数据库为什么要用B+树结构--MySQL索引结构的实现(转)
B+树在数据库中的应用
InnoDB 与 MyISAM 结构上的区别
1.InnoDB的主键索引 ,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引,所以必须有主键,如果没有显示定义,自动为生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形
2.InnoDB的辅助索引(Secondary Index, 也就是非主键索引)也会包含主键列,比如名字建立索引,内部节点 会包含名字,叶子节点会包含该名字对应的主键的值,如果主键定义的比较大,其他索引也将很大

3.MyISAM引擎使用B+Tree作为索引结构,索引文件叶节点的data域存放的是数据记录的地址,指向数据文件中对应的值,每个节点只有该索引列的值
4.MyISAM主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,辅助索引可以重复,
(由于MyISAM辅助索引在叶子节点上存储的是数据记录的地址,和主键索引一样,所以相对于B+的InnoDB可通过辅助索引
快速找到所有的数据,而不需要再遍历一边主键索引,所以适用于OLAP)
InnoDB索引和MyISAM索引的区别:
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。
}
1. 索引在数据库中的作用
在数据库系统的使用过程当中,数据的查询是使用最频繁的一种数据操作。
最基本的查询算法当然是顺序查找(linear search),遍历表然后逐行匹配行值是否等于待查找的关键字,其时间复杂度为O(n)。但时间复杂度为O(n)的算法规模小的表,负载轻的数据库,也能有好的性能。 但是数据增大的时候,时间复杂度为O(n)的算法显然是糟糕的,性能就很快下降了。
好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
索引是对数据库表 中一个或多个列的值进行排序的结构。与在表 中搜索所有的行相比,索引用指针 指向存储在表中指定列的数据值,然后根据指定的次序排列这些指针,有助于更快地获取信息。通常情 况下 ,只有当经常查询索引列中的数据时 ,才需要在表上创建索引。索引将占用磁盘空间,并且影响数 据更新的速度。但是在多数情况下 ,索引所带来的数据检索速度优势大大超过它的不足之处。
2. B+树在数据库索引中的应用
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构
1)在数据库索引的应用
在数据库索引的应用中,B+树按照下列方式进行组织 :
① 叶结点的组织方式 。B+树的查找键 是数据文件的主键 ,且索引是稠密的。也就是说 ,叶结点 中为数据文件的第一个记录设有一个键、指针对 ,该数据文件可以按主键排序,也可以不按主键排序 ;数据文件按主键排序,且 B +树是稀疏索引 , 在叶结点中为数据文件的每一个块设有一个键、指针对 ;数据文件不按键属性排序 ,且该属性是 B +树 的查找键 , 叶结点中为数据文件里出现的每个属性K设有一个键 、 指针对 , 其中指针执行排序键值为 K的 记录中的第一个。
② 非叶结点 的组织方式。B+树 中的非叶结点形成 了叶结点上的一个多级稀疏索引。 每个非叶结点中至少有ceil( m/2 ) 个指针 , 至多有 m 个指针 。
2)B+树索引的插入和删除
①在向数据库中插入新的数据时,同时也需要向数据库索引中插入相应的索引键值 ,则需要向 B+树 中插入新的键值。即上面我们提到的B-树插入算法。
②当从数据库中删除数据时,同时也需要从数据库索引中删除相应的索引键值 ,则需要从 B+树 中删 除该键值 。即B-树删除算法
为什么使用B-Tree(B+Tree)
二叉查找树进化品种的红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为什么使用B-/+Tree,还跟磁盘存取原理有关。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
我们上面分析B-/+Tree检索一次最多需要访问节点:
h =

