机器学习笔记—Logistic 回归
前面我们介绍了线性回归,为捕获训练集中隐藏的线性模型,提高预测准确率,我们寻找最佳参数 θ,使得预测值与真实值误差尽量小,也就是使均方误差最小。而经过验证,最小均方误差是符合最大似然估计理论的。
在 Logistic 回归中,我们依然要用到最大似然估计理论。
分类问题跟回归问题的区别是,预测值 y 取的是离散值。本文只讨论二分类问题,y 只能取 0 和 1 两个值。
如果不管 y 是离散值,硬要用线性回归算法来根据 x 来预测 y 值,也不是不行,但效果就很差。
理想情况下,我们希望有一个预测公式,把 y 等于 1 的 x 通过预测公式正好映射到 1,把 y 等于 0 的 x 通过预测公式正好映射到 0,这样就能把 x 空间一劈两半,一边是 1,一边是 0,当然,这是不现实的。
因此,我们只能希望当 y 等于 1 时,预测算法根据 x 值的计算结果应该尽量接近 1,当 y 等于 0 时,预测结果应尽量接近 0。尽量把属于 1 和 0 的 x 分开,少数 x 处于 1 和 0 的交界处。
这是不是让我们想起了这样一幅函数图像:
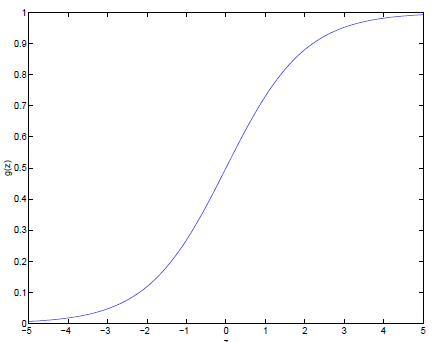
这就是 Sigmoid 函数图像。
公式是:
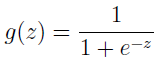
当 z 趋于无穷时,g(z) 趋近 1,当 z 趋于负无穷时,g(z) 趋于 0。这样 g(z) 的值就只是在 0 和 1 之间。
我们的分类模型就可以使用这个函数,让 z=θTx,可得:
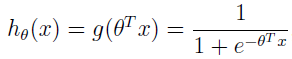
这样就将 x 映射到了 hθ(x),即 y,且大部分 x 对应的 y 值不是趋近于 1 就是趋近 0,模糊地带的很少。
记得在线性回归中 hθ(x) 的定义是
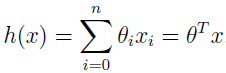
而我们这里是对 θTx 做了个映射,把 θTx 映射到 0、1 区间里,因为要预测的 y 值就是 0 和 1,这样就很容易通过监督学习对参数 θ 进行优化,使 x 更容易地映射到相应的 y 值。
其实除了 Sigmoid 函数,其它从 0 到 1 平滑递增的函数也能用,但为什么我们要用 Sigmoid 函数呢?在后面一般线性模型会讲到,Sigmoid 是个很自然的选择。
Sigmoid 函数的导数有个有用的性质:
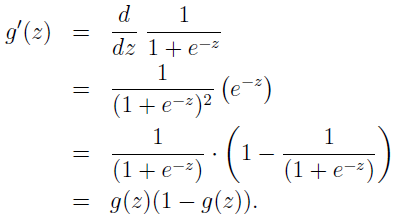
现在,有了 Logistic 回归模型,怎么找到合适的 θ 呢?在线性回归中,我们是通过最小化均方误差来寻找 θ,这里的分类就不能用均方误差,但我们知道线性回归中,在一定概率假设下,最小化军方误差其实可以从最大化似然估计中推导出来,这里我们也将在一定概率假设下,通过最大化似然估计来寻找参数。
假定:
