图像处理中kmeans聚类算法C++实现
Kmeans聚类算法是十分常用的聚类算法,给定聚类的数目N,Kmeans会自动在样本数据中寻找N个质心,从而将样本数据分为N个类别。下面简要介绍Kmeans聚类原理,并附上自己写的Kmeans聚类算法实现。
一、Kmeans原理
1. 输入:一组数据data,设定需要聚类的类别数目ClusterCnt,设定迭代次数IterCnt,以及迭代截止精度eps
输出:数据data对应的标签label,每一个数据都会对应一个label(范围0 ~ ClusterCnt-1),表示该数据属于哪一类。
2. 首先,选取初始ClusterCnt个质心位置,选取初始质心位置很重要。一般原则是这ClusterCnt个质心在数值上相互差别越远越好(距离越大越好)。偷懒的做法就是随机选取,或者是选取前面ClusterCnt个数据作为初始质心。但是前提是初始质心数值不能存在重复或者相等的情况。
3. 开始聚类,这是一个迭代过程。先针对每一个数据,计算其与每个质心之间的距离(差别),选取距离最小的对应的质心,将其归为一类(设置为同一个标签值),依次遍历所有数据。这样第一次迭代后,所有数据都有一个标签值。
4. 计算新的质心。每一次迭代完成后,计算每个类别中数据中的均值,将此均值作为新的质心,进行下一轮的迭代。这样每一轮迭代后都会重新计算依次质心。直到满足5中的条件。
5. 每次迭代后,计算每个类别中数值的方差值,然后求出所有类别方差值得均值var,将var作为一个判别准则,当本次var与上次var之间的变化小于eps时,或者迭代次数大于iterCnt时,停止迭代,聚类完成。
6. 输出数据的标签。相同标签值得被kmeans聚为一类,这样所有数据就被聚类为设定的ClusterCnt个类别。
二、图像中的应用
简单的将kmeans算法应用于图像中像素点的分类,每个像素点的RGB值作为输入数据,计算像素点与质心之间的距离,不断迭代,直到所有像素点都有一个标签值。根据标签图像将原图像中同一类别设定相同颜色,不同类别设定不同颜色。可用于图像分割等。
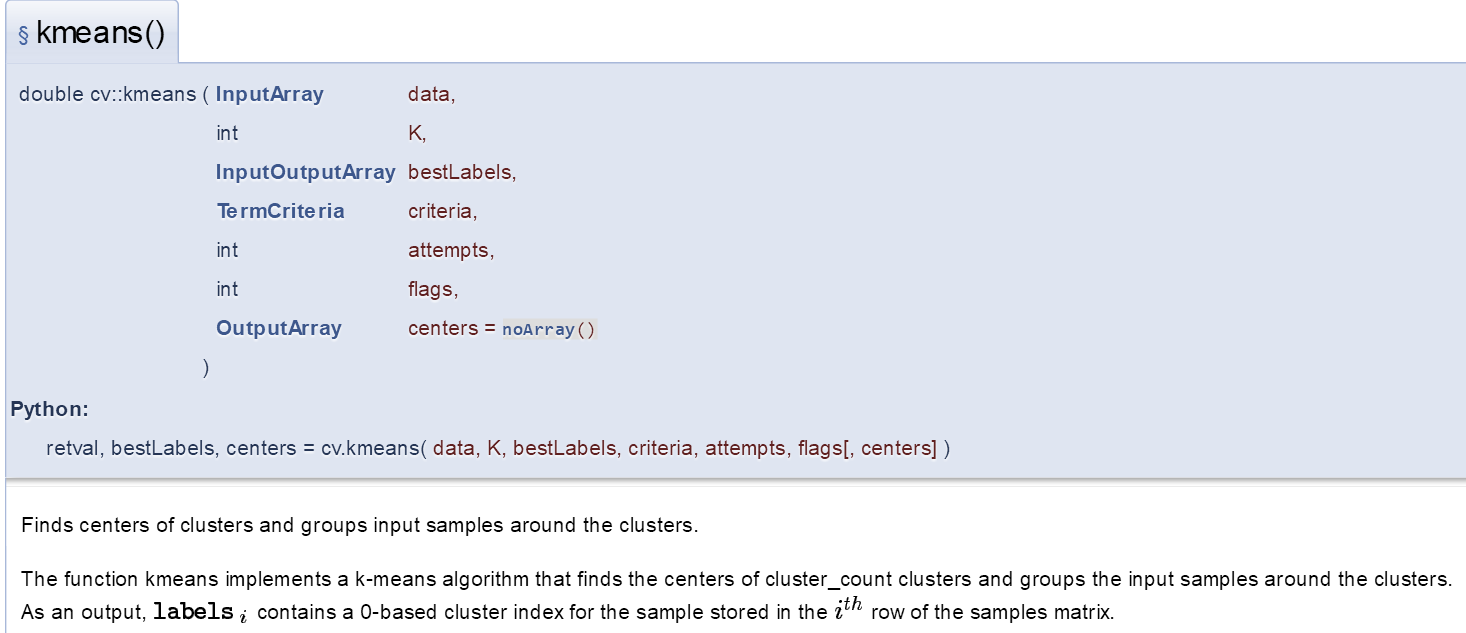
OpenCV中也集成有Kmeans算法的API,如下图,其选取初始质心有三种flag可以设置,随机选取、某种算法选取、用户设定。具体使用方法请参考OpenCV文档。
三、示例
原图 kmeans聚类 (10类)


四、代码
见我的码云code:https://gitee.com/rxdj/myKmeans.git
图像处理中kmeans聚类算法C++实现的更多相关文章
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析
原文地址:http://www.cnblogs.com/zjiaxing/p/5548265.html 在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/d ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)
在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/dorian3d/DBoW2,而bag of words 又运用了数据挖掘的K-means聚类算法,笔者只 ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- OpenCV图像处理中“投影技术”的使用