数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B- Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logmN)。一般实际应用中,m是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
MySQL的B-Tree索引(技术上说B+Tree)
在 MySQL 中,主要有四种类型的索引,分别为: B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。我们主要分析B-Tree 索引。
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持 B-Tree 索引。Archive 引擎直到 MySQL 5.1 才支持索引,而且只支持索引单个 AUTO_INCREMENT 列。
不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理系统中B-Tree 索引也同样是作为最主要的索引类型,这主要是因为 B-Tree 索引的存储结构在数据库的数据检索中有非常优异的表现。
一般来说, MySQL 中的 B-Tree 索引的物理文件大多都是以 Balance Tree 的结构来存储的,也就是所有实际需要的数据都存放于 Tree 的 Leaf Node(叶子节点) ,而且到任何一个 Leaf Node 的最短路径的长度都是完全相同的,所以我们大家都称之为 B-Tree 索引。当然,可能各种数据库(或 MySQL 的各种存储引擎)在存放自己的 B-Tree 索引的时候会对存储结构稍作改造。如 Innodb 存储引擎的 B-Tree 索引实际使用的存储结构实际上是 B+Tree,也就是在 B-Tree 数据结构的基础上做了很小的改造,在每一个Leaf Node 上面出了存放索引键的相关信息之外,还存储了指向与该 Leaf Node 相邻的后一个 LeafNode 的指针信息(增加了顺序访问指针),这主要是为了加快检索多个相邻 Leaf Node 的效率考虑。
下面主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式:
1. MyISAM索引实现:
1)主键索引:
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM主键索引的原理图:
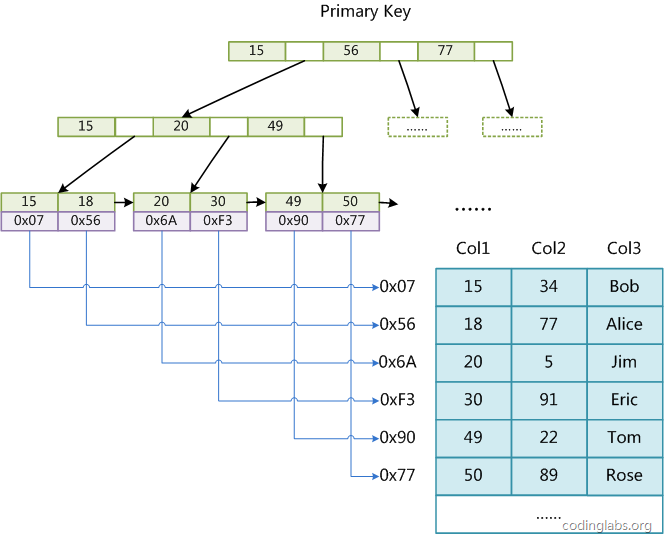

(图myisam1)
这里设表一共有三列,假设我们以Col1为主键,图myisam1是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。
2)辅助索引(Secondary key)
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
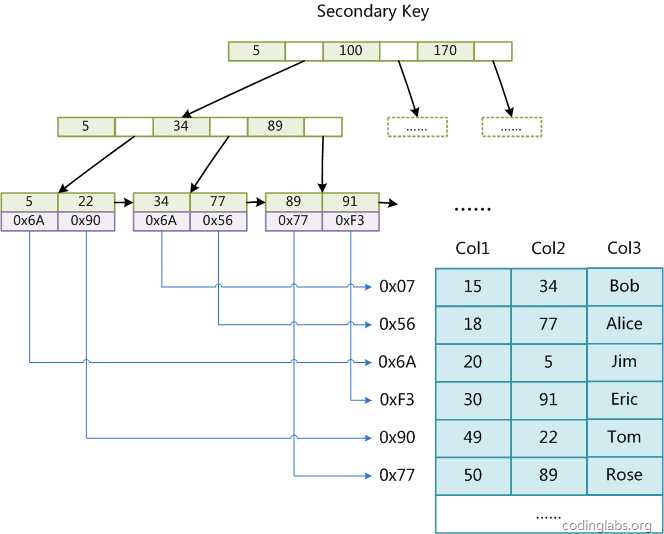

同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
2. InnoDB索引实现
然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同.
1)主键索引:
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
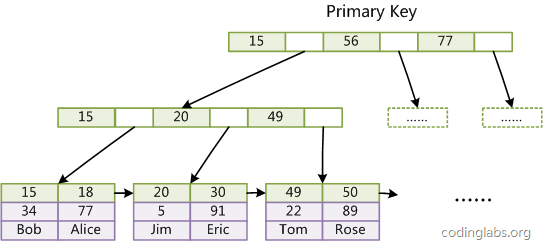

(图inndb主键索引)
(图inndb主键索引)是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
2). InnoDB的辅助索引
InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:

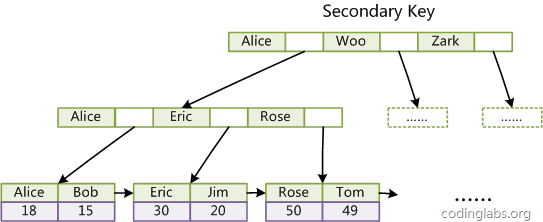
InnoDB 表是基于聚簇索引建立的。因此InnoDB 的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引(Secondary Index, 也就是非主键索引)也会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义 、很多索引,则争取尽量把主键定义得小一些。InnoDB 不会压缩索引。
文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
InnoDB索引和MyISAM索引的区别:
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。
转https://www.cnblogs.com/xyxxs/p/4440187.html
数据库为什么要用B+树结构--MySQL索引结构的实现(转)的更多相关文章
- 数据库为什么要用B+树结构--MySQL索引结构的实现
原理: http://blog.csdn.net/cangchen/article/details/44818485 http://blog.csdn.net/kennyrose/article/de ...
- B-/B+树 MySQL索引结构
索引 索引的简介 简单来说,索引是一种数据结构 其目的在于提高查询效率 可以简单理解为“排好序的快速查找结构” 一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在中磁 ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- Mysql索引结构及常见索引的区别
一.Mysql索引主要有两种结构:B+Tree索引和Hash索引 Hash索引 mysql中,只有Memory(Memory表只存在内存中,断电会消失,适用于临时表)存储引擎显示支持Hash索引,是M ...
- 【转】由浅入深探究mysql索引结构原理、性能分析与优化
摘要: 第一部分:基础知识 第二部分:MYISAM和INNODB索引结构 1.简单介绍B-tree B+ tree树 2.MyisAM索引结构 3.Annode索引结构 4.MyisAM索引与Inno ...
- MySQL 索引结构 hash 有序数组
MySQL 索引结构 hash 有序数组 除了最常见的树形索引结构,Hash索引也有它的独到之处. Hash算法 Hash本身是一种函数,又被称为散列函数. 它的思路很简单:将key放在数组里,用 ...
- 一天五道Java面试题----第七天(mysql索引结构,各自的优劣--------->事务的基本特性和隔离级别)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1 .mysql索引结构,各自的优劣 2 .索引的设计原则 3 .mysql锁的类型有哪些 4 .mysql执行计划怎么看 ...
- 索引很难么?带你从头到尾捋一遍MySQL索引结构,不信你学不会!
前言 Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结.自上上篇写了手动搭建Redis集群和MySQL主从同步(非Docker)和上篇写了动手实现MySQL读写分离and故 ...
- 带你从头到尾捋一遍MySQL索引结构(2)
前言 Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结.索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家. 这篇博客我会谈谈对于索引结构我自己的看法,以 ...
随机推荐
- C#:xml操作(待补充)
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.X ...
- c# 高效的线程安全队列ConcurrentQueue
c#高效的线程安全队列ConcurrentQueue<T>(上) c# 高效的线程安全队列ConcurrentQueue(下) Segment类 c#高效的线程安全队列Concurrent ...
- AutoFac文档3(转载)
目录 开始 Registering components 控制范围和生命周期 用模块结构化Autofac xml配置 与.net集成 深入理解Autofac 指导 关于 词汇表 服务类型,名称和键 同 ...
- js与php中一些相似函数的对比
一:substr js中:stringObject.substr(start,length) 一个中文算一个字符,一个英文也算一个字符 <script type="text/jav ...
- 父级和 子集 controller 之间的通讯
在同个 angular.js 应用的控制器之间进行通信可以有很多种不同的方式,本文主要讲两种: 基于scope继承的方式 基于event传播的方式 基于scope继承的方式 最简单的让控制器之间进行通 ...
- [svc]salt-grains
用途 1,匹配客户端 2,配置文件里使用 3,资产管理 定义grains方法1: 方法2:
- Linux服务器丢包故障的解决思路及引申的TCP/IP协议栈理论
我们使用Linux作为服务器操作系统时,为了达到高并发处理能力,充分利用机器性能,经常会进行一些内核参数的调整优化,但不合理的调整常常也会引起意想不到的其他问题,本文就一次Linux服务器丢包故障的处 ...
- 执行git命令出现 xcrun: error:
xcrun: error: active developer path ("/Applications/Xcode.app/Contents/Developer") does no ...
- python操作word
python教程(百度经验) Python 操作Word(Excel.PPT等通用) import win32comfrom win32com.client import Dispatch, co ...
- 一款基于HTML5 Canvas的画板涂鸦动画
今天给各网友分享一款基于HTML5 Canvas的画板涂鸦动画.记得之前我们分享过一款HTML5 Canvas画板工具,可以切换不同的笔刷,功能十分强大.本文今天要再来分享一款基于HTML5 Canv ...