ML面试1000题系列(1-20)
本文总结ML面试常见的问题集
转载来源:https://blog.csdn.net/v_july_v/article/details/78121924
1、简要介绍SVM
全称是support vector machine,中文名叫支持向量机。SVM是一个面向数据的分类算法,它的目标是为确定一个分类超平面,从而将不同的数据分隔开。
扩展:这里有篇文章详尽介绍了SVM的原理、推导,《
支持向量机通俗导论(理解SVM的三层境界)》。此外,这里有个视频也是关于SVM的推导:《纯白板手推SVM》
2、简要介绍tensorflow的计算图
Tensorflow是一个通过计算图的形式来表述计算的编程系统,计算图也叫数据流图,可以把计算图看做是一种有向图,Tensorflow中的每一个节点都是计算图上的一个Tensor, 也就是张量,而节点之间的边描述了计算之间的依赖关系(定义时)和数学操作(运算时)。
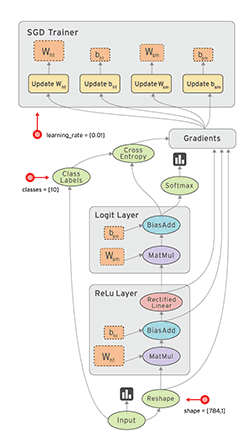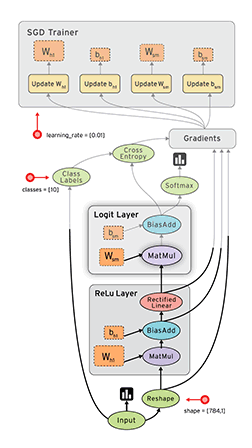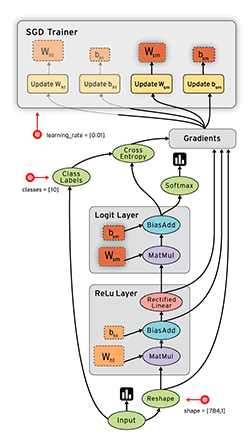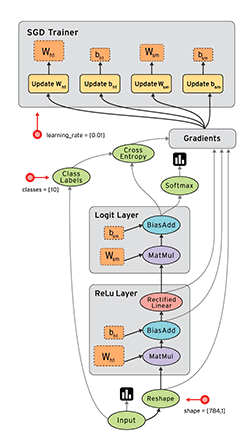
如下两图表示:
a=x*y; b=a+z; c=tf.reduce_sum(b);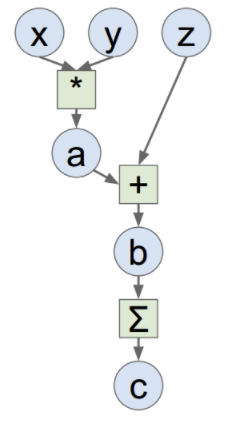
3、在k-means或kNN,我们常用欧氏距离来计算最近的邻居之间的距离,有时也用曼哈顿距离,请对比下这两种距离的差别。
- 欧氏距离,最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中,如点 x = (x1,...,xn) 和 y = (y1,...,yn) 之间的距离为:

欧氏距离虽然很有用,但也有明显的缺点。它将样品的不同属性(即各指标或各变量量纲) 之间的差别等同看待,这一点有时不能满足实际要求。例如,在教育研究中,经常遇到对人 的分析和判别,个体的不同属性对于区分个体有着不同的重要性。因此,欧氏距离适用于向量各分量的度量标准统一的情况。
- 曼哈顿距离,我们可以定义曼哈顿距离的正式意义为L1距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1, y1)的点P1与坐标(x2, y2)的点P2的曼哈顿距离为:
 ,要注意的是,曼哈顿距离依赖坐标系统的转度,而非系统在座标轴上的平移或映射。当坐标轴变动时,点间的距离就会不同。
,要注意的是,曼哈顿距离依赖坐标系统的转度,而非系统在座标轴上的平移或映射。当坐标轴变动时,点间的距离就会不同。
描述网络模型中某层的厚度,通常用名词通道channel数或者特征图feature map数。不过人们更习惯把作为数据输入的前层的厚度称之为通道数(比如RGB三色图层称为输入通道数为3),把作为卷积输出的后层的厚度称之为特征图数。
卷积核(filter)一般是3D多层的,除了面积参数, 比如3x3之外, 还有厚度参数H(2D的视为厚度1). 还有一个属性是卷积核的个数N。
卷积核的厚度H, 一般等于前层厚度M(输入通道数或feature map数). 特殊情况M > H。
