时间序列分解算法:STL
1. 详解
STL (Seasonal-Trend decomposition procedure based on Loess) [1] 为时序分解中一种常见的算法,基于LOESS将某时刻的数据\(Y_v\)分解为趋势分量(trend component)、周期分量(seasonal component)和余项(remainder component):
\]
STL分为内循环(inner loop)与外循环(outer loop),其中内循环主要做了趋势拟合与周期分量的计算。假定\(T_v^{(k)}\)、\(S_v{(k)}\)为内循环中第k-1次pass结束时的趋势分量、周期分量,初始时\(T_v^{(k)} = 0\);并有以下参数:
- \(n_{(i)}\)内层循环数,
- \(n_{(o)}\)外层循环数,
- \(n_{(p)}\)为一个周期的样本数,
- \(n_{(s)}\)为Step 2中LOESS平滑参数,
- \(n_{(l)}\)为Step 3中LOESS平滑参数,
- \(n_{(t)}\)为Step 6中LOESS平滑参数。
每个周期相同位置的样本点组成一个子序列(subseries),容易知道这样的子序列共有共有\(n_(p)\)个,我们称其为cycle-subseries。内循环主要分为以下6个步骤:
- Step 1: 去趋势(Detrending),减去上一轮结果的趋势分量,\(Y_v - T_v^{(k)}\);
- Step 2: 周期子序列平滑(Cycle-subseries smoothing),用LOESS (\(q=n_{n(s)}\), \(d=1\))对每个子序列做回归,并向前向后各延展一个周期;平滑结果组成temporary seasonal series,记为$C_v^{(k+1)}, \quad v = -n_{(p)} + 1, \cdots, -N + n_{(p)} $;
- Step 3: 周期子序列的低通量过滤(Low-Pass Filtering),对上一个步骤的结果序列\(C_v^{(k+1)}\)依次做长度为\(n_(p)\)、\(n_(p)\)、\(3\)的滑动平均(moving average),然后做LOESS (\(q=n_{n(l)}\), \(d=1\))回归,得到结果序列\(L_v^{(k+1)}, \quad v = 1, \cdots, N\);相当于提取周期子序列的低通量;
- Step 4: 去除平滑周期子序列趋势(Detrending of Smoothed Cycle-subseries),\(S_v^{(k+1)} = C_v^{(k+1)} - L_v^{(k+1)}\);
- Step 5: 去周期(Deseasonalizing),减去周期分量,\(Y_v - S_v^{(k+1)}\);
- Step 6: 趋势平滑(Trend Smoothing),对于去除周期之后的序列做LOESS (\(q=n_{n(t)}\), \(d=1\))回归,得到趋势分量\(T_v^{(k+1)}\)。
外层循环主要用于调节robustness weight。如果数据序列中有outlier,则余项会较大。定义
\]
对于位置为\(v\)的数据点,其robustness weight为
\]
其中\(B\)函数为bisquare函数:
{
\matrix {
{(1-u^2)^2 } & {for \quad 0 \le u < 1} \cr
{ 0} & {for \quad u \ge 1} \cr
}
}
\right.
\]
然后每一次迭代的内循环中,在Step 2与Step 6中做LOESS回归时,邻域权重(neighborhood weight)需要乘以\(\rho_v\),以减少outlier对回归的影响。STL的具体流程如下:
outer loop:
计算robustness weight;
inner loop:
Step 1 去趋势;
Step 2 周期子序列平滑;
Step 3 周期子序列的低通量过滤;
Step 4 去除平滑周期子序列趋势;
Step 5 去周期;
Step 6 趋势平滑;
为了使得算法具有足够的robustness,所以设计了内循环与外循环。特别地,当\(n_{(i)}\)足够大时,内循环结束时趋势分量与周期分量已收敛;若时序数据中没有明显的outlier,可以将\(n_{(o)}\)设为0。
R提供STL函数,底层为作者Cleveland的Fortran实现。Python的statsmodels实现了一个简单版的时序分解,通过加权滑动平均提取趋势分量,然后对cycle-subseries每个时间点数据求平均组成周期分量:
def seasonal_decompose(x, model="additive", filt=None, freq=None, two_sided=True):
_pandas_wrapper, pfreq = _maybe_get_pandas_wrapper_freq(x)
x = np.asanyarray(x).squeeze()
nobs = len(x)
...
