初识PCA数据降维
PCA要做的事降噪和去冗余,其本质就是对角化协方差矩阵。
一.预备知识
1.1 协方差分析
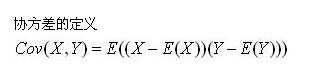
对于一般的分布,直接代入E(X)之类的就可以计算出来了,但真给你一个具体数值的分布,要计算协方差矩阵,根据这个公式来计算,还真不容易反应过来。网上值得参考的资料也不多,这里用一个例子说明协方差矩阵是怎么计算出来的吧。

用matlab计算这个例子
z=[1,2;3,6;4,2;5,2]
cov(z)
ans =
2.9167 -0.3333
-0.3333 4.0000
可以看出,matlab计算协方差过程中还将元素统一缩小了3倍。所以,协方差的matlab计算公式为:
协方差(i,j)=(第i列所有元素-第i列均值)*(第j列所有元素-第j列均值)/(样本数-1)
下面在给出一个4维3样本的实例,注意4维样本与符号X,Y就没有关系了,X,Y表示两维的,4维就直接套用计算公式,不用X,Y那么具有迷惑性的表达了。

注释:协方差为正时说明X和Y是正相关关系,协方差为负时X和Y是负相关关系,协方差为0时X和Y相互独立。
Cov(X,X)就是X的方差(Variance),Cov(X,Y)就是协方差了,从上面可以看出,协方差矩阵是方阵,维度是样本的维度。
1.2 协方差实现
for i=1:size(a,2)
for j=1:size(a,2)
c(i,j)=sum((a(:,i)-mean(a(:,i))).*(a(:,j)-mean(a(:,j))))/(size(a,1)-1);
end
end
验证如下:
>> a =[
-1 1 2
-2 3 1
4 0 3]
a =
-1 1 2
-2 3 1
4 0 3
>> cov(a)
ans =
10.3333 -4.1667 3.0000
-4.1667 2.3333 -1.5000
3.0000 -1.5000 1.0000
>> for i=1:size(a,2)
for j=1:size(a,2)
c(i,j)=sum((a(:,i)-mean(a(:,i))).*(a(:,j)-mean(a(:,j))))/(size(a,1)-1);
end
end
>> c
c =
10.3333 -4.1667 3.0000
-4.1667 2.3333 -1.5000
3.0000 -1.5000 1.0000
1.3 矩阵对角化
求出协方差矩阵的n个最大特征值,那么X*对应的特征向量,就得到降维n。
1.4 eig函数
E=eig(A):求矩阵A的全部特征值,构成向量E。
[V,D]=eig(A):求矩阵A的全部特征值,构成对角阵D,并求A的特征向量构成V的列向量。
[V,D]=eig(A,'nobalance'):与第2种格式类似,但第2种格式中先对A作相似变换后求矩阵A的特征值和特征向量,而格式3直接求矩阵A的特征值和特征向量。
E=eig(A,B):由eig(A,B)返回N×N阶方阵A和B的N个广义特征值,构成向量E。
[V,D]=eig(A,B):由eig(A,B)返回方阵A和B的N个广义特征值,构成N×N阶对角阵D,其对角线上的N个元素即为相应的广义特征值,同时将返回相应的特征向量构成N×N阶满秩矩阵,且满足AV=BVD。
>> a = [1 2 3; 4 5 6; 7 8 9]
a =
1 2 3
4 5 6
7 8 9
>> [b,c] = eig(a)
b =
-0.2320 -0.7858 0.4082
-0.5253 -0.0868 -0.8165
-0.8187 0.6123 0.4082
c =
16.1168 0 0
0 -1.1168 0
0 0 -0.0000
实验验证:X的标准化的协方差矩阵就是X的相关系数矩阵。
程序中是按列求方差等,这和PCA求协方差一样的。
>> X = a;
>> [p,n]=size(X);
for j=1:n
mju(j)=mean(X(:,j));
sigma(j)=sqrt(cov(X(:,j)));
end
for i=1:p
for j=1:n
Y(i,j)=(X(i,j)-mju(j))/sigma(j);
end
end
sigmaY=cov(Y);
%求X标准化的协差矩阵的特征根和特征向量
[T,lambda]=eig(sigmaY);
disp('特征根(由小到大):');
disp(lambda);
disp('特征向量:');
disp(T);
特征根(由小到大):
-0.0000 0 0
0 0 0
0 0 3.0000
特征向量:
0.4082 0.7071 0.5774
0.4082 -0.7071 0.5774
-0.8165 0 0.5774
>> R=corrcoef(X);
%求X相关系数矩阵的特征根和特征向量
[TR,lambdaR]=eig(R);
disp('特征根(由小到大):');
disp(lambdaR);
disp('特征向量:');
disp(TR);
特征根(由小到大):
-0.0000 0 0
0 0 0
0 0 3.0000 特征向量:
0.4082 0.7071 0.5774
0.4082 -0.7071 0.5774
-0.8165 0 0.5774
贡献率与累计贡献率。
%方差贡献率;累计方差贡献率
Xsum=sum(sum(lambda,2),1);
for i=1:n
fai(i)=lambda(i,i)/Xsum;
end
for i=1:n
psai(i)= sum(sum(lambda(1:i,1:i),2),1)/Xsum;
end
disp('方差贡献率:');
disp(fai);
disp('累计方差贡献率:');
disp(psai);
%综合评价....略
疑惑:第一个eig发现特征根由大到小排序了,第二个发现是由小到大排序了,并未认为哦干扰,咋回事?