卷积核的个数N, 一般等于后层厚度(后层feature maps数,因为相等所以也用N表示)。
卷积核通常从属于后层,为后层提供了各种查看前层特征的视角,这个视角是自动形成的。
卷积核厚度等于1时为2D卷积,也就是平面对应点分别相乘然后把结果加起来,相当于点积运算. 各种2D卷积动图可以看这里https://github.com/vdumoulin/conv_arithmetic

卷积核厚度大于1时为3D卷积(depth-wise),每片平面分别求2D卷积,然后把每片卷积结果加起来,作为3D卷积结果;1x1卷积属于3D卷积的一个特例(point-wise),有厚度无面积, 直接把每层单个点相乘再相加。
另,附百度2015校招机器学习笔试题:http://www.itmian4.com/thread-7042-1-1.html

过拟合是泛化的反面,好比乡下快活的刘姥姥进了大观园会各种不适应,但受过良好教育的林黛玉进贾府就不会大惊小怪。实际训练中, 降低过拟合的办法一般如下:
正则化(Regularization)
L2正则化:目标函数中增加所有权重w参数的平方之和, 逼迫所有w尽可能趋向零但不为零. 因为过拟合的时候, 拟合函数需要顾忌每一个点, 最终形成的拟合函数波动很大, 在某些很小的区间里, 函数值的变化很剧烈, 也就是某些w非常大. 为此, L2正则化的加入就惩罚了权重变大的趋势.
L1正则化:目标函数中增加所有权重w参数的绝对值之和, 逼迫更多w为零(也就是变稀疏. L2因为其导数也趋0, 奔向零的速度不如L1给力了). 大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的特征权重反而会被考虑,从而干扰了对正确yi的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些无用的特征,也就是把这些特征对应的权重置为0。
随机失活(dropout)
在训练的运行的时候,让神经元以超参数p的概率被激活(也就是1-p的概率被设置为0), 每个w因此随机参与, 使得任意w都不是不可或缺的, 效果类似于数量巨大的模型集成。
逐层归一化(batch normalization)
这个方法给每层的输出都做一次归一化(网络上相当于加了一个线性变换层), 使得下一层的输入接近高斯分布. 这个方法相当于下一层的w训练时避免了其输入以偏概全, 因而泛化效果非常好.
提前终止(early stopping)
理论上可能的局部极小值数量随参数的数量呈指数增长, 到达某个精确的最小值是不良泛化的一个来源. 实践表明, 追求细粒度极小值具有较高的泛化误差。这是直观的,因为我们通常会希望我们的误差函数是平滑的, 精确的最小值处所见相应误差曲面具有高度不规则性, 而我们的泛化要求减少精确度去获得平滑最小值, 所以很多训练方法都提出了提前终止策略. 典型的方法是根据交叉叉验证提前终止: 若每次训练前, 将训练数据划分为若干份, 取一份为测试集, 其他为训练集, 每次训练完立即拿此次选中的测试集自测. 因为每份都有一次机会当测试集, 所以此方法称之为交叉验证. 交叉验证的错误率最小时可以认为泛化性能最好, 这时候训练错误率虽然还在继续下降, 但也得终止继续训练了.