本文区分"问题引出"."概念抽象"."算法实现"三个部分由表及里具体讲解OpenCV图像处理中"投影技术" ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
随机推荐
- Python:每日一题005
题目: 输入三个整数x,y,z,请把这三个数由小到大输出. 程序分析: 我们想办法把最小的数放到x上,先将x与y进行比较,如果x>y则将x与y的值进行交换,然后再用x与z进行比较,如果x> ...
- 快速解决MariaDB无密码就可以登录的问题
mysql Ver 15.1 Distrib 10.1.37-MariaDB, for Linux (x86_64) using readline 5.1 #mysql -uroot -p #del ...
- 【轻松前端之旅】<a>元素妙用
浏览器读取服务器内容时,通过URL(包含:协议+域名+绝对路径)如:https://www.baidu.com/index.html浏览器从本地读取内容时,会用file协议.如:file:///E:/ ...
- qhfl-6 购物车
购物车中心 用户点击价格策略加入购物车,个人中心可以查看自己所有购物车中数据 在购物车中可以删除课程,还可以更新购物车中课程的价格策略 所以接口应该有四种请求方式, get,post,patch,de ...
- JAVA 8 主要新特性 ----------------(二)JDK1.8优点概括
一.JDK1.8优点概括 1.速度更快 由于底层结构和JVM的改变,使得JDK1.8的速度提高. 2.代码更少(增加了新的语法 Lambda 表达式) 增加新特性Lambda表达式的 ...
- JSP的分页技术
在实际应用中,如果从数据库中查询的记录特别的多,甚至超过了显示屏的显示范围,这个时候可将结果进行分页显示. 假设总记录数为intRowCount,每页显示的数量为inPageSize,总页数为intP ...
- verilog HDL-并行语句之assign
线网型数据对象: 是verilog hdl常用数据对象之一,起到电路节点之间的互联作用,类似于电路板上的导线. wire是verilog hdl默认的线网型数据对象. 线网型数据对象的读操作在代码任何 ...
- WCF双工通信单工通信
1.单工模式 单向通信,指通信只有一个方向进行,即从客户端流向服务,服务不会发送响应,而客户端也不会期望会有响应.这种情况下,客户端发送消息,然后继续执行 运行后报错: 2.双工模式 双工模式的特点是 ...
- SDWebImage之SDWebImageManager
SDWebImageManager是SDWebImage的核心类.它拥有一个SDWebImageCache和一个SDWebImageDownloader属性,分别用于图片的缓存和下载处理.虽然是核心类 ...
- Markdown新手教程
目录 什么是Markdown? 用Markdown写作有什么优缺点? 有哪些比较好的Markdown写作工具? markdown语法 标题 水平分区线 引用 中划线 斜体 粗体 斜粗体 链接 图片 无 ...