1.5 STD函数
std(x) 算出x的标准偏差。 x可以是一行的matrix或者一个多行matrix矩阵,如果只有一行,那么就是算一行的标准偏差,如果有多行,就是算每一列的标准偏差。std(x,a)也是x的标准偏差但是a可以=0或者1.如果是0和前面没有区别,如果是1就是最后除以n,而不是n-1. (你参考计算标准偏差的公式,一般都用除以n-1的公式。)std (x, a,b)这里a表示是要用n还是n-1,如果是a是0就是除以n-1,如果是1就是除以n。
b这里是维数,比如说
1 2 3 4
4 5 6 1
如果b是1,就是按照行分,如果b是2就是按照列分,如果是三维的矩阵,b=3就按照第三维来分数据。
1.6 zscore函数
航向量:MATLAB执行代码就是 z = (x–mean(x))./std(x)。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。新数据=(原数据-均值)/标准差,用zscore函数,可以把数据进行z-score标准化处理。用法为Y=zscore(X),x为标准化之前的数据,y为标准化后的数据
特点:
(1)样本平均值为0,方差为1;
(2)区间不确定,处理后各指标的最大值、最小值不相同;
(3)对于指标值恒定的情况不适用;
(4)对于要求标准化后数据大于0 的评价方法(如几何加权平均法)不适用。
二.PCA解析
下面是百度百科中对pca降维的一段解释,还是挺清晰的:
“对于一个训练集,100个对象模板,特征是10维,那么它可以建立一个100*10的矩阵,作为样本。求这个样本的协方差矩阵,得到一个10*10的协方差矩阵,然后求出这个协方差矩阵的特征值和特征向量,应该有10个特征值和特征向量,我们根据特征值的大小,取前四个特征值所对应的特征向量,构成一个10*4的矩阵,这个矩阵就是我们要求的特征矩阵,100*10的样本矩阵乘以这个10*4的特征矩阵,就得到了一个100*4的新的降维之后的样本矩阵,每个特征的维数下降了。
2.1 基本解析
对同一个体进行多项观察时,必定涉及多个随机变量X1,X2,…,Xp,它们都是的相关性, 一时难以综合。这时就需要借助主成分分析 (principal component analysis)来概括诸多信息的主要方面。我们希望有一个或几个较好的综合指标来概括信息,而且希望综合指标互相独立地各代表某一方面的性质。
任何一个度量指标的好坏除了可靠、真实之外,还必须能充分反映个体间的变异。如果有一项指标,不同个体的取值都大同小异,那么该指标不能用来区分不同的个体。由这一点来看,一项指标在个体间的变异越大越好。因此我们把“变异大”作为“好”的标准来寻求综合指标。
PCA(Principal Component Analysis)不仅仅是对高维数据进行降维,更重要的是经过降维去除了噪声,发现了数据中的模式。
PCA把原先的n个特征用数目更少的m个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的m个特征互不相关。从旧特征到新特征的映射捕获数据中的固有变异性。
2.2 对PCA的理解
PCA简单的说,它是一种通用的降维工具。在我们处理高维数据的时候,了能降低后续计算的复杂度,在“预处理”阶段通常要先对原始数据进行降维,而PCA就是干这个事的
本质上讲,PCA就是将高维的数据通过线性变换投影到低维空间上去,但这个投影可不是随便投投,
遵循一个指导思想,那就是:找出最能够代表原始数据的投影方法。这里怎么理解这个思想呢?“最
表原始数据”希望降维后的数据不能失真,也就是说,被PCA降掉的那些维度只能是那些噪声或是冗
数据。这里的噪声和冗余我认为可以这样认识:
噪声:我们常说“噪音污染”,意思就是“噪声”干扰我们想听到的真正声音。同样,假设样本中某
主要的维度A,它能代表原始数据,是“我们真正想听到的东西”,它本身含有的“能量”(即该维度
方差,为啥?别急,后文该解释的时候就有啦~)本来应该是很大的,但由于它与其他维度有那
些千丝万缕的相关性,受到这些个相关维度的干扰,它的能量被削弱了,我们就希望通过PCA处
理后,使维度A与其他维度的相关性尽可能减弱,进而恢复维度A应有的能量,让我们“听的更清
楚”!