2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型,SVM是非参数模型。
2、从损失函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
来源:http://blog.csdn.net/timcompp/article/details/62237986
通常人们会从一些常用的核函数中选择(根据问题和数据的不同,选择不同的参数,实际上就是得到了不同的核函数),例如:
- 多项式核,显然刚才我们举的例子是这里多项式核的一个特例(R = 1,d = 2)。虽然比较麻烦,而且没有必要,不过这个核所对应的映射实际上是可以写出来的,该空间的维度是
 ,其中 是原始空间的维度。
,其中 是原始空间的维度。 - 高斯核
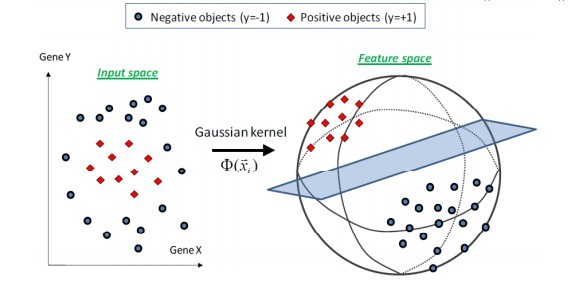
 ,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果
,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间:
选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间: - 线性核
 ,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
@nishizhen:个人感觉逻辑回归和线性回归首先都是广义的线性回归,
其次经典线性模型的优化目标函数是最小二乘,而逻辑回归则是似然函数,
另外线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,因而对于这类问题来说,逻辑回归的鲁棒性比线性回归的要好。
@乖乖癞皮狗:逻辑回归的模型本质上是一个线性回归模型,逻辑回归都是以线性回归为理论支持的。但线性回归模型无法做到sigmoid的非线性形式,sigmoid可以轻松处理0/1分类问题。
集成学习的集成对象是学习器. Bagging和Boosting属于集成学习的两类方法. Bagging方法有放回地采样同数量样本训练每个学习器, 然后再一起集成(简单投票); Boosting方法使用全部样本(可调权重)依次训练每个学习器, 迭代集成(平滑加权).
决策树属于最常用的学习器, 其学习过程是从根建立树, 也就是如何决策叶子节点分裂. ID3/C4.5决策树用信息熵计算最优分裂, CART决策树用基尼指数计算最优分裂, xgboost决策树使用二阶泰勒展开系数计算最优分裂.
下面所提到的学习器都是决策树:
Bagging方法:
学习器间不存在强依赖关系, 学习器可并行训练生成, 集成方式一般为投票;
Random Forest属于Bagging的代表, 放回抽样, 每个学习器随机选择部分特征去优化;
Boosting方法:
学习器之间存在强依赖关系、必须串行生成, 集成方式为加权和;
Adaboost属于Boosting, 采用指数损失函数替代原本分类任务的0/1损失函数;
GBDT属于Boosting的优秀代表, 对函数残差近似值进行梯度下降, 用CART回归树做学习器, 集成为回归模型;
xgboost属于Boosting的集大成者, 对函数残差近似值进行梯度下降, 迭代时利用了二阶梯度信息, 集成模型可分类也可回归. 由于它可在特征粒度上并行计算, 结构风险和工程实现都做了很多优化, 泛化, 性能和扩展性都比GBDT要好。
