash过程,可以看到,每个元素重新算hash值,将链表翻转(目的遍历每个bucket上的链表还是用的是头插法,时间复杂度最低),放到对应的bucket上的链表中
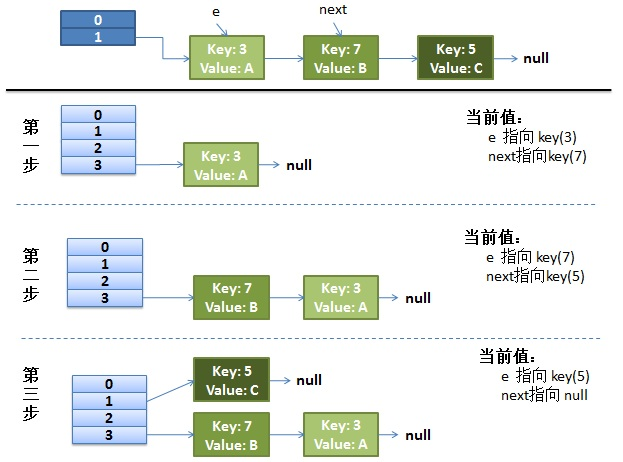
并发时候的reHash过程
while(null != e) {
Entry<K,V> next = e.next; //线程1还没有执行这句 中断了
if (rehash) {
e.hash = null == e.key ? : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}

过程:
(1)线程1,先被中断,线程2执行reHash过程
(2)线程2将原表 bucket 1 处的链表分发到 新表 bucket 1 和 bucket 3 上(hash值的后2位,第一位不同,则不是01就是11),分散到 bucket 3上的值有两个, key(3), key(7),遍历原表Bucket 1 上的 链表,采用头插法,结果就是 链表反转且还属于新表此bucket的元素放到 此bucket上。此时 key(7) -> key(3) -> null
(3)此时线程 2 被中断,线程 1调度。 此时线程 1 中 e 是 key(3)-> null
执行 next = e.next , 得到 next = null
e.next = newTable[i], e.next = key(7)->key(3)->null,所以 e是 key(3)->key(7)->key(3)
newTable[i] = e; 此时newTable[i] 就是一个 循环链表。
e = next, e是null,跳出循环
这样等到get方法到对应的链表上取数据时,就会发生 死循环。
问题3:java8对hashMap做了什么优化?
简单说: java7中 hashMap每个桶中放置的是链表,这样当hash碰撞严重时,会导致个别位置链表长度过长,从而影响性能。
java8中,HashMap 每个桶中当链表长度超过8之后,会将链表转换成红黑树,从而提升增删改查的速度。
java集合之hashMap,初始长度,高并发死锁,java8 hashMap做的性能提升的更多相关文章
- 高并发场景下System.currentTimeMillis()的性能问题的优化 以及SnowFlakeIdWorker高性能ID生成器
package xxx; import java.sql.Timestamp; import java.util.concurrent.*; import java.util.concurrent.a ...
- 高并发场景下System.currentTimeMillis()的性能问题的优化
高并发场景下System.currentTimeMillis()的性能问题的优化 package cn.ucaner.alpaca.common.util.key; import java.sql.T ...
- Java集合(十)实现Map接口的HashMap
Java集合(十)继承Map接口的HashMap 一.HashMap简介(基于JDK1.8) HashMap是基于哈希表(散列表),实现Map接口的双列集合,数据结构是“链表散列”,也就是数组+链表 ...
- Java与Netty实现高性能高并发
摘要: 1. 背景 1.1. 惊人的性能数据 最近一个圈内朋友通过私信告诉我,通过使用Netty4 + Thrift压缩二进制编解码技术,他们实现了10W TPS(1K的复杂POJO对象)的跨节点远程 ...
- java高级精讲之高并发抢红包~揭开Redis分布式集群与Lua神秘面纱
java高级精讲之高并发抢红包~揭开Redis分布式集群与Lua神秘面纱 redis数据库 Redis企业集群高级应用精品教程[图灵学院] Redis权威指南 利用redis + lua解决抢红包高并 ...