冗余:冗余也就是多余的意思,就是有它没它都一样,放着就是占地方。同样,假如样本中有
个维度,在所有的样本上变化不明显(极端情况:在所有的样本中该维度都等于同一个数),也
说该维度上的方差接近于零,那么显然它对区分不同的样本丝毫起不到任何作用,这个维度即
冗余的,有它没它一个样,所以PCA应该去掉这些维度。
PCA的目的就是“降噪”和“去冗余”。“降噪”的目的就是使保留下来的维度间的相关性尽可
能小,而“去冗余”的目的就是使保留下来的维度含有的“能量”即方差尽可能大。
那首先的首先,我们得需那有什么数据结构能同时表现不同维度间的相关性以及各个维度上的方差呢?自然是非协方差矩阵莫属。协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。协方差矩阵的主对角线上的元素是各个维度上的方差(即能量),其他元素是两两维度间的协方差(即相关性)。我们要的东西协方差矩阵都有了,先来看“降噪”,让保留下的不同维度间的相关性尽可能小,也就是说让协方差矩阵中非对角线元素都基本为零。达到这个目的的方式自然不用说,线代中奖的很明确——矩阵对角化。而对角化后得到的矩阵,其对角线上是协方差矩阵的特征值,它还有两个身份:首先,它还是各个维度上的新方差;其次,它是各个维度本身应该拥有的能量(能量的概念伴随特征值而来)。这也就是我们为何在前面称“方差”为“能量”的原因。也许第二点可能存在疑问,但我们应该注意到这个事实,通过对角化后,剩余维度间的相关性已经减到最弱,已经不会再受“噪声”的影响了,故此时拥有的能量应该比先前大了。看完了“降噪”,我们的“去冗余”还没完呢。对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉即可。PCA的本质其实就是对角化协方差矩阵。
2.3 PCA过程
PCA过程
1.特征中心化。即每一维的数据都减去该维的均值。这里的“维”指的就是一个特征(或属性),变换之后每一维的均值都变成了0。每一列减去该列均值后,得到矩阵B:
2.计算B的协方差矩阵C:
3.计算协方差矩阵C的特征值和特征向量。
4.选取大的特征值对应的特征向量,得到新的数据集。
三.PCA实现
在此只讲一些个人理解,并没有用术语,只求通俗。贡献率:每一维数据对于区分整个数据的贡献,贡献率最大的显然是主成分,第二大的是次主成分......