关于决策树,这里有篇《决策树算法》。而随机森林Random Forest是一个包含多个决策树的分类器。至于AdaBoost,则是英文"Adaptive Boosting"(自适应增强)的缩写,关于AdaBoost可以看下这篇文章《Adaboost 算法的原理与推导》。GBDT(Gradient Boosting Decision Tree),即梯度上升决策树算法,相当于融合决策树和梯度上升boosting算法。
1.损失函数是用泰勒展式二项逼近,而不是像gbdt里的就是一阶导数
2.对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性
3.节点分裂的方式不同,gbdt是用的gini系数,xgboost是经过优化推导后的
更多详见:https://xijunlee.github.io/2017/06/03/%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93/
xgboost属于boosting集成学习方法, 样本是不放回的, 因而每轮计算样本不重复. 另一方面, xgboost支持子采样, 也就是每轮计算可以不使用全部样本, 以减少过拟合. 进一步地, xgboost 还有列采样, 每轮计算按百分比随机采样一部分特征, 既提高计算速度又减少过拟合。
生成方法:由数据学习联合概率密度分布函数 P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机
L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
简单总结一下就是:
L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数
Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。
L1范数可以使权值稀疏,方便特征提取。
L2范数可以防止过拟合,提升模型的泛化能力。
为了更直观看出两者的区别,我再放一张图:

@AntZ: 先验就是优化的起跑线, 有先验的好处就是可以在较小的数据集中有良好的泛化性能,当然这是在先验分布是接近真实分布的情况下得到的了,从信息论的角度看,向系统加入了正确先验这个信息,肯定会提高系统的性能。
对参数引入高斯正态先验分布相当于L2正则化, 这个大家都熟悉:
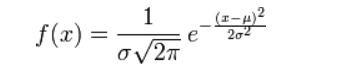
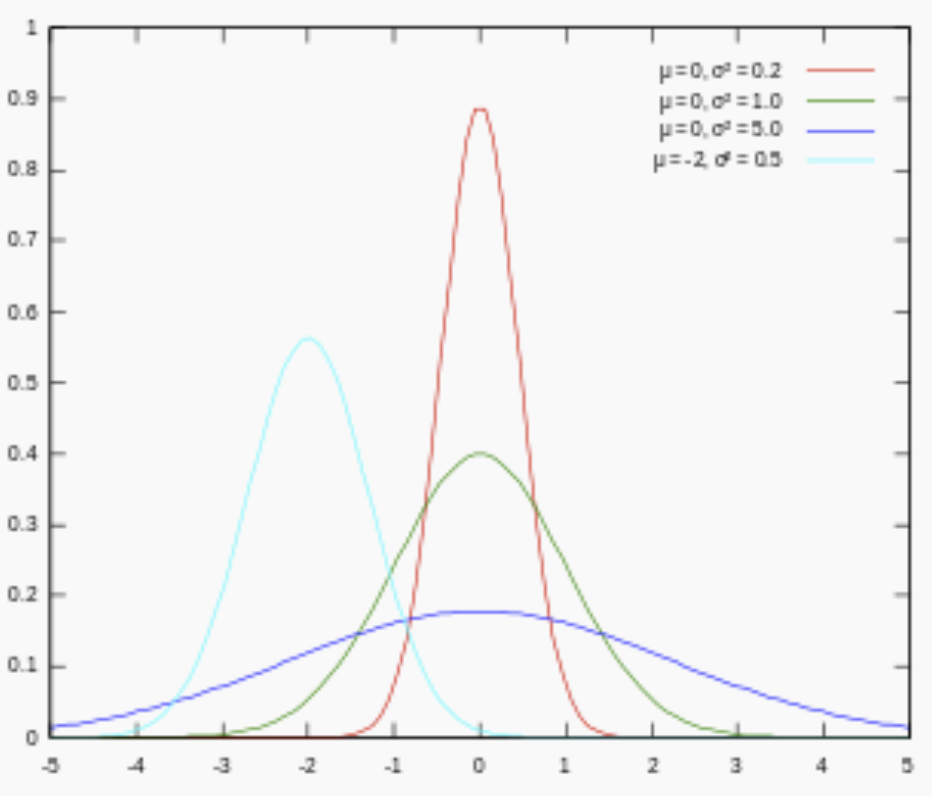
对参数引入拉普拉斯先验等价于 L1正则化, 如下图:
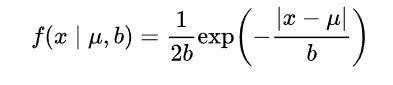
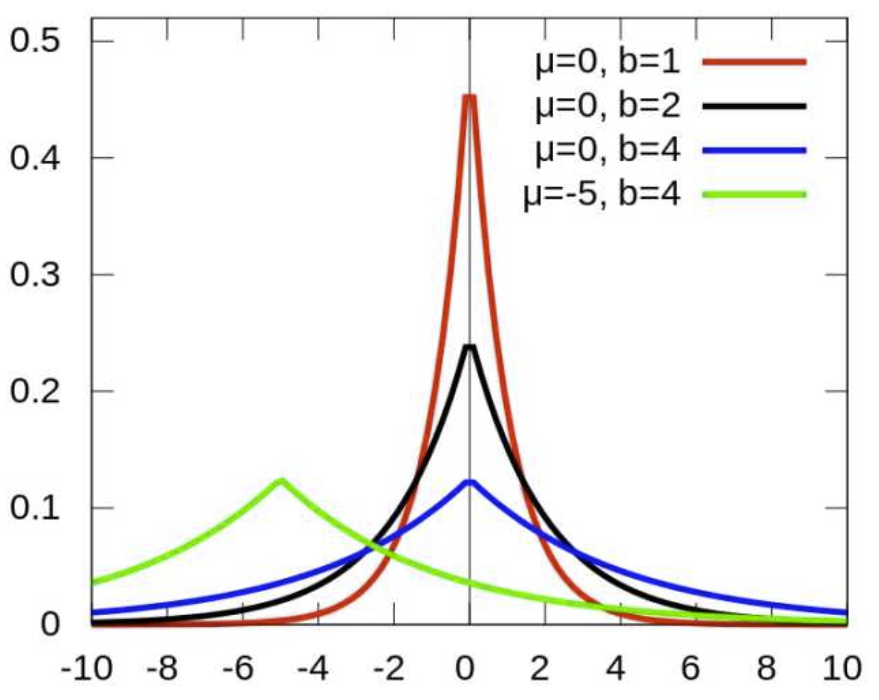
从上面两图可以看出, L2先验趋向零周围, L1先验趋向零本身。
Deep Learning -Yann LeCun, Yoshua Bengio & Geoffrey Hinton
Learn TensorFlow and deep learning, without a Ph.D.
The Unreasonable Effectiveness of Deep Learning -LeCun 16 NIPS Keynote
以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成为不同的形状,最后得到汽车的表示。

CNN抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。