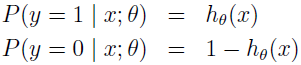
这里把 hθ(x) 作为给定 x 和 θ 时,y=1 的概率。
这两个公式还可以更紧凑:
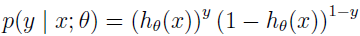
其中:
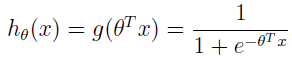
假设函数把 hθ(x) 就是 x 属于 y=1 的概率,即 y=1 的条件概率为 hθ(x),y=0 的条件概率为 1-hθ(x)。当我们要判别一个新来的 x 属于哪个类时,只需求 hθ(x),若大于 0.5 就是 y=1 的类,反之属于 y=0 类。
再审视下 hθ(x),发现 hθ(x) 只和 θTx 有关,θTx>0,x 就是 y=1 的类。g(z) 只不过是用来映射,真实的类别决定权还在 θTx。当 θTx 趋于正无穷时,hθ(x)=1,反之 hθ(x)=0。如果我们只从 θTx 出发,希望模型达到的目标无非就是让训练集中 y=1 的特征 θTx 远大于 0,而 y=0 的特征 θTx 远小于 0。Logistic 回归就是要学习得到 θ,使得正例的特征远大于 0,负例的特征远小于 0,强调在全部训练实例上达到这个目标。
假定 m 个训练实例是独立生成的,我们能写下参数的似然函数为:
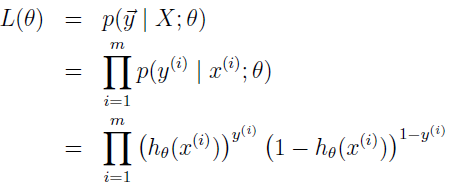
跟之前一样,最大化 log 似然会更容易:
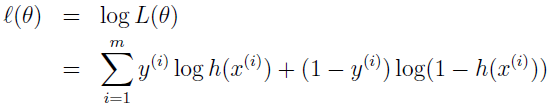
怎么最大化该似然函数呢?跟线性回归的求导类似,我们依然使用梯度下降,使用向量表示,θ 的更新规则是:
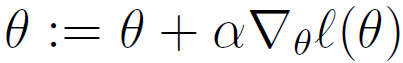
注意这个的更新公式里是加号,而不是减号,因为这里我们是要最大化,跟之前讲的线性回归中最小化均方误差不一样:
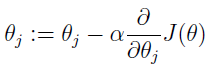
这里只对一个训练数据,对似然函数求导如下,将 hθ(x)=g(θTx) 代入,并利用 sigmoid 导数性质 g'(z)=g(z)(1-g(z)),得:
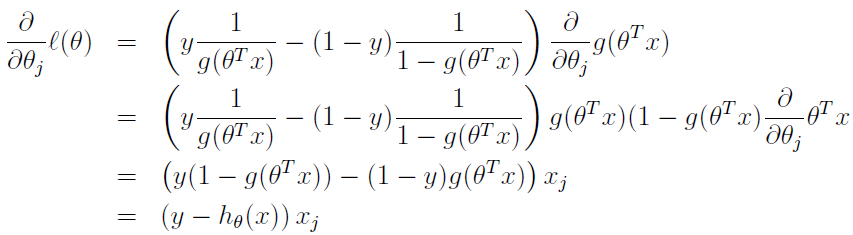
由此,随机梯度上升规则如下:
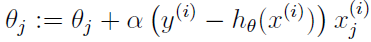
如果再往前翻下线性回归的最小均方误差的更新规则,会发现更新规则是一模一样的,但这是不同的算法,因为现在 hθ(x) 是 θTx 的非线性函数。完全不同的算法和学习问题,更新规则竟然是一样的!这是巧合吗?或者是背后有更深层的原因?后面讲一般线性模型时我们会回答这个问题。
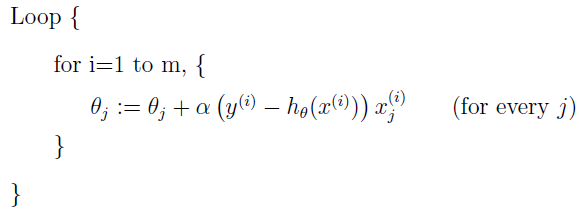
题外话:
稍微修改下 Logistic 回归方法,使其强制输出 0 或者 1,这就需要修改 g 的定义,g 定义成一个门限函数。