[coef,score,latent,t2] = princomp(x);LATENT协方差矩阵的特征值。SCORE是对主分的打分,也就是说原X矩阵在主成分空间的表示。COEFF是X矩阵所对应的协方差阵V的所有特征向量组成的矩阵,即变换矩阵或称投影矩阵。用你的原矩阵x*coeff(:,1:n)才是你要的的新数据,其中的n是你想降到多少维。
1.latent:是一个列向量,由X的协方差矩阵的特征值组成.不是X的特征值,即 latent = sort(eig(cov(X)),'descend');
2.这里的SCORE指的是原始数据在新生成的主成分空间里的坐标值。zscore(x)是归一化的函数.即z-scores z = (x–mean(x))./std(x),两者不是一回事。
参考文献:
http://blog.csdn.net/wangzhiqing3/article/details/12192663
http://www.cnblogs.com/cvlabs/archive/2010/05/08/1730319.html
http://www.cnblogs.com/zhangchaoyang/articles/2222048.html
http://blog.csdn.net/wangzhiqing3/article/details/12193131
http://blog.sciencenet.cn/blog-265205-544681.html
http://blog.sina.com.cn/s/blog_61c0518f0100f4mi.html
http://blog.csdn.net/s334wuchunfangi/article/details/8169928
http://blog.sina.com.cn/s/blog_6833a4df0100pwma.html
http://www.ilovematlab.cn/thread-54493-1-1.html
初识PCA数据降维的更多相关文章
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
- PCA数据降维
Principal Component Analysis 算法优缺点: 优点:降低数据复杂性,识别最重要的多个特征 缺点:不一定需要,且可能损失有用的信息 适用数据类型:数值型数据 算法思想: 降维的 ...
- 数据降维-PCA主成分分析
1.什么是PCA? PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法.PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特 ...
- Coursera《machine learning》--(14)数据降维
本笔记为Coursera在线课程<Machine Learning>中的数据降维章节的笔记. 十四.降维 (Dimensionality Reduction) 14.1 动机一:数据压缩 ...
- 数据降维技术(2)—奇异值分解(SVD)
上一篇文章讲了PCA的数据原理,明白了PCA主要的思想及使用PCA做数据降维的步骤,本文我们详细探讨下另一种数据降维技术—奇异值分解(SVD). 在介绍奇异值分解前,先谈谈这个比较奇怪的名字:奇异值分 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- TSNE数据降维学习【转载】
转自:https://blog.csdn.net/u012162613/article/details/45920827 https://www.jianshu.com/p/d6e7083d7d61 ...
- 数据降维(Dimensionality reduction)
数据降维(Dimensionality reduction) 应用范围 无监督学习 图片压缩(需要的时候在还原回来) 数据压缩 数据可视化 数据压缩(Data Compression) 将高维的数据转 ...
随机推荐
- js 获取url 参数
$(function () { var WeixinCode = GetQueryString("WeixinCode"); $("#ProXQ").attr( ...
- Objective-C 【autorelease基本使用】
------------------------------------------- NSString中的内存管理问题 由于autoreleasepool的存在,对于内存管理就会很复杂,retain ...
- 20141009---Visual Studio 2012 预定义数据类型
预定义数据类型 一.值类型 整型:(整数) 有符号整型和无符号整形,区别是有符号的有负数无符号的都是正数, 2x+1 常用int 有符号: 带有正负数,范围为按所写依次增大 ...
- webSphere集群部署主要步骤
1.系统管理-节点,添加本机节点和另外一台机器的节点2.建立集群服务cluster,添加成员节点3.将应用部署到集群服务cluster4.将数据库源分别建立到节点作用域5.后续步骤参照安装手册 注意事 ...
- JS源码(条件的判定,循环,数组,函数,对象)整理摘录
--- title: JS学习笔记-从条件判断语句到对象创建 date: 2016-04-28 21:31:13 tags: [javascript,front-end] ---JS学习笔记——整理自 ...
- js获取url及url参数的方法
<script language="JavaScript" type="text/javascript"> function GetUrlParms ...
- 解决ubuntu 14.04 下eclipse 3.7.2 不能启动,报Could not detect registered XULRunner to use 或 org.eclipse.swt.SWTError: XPCOM 等问题的处理
对于eclipse 3.7.2在ubuntu 14.04下不能启动,需要在 eclipse/configuration 目录下的config.ini文件内增加一行org.eclipse.swt.bro ...
- Spring.Net的Ioc功能基本配置
Spring.NET是一个应用程序框架,其目的是协助开发人员创建企业级的.NET应用程序.它提供了很多方面的功能,比如依赖注入.面向方面编程(AOP).数据访问抽象及ASP.NET扩展等等. Spri ...
- php出现“syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM”错误的一种情况,及解决方法
PHP中的“syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM”错误,可能是因为美元符号$的误用,看下面一种情况 class Test{ s ...
- How to running Job from a Form
For Example we wanna run a Job with name "FAN_TableList_CSV". So you must create a button ...