局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络的训练难度,一个Filter只提取一个特征,在整个图片(或者语音/文本) 中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图:
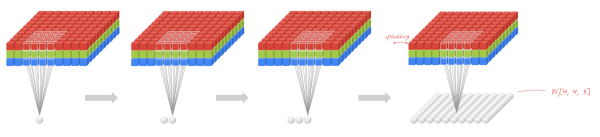
上图中,如果每一个点的处理使用相同的Filter,则为全卷积,如果使用不同的Filter,则为Local-Conv。
另,关于CNN,这里有篇文章《CNN笔记:通俗理解卷积神经网络》。
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例 ,而实例空间
,而实例空间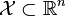 ,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程如下:
- 步骤1. 首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。
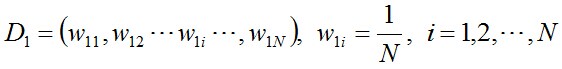
- 步骤2. 进行多轮迭代,用m = 1,2, ..., M表示迭代的第多少轮
a. 使用具有权值分布Dm的训练数据集学习,得到基本分类器(选取让误差率最低的阈值来设计基本分类器):
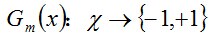
b. 计算Gm(x)在训练数据集上的分类误差率
由上述式子可知,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。
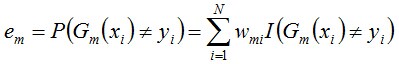
由上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
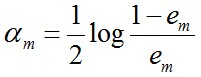
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代
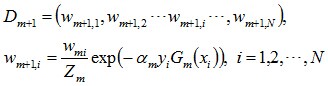
使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦于”那些较难分的样本上。
其中,Zm是规范化因子,使得Dm+1成为一个概率分布:
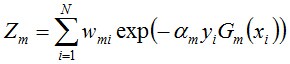
- 步骤3. 组合各个弱分类器
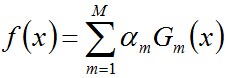
从而得到最终分类器,如下:
更多请查看此文:《Adaboost 算法的原理与推导》。
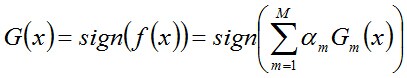
@AntZ: 朴素贝叶斯模型(Naive Bayesian Model)的朴素(Naive)的含义是"很简单很天真"地假设样本特征彼此独立. 这个假设现实中基本上不存在, 但特征相关性很小的实际情况还是很多的, 所以这个模型仍然能够工作得很好。
ML面试1000题系列(1-20)的更多相关文章
- ML面试1000题系列(71-80)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 71.看你是搞视觉的,熟悉哪些CV框架,顺带聊聊 ...