if filt is None:
if freq % 2 == 0: # split weights at ends
filt = np.array([.5] + [1] * (freq - 1) + [.5]) / freq
else:
filt = np.repeat(1./freq, freq)
nsides = int(two_sided) + 1
# Linear filtering via convolution. Centered and backward displaced moving weighted average.
trend = convolution_filter(x, filt, nsides)
if model.startswith('m'):
detrended = x / trend
else:
detrended = x - trend
period_averages = seasonal_mean(detrended, freq)
if model.startswith('m'):
period_averages /= np.mean(period_averages)
else:
period_averages -= np.mean(period_averages)
seasonal = np.tile(period_averages, nobs // freq + 1)[:nobs]
if model.startswith('m'):
resid = x / seasonal / trend
else:
resid = detrended - seasonal
results = lmap(_pandas_wrapper, [seasonal, trend, resid, x])
return DecomposeResult(seasonal=results[0], trend=results[1],
resid=results[2], observed=results[3])
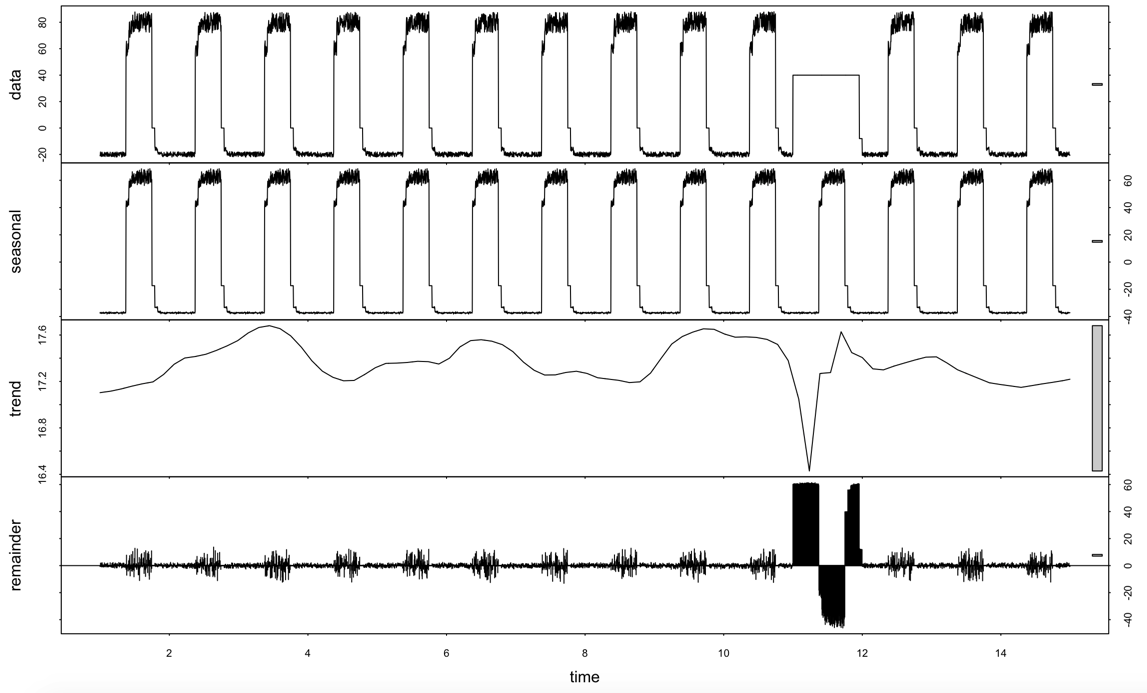
R版STL分解带噪音点数据的结果如下图:
data = read.csv("artificialWithAnomaly/art_daily_flatmiddle.csv")
View(data)
data_decomp <- stl(ts(data[[2]], frequency = 1440/5), s.window = "periodic", robust = TRUE)
plot(data_decomp)