- JAVA NIO non-blocking模式实现高并发服务器(转)
原文链接:JAVA NIO non-blocking模式实现高并发服务器 Java自1.4以后,加入了新IO特性,NIO. 号称new IO. NIO带来了non-blocking特性. 这篇文章主要 ...
- JAVA NIO non-blocking模式实现高并发服务器
JAVA NIO non-blocking模式实现高并发服务器 分类: JAVA NIO2014-04-14 11:12 1912人阅读 评论(0) 收藏 举报 目录(?)[+] Java自1.4以后 ...
- Java生鲜电商平台-高并发核心技术订单与库存实战
Java生鲜电商平台-高并发核心技术订单与库存实战 一. 问题 一件商品只有100个库存,现在有1000或者更多的用户来购买,每个用户计划同时购买1个到几个不等商品. 如何保证库存在高并发的场景下是安 ...
- Java生鲜电商平台-高并发的设计与架构
Java生鲜电商平台-高并发的设计与架构 说明:源码下载Java开源生鲜电商平台以及高并发的设计与架构文档 对于高并发的场景来说,比如电商类,o2o,门户,等等互联网类的项目,缓存技术是Java项目中 ...
- Java 集合系列 07 List总结(LinkedList, ArrayList等使用场景和性能分析)
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
随机推荐
- [Java复习] Spring 常见面试问题
1. 什么是 Spring 框架?Spring 框架有哪些主要模块? 轻量级实现IoC和AOP的JavaEE框架. Core模块: bean(bean定义创建解析), context(环境, IoC容 ...
- JAVA 基础编程练习题29 【程序 29 求矩阵对角线之和】
29 [程序 29 求矩阵对角线之和] 题目:求一个 3*3 矩阵对角线元素之和 程序分析:利用双重 for 循环控制输入二维数组,再将 a[i][i]累加后输出. package cskaoyan; ...
- centos 7设置limit,不生效问题
1:记录未修改之前的ulimit值 [root@bogon ~]# ulimit -a 2:修改配置文件 vim /etc/security/limits.conf 在后面添加 * s ...
- SpringBoot: 13.异常处理方式3(使用@ControllerAdvice+@ExceptionHandle注解)(转)
问题:使用@ExceptionHandle注解需要在每一个controller代码里面都添加异常处理,会咋成代码冗余 解决方法:新建一个全局异常处理类,添加@ControllerAdvice注解即可 ...
- 移动端自动化测试之android模拟器问题集合
黑屏 在做移动端自动化测试过程中,android模拟器启动黑屏的问题一直困扰着我,网上找了许多方法尝试了都不能解决我的问题,最后重新安装了镜像文件,问题才得以解决,当然并不是网上的解决办法都是错的,只 ...
- 【POJ - 1742】Coins (多重背包)
Coins 直接翻译了 Descriptions 给出硬币面额及每种硬币的个数,求从1到m能凑出面额的个数. Input 多组数据,每组数据前两个数字为n,m.n表示硬币种类数,m为最大面额,之后前 ...
- OpenCV.物体识别
1.度娘:“OpenCV 物体识别” 1.1.opencv实时识别指定物体 - 诺花雨的博客 - CSDN博客.html(https://blog.csdn.net/qq_27063119/artic ...
- 使用js加载器动态加载外部js、css文件
let MiniSite = new Object(); /** * 判断浏览器 */ MiniSite.Browser = { ie: /msie/.test(window.navigator.us ...
- 用elasticsearchdump备份恢复数据
1.安装elastic searchdump mkdir /data/nodejs cd /data/nodejs wget https://nodejs.org/dist/v10.16.2/node ...
- 使用JQuery获取被选中的checkbox的value值
上网查了一下,感觉一些人回答得真的是不知所云,要么代码不够简便.或者是有些想装逼成分等. 以下为使用JQuery获取input checkbox被选中的值代码: <html> & ...