- ML面试1000题系列(81-90)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 81.已知一组数据的协方差矩阵P,下面关于主分量 ...
- ML面试1000题系列(51-60)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 51.简单说下sigmoid激活函数 常用的非线 ...
- ML面试1000题系列(91-100)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 91 简单说说RNN的原理?我们升学到高三准备高 ...
- ML面试1000题系列(61-70)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 61.说说共轭梯度法? @wtq1993,htt ...
- ML面试1000题系列(41-50)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 41. #include和#include“fi ...
- ML面试1000题系列(31-40)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 31.下列哪个不属于CRF模型对于HMM和MEM ...
- ML面试1000题系列(21-30)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 21.请简要说说EM算法. @tornadome ...
- BAT机器学习面试1000题系列
https://blog.csdn.net/sinat_35512245/article/details/78796328
随机推荐
- JeecgBoot 2.1.1 代码生成器AI版本发布,基于SpringBoot+AntDesign的JAVA快速开发平台
此版本重点升级了 Online 代码生成器,支持更多的控件生成,所见即所得,极大的提高开发效率:同时做了数据库兼容专项工作,让 Online 开发兼容更多数据库:Mysql.SqlServer.Ora ...
- js 引入Vue.js实现vue效果
拆分组件为单个js见:https://www.jianshu.com/p/2f0335818ceb 效果 html <!DOCTYPE html> <html> <hea ...
- 2019-6-14-WPF-shows-that-some-windows-in-multithreading-will-be-locked-in-the-PenThreadWorker-constr...
title author date CreateTime categories WPF shows that some windows in multithreading will be locked ...
- [UVA12235] Help Bubu 思维题+状态定义+Dp
Online Judge:UVA12235 Label:思维题,状态定义,状压Dp 题面: 题目描述 有一个书架,上面放了n本书,从左往右的第i本书的高度为h[i].定义书架的混乱度为连续等高段的个数 ...
- winDbg + VMware + window 双机联调环境搭建
这里简单的介绍一下内核开发双机联调的搭建环境,尽管网上有很多类似的文章,但看了很多总是不太舒服,觉得不太明白,所以自己实践一下总结一篇.下面就拿我的环境简单介绍,希望别人可以看懂. 准备工具:装虚拟机 ...
- mysql批量增加表中新列存储过程
一般访问量比较大的网站,请求日志表都是每天一张表独立创建. 业务需要为每张表都添加一个新列,纠结了半天,写了个存储过程如下: 日志表结构类型 tbl_ads_req_20140801, tbl_ads ...
- LUOGU NOIP 2018 模拟赛 DAY1
T1 传送门 解题思路 这似乎是小学数学知识???mod 9就相当于各位之和mod 9,打表求了个逆元,等差数列求和公式就行了. #include<iostream> #include&l ...
- PHP获取网站中各文章的第一张图片的代码示例
调取文章中的第一张图作为列表页缩略图是很流行的做法,WordPress中一般主题默认也是如此,那我们接下来就一起来看看PHP获取网站中各文章的第一张图片的代码示例 ? 1 2 3 4 5 6 7 8 ...
- Boost test vs2013 fatal error C1001
Boost test vs2013 fatal error C1001 Boost test库提供了一个用于单元测试的基于命令行界面的测试套件UTF:Unit Test Framework,具有单元测 ...
- devc++读取不了当前目录下的文件
devc++在当前目录新建了一个文件之后,用文件读取的操作报错: 如图所示: 解决方案: 先把该文件从左侧工作空间中移除: 移除之后就没了: 再 ...