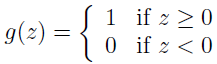
然后我们使用更新规则:
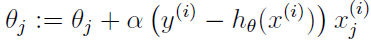
这就是感知机学习算法。
在上个世纪 60 年代,感知机作为大脑工作单元的一个粗糙模型,是备受争议的。算法很简单,后面讲到学习理论时会详谈。表面上看感知机与我们讨论的其它算法很相似,它实际是一个跟 Logistic 和最小二乘回归非常不同的算法,特别是,它很难对预测做概率上的解释,或者从最大似然估计算法中推出到感知机。
题外话结束。这里不懂也没关系,只是提一下,后面会详谈。
下面介绍最大化似然函数的另一种算法,首先考虑寻找一个函数零点的牛顿方法,假定有个函数 f,想要找到一个 θ 值使得 f(θ)=0。这里 θ 是一个实数,不是向量。牛顿方法执行下面的更新:
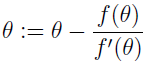
只看这个公式还有点困惑,加上图再讲解就明白了。
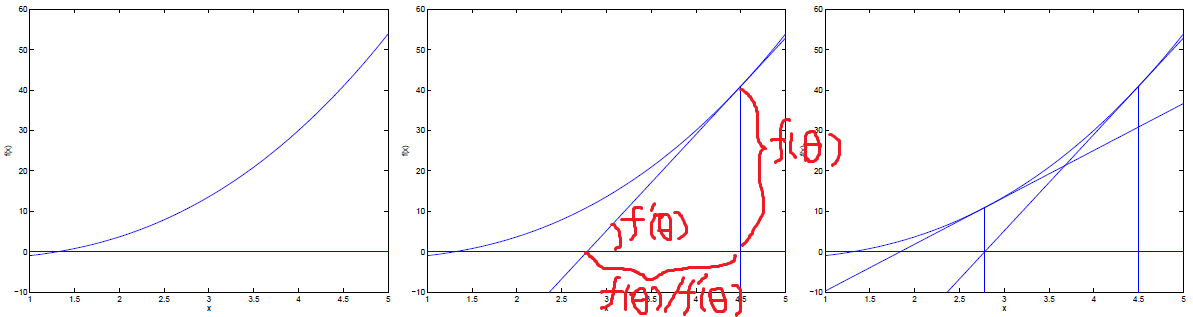
f'(θ) 是导数,导数就是斜率,斜率就是 Δf(θ)/Δθ……
所以 θ-f(θ)/f'(θ) 就是,在 θ 点 f(θ) 的切线等于 0 的点。见上图。
牛顿方法提供了一种到达 f(θ)=0 的方法,它如何用来求最大似然呢?似然函数的最大值也就是其导数为 0 时的点。所以,可得更新规则:
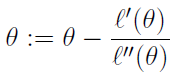
由于我们的 Logistic 回归的 θ 是向量,所以牛顿方法需要扩展成多维,也叫 Newton-Raphson 方法:
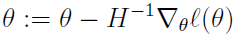
其中 H 是一个 n*n 的 Hessian 矩阵,其元素是:
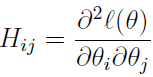
牛顿方法收敛得比批梯度下降方法快,到最小值需要更少的迭代次数。但牛顿方法的一次迭代比梯度下降费劲多了,因为它需要寻找并转换 n*n 的 Hessian 矩阵,但只要 n 不是太大,它通常就会快得多。牛顿方法应用到最大化 Logistic 回归 Log 似然函数时,就叫做 Fisher scoring。
参考资料:
1、http://cs229.stanford.edu/notes/cs229-notes1.pdf
2、洪松林, 庄映辉, 李堃. 数据挖掘技术与工程实践[M]. 机械工业出版社. 2014
机器学习笔记—Logistic 回归的更多相关文章
- 机器学习笔记—Logistic回归
本文申明:本系列笔记全部为原创内容,如有转载请申明原地址出处.谢谢 序言:what is logistic regression? Logistics 一词表示adj.逻辑的;[军]后勤学的n.[逻] ...