statsmodels模块的时序分解的结果如下图:
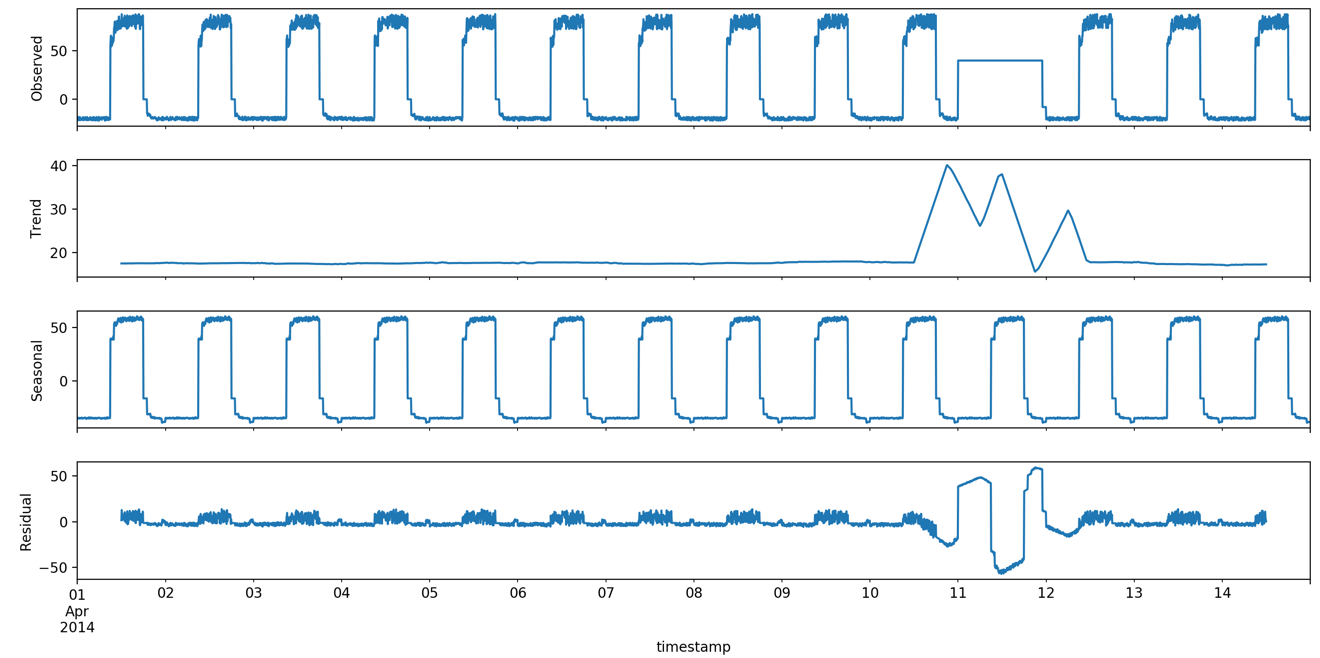
import statsmodels.api as sm
import matplotlib.pyplot as plt
import pandas as pd
from date_utils import get_gran, format_timestamp
dta = pd.read_csv('artificialWithAnomaly/art_daily_flatmiddle.csv',
usecols=['timestamp', 'value'])
dta = format_timestamp(dta)
dta = dta.set_index('timestamp')
dta['value'] = dta['value'].apply(pd.to_numeric, errors='ignore')
dta.value.interpolate(inplace=True)
res = sm.tsa.seasonal_decompose(dta.value, freq=288)
res.plot()
plt.show()
2. 参考资料
[1] Cleveland, Robert B., William S. Cleveland, and Irma Terpenning. "STL: A seasonal-trend decomposition procedure based on loess." Journal of Official Statistics 6.1 (1990): 3.
时间序列分解算法:STL的更多相关文章
- 时间序列分解-STL分解法
时间序列分解-STL分解法 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. STL(’Seasonal a ...
- R语言-时间序列
时间序列:可以用来预测未来的参数, 1.生成时间序列对象 sales <- c(18, 33, 41, 7, 34, 35, 24, 25, 24, 21, 25, 20, 22, 31, 40 ...
- 从时序异常检测(Time series anomaly detection algorithm)算法原理讨论到时序异常检测应用的思考
1. 主要观点总结 0x1:什么场景下应用时序算法有效 历史数据可以被用来预测未来数据,对于一些周期性或者趋势性较强的时间序列领域问题,时序分解和时序预测算法可以发挥较好的作用