- [机器学习实战-Logistic回归]使用Logistic回归预测各种实例
目录 本实验代码已经传到gitee上,请点击查收! 一.实验目的 二.实验内容与设计思想 实验内容 设计思想 三.实验使用环境 四.实验步骤和调试过程 4.1 基于Logistic回归和Sigmoid ...
- 机器学习5—logistic回归学习笔记
机器学习实战之logistic回归 test5.py #-*- coding:utf-8 import sys sys.path.append("logRegres.py") fr ...
- <机器学习实战>读书笔记--logistic回归
1. 利用logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类. 2.sigmoid函数的分类 Sigmoid函数公式定义 3.梯度上升法 基本思想:要找 ...
- 机器学习之Logistic 回归算法
1 Logistic 回归算法的原理 1.1 需要的数学基础 我在看机器学习实战时对其中的代码非常费解,说好的利用偏导数求最值怎么代码中没有体现啊,就一个简单的式子:θ= θ - α Σ [( hθ( ...
- 机器学习之logistic回归算法与代码实现原理
Logistic回归算法原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10033567.html ...
- Python机器学习笔记 Logistic Regression
Logistic回归公式推导和代码实现 1,引言 logistic回归是机器学习中最常用最经典的分类方法之一,有人称之为逻辑回归或者逻辑斯蒂回归.虽然他称为回归模型,但是却处理的是分类问题,这主要是因 ...
- 机器学习基础-Logistic回归1
利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类. 训练分类器时的做法就是寻找最佳拟合参数,使用的时最优化算法. 优点:计算代价不高,利于理解和实现. ...
- 吴裕雄--天生自然python机器学习:Logistic回归
假设现在有一些数据点,我们用 一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归.利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类 ...
随机推荐
- 转!mysql备份与还原数据库
备份数据库:1) mysqldump -uroot -p db_name > 20181018_preprod_bak.sql2) 输入数据库密码 还原数据库:1. 系统命令行:mysqladm ...
- Git 使用vi或vim
1.vi & vim 有两种工作模式: (1) 命令模式:接受.执行 vi & vim 操作命令的模式,打开文件后的默认模式: (2) 编辑模式:对打开的文件内容进行 增.删.改 操作 ...
- PHP error_log 新认知
//error_log 简介及使用方法 // error_log("消息","类型","路径"); //message //type ...
- Purpose of ContextLoaderListener in Spring
The ApplicationContext is where your Spring beans live. The purpose of the ContextLoaderListener is ...
- (0.2.7)Mysql安装——多实例安装
(0.2.6)Mysql安装——多实例安装 待完善
- xiaochengxubeijingt
- 7. Reverse Integer(翻转整数)
Given a 32-bit signed integer, reverse digits of an integer. Example 1: Input: 123 Output: 321 Examp ...
- HDU - 5592 ZYB's Premutation (权值线段树)
题意:给出序列前k项中的逆序对数,构造出这个序列. 分析:使用权值线段树来确定序列元素. 逆序对的数量肯定是递增的,从最后一个元素开始逆向统计,则\(a[i] - a[i-1]\)即位置i之前比位置i ...
- Netty资料
netty 资料 转自 http://calvin1978.blogcn.com/articles/netty-info.html Netty资料皆阵列在前 Posted on 2016-08- ...
- 在Ubuntu14.4(32位)中配置I.MX6的QT编译环境
1,开发工具下载 一,下载VMware Workstation虚拟机 地址:http://1.xp510.com:801/xp2011/VMware10.7z 二,下载Ubuntu 14.04.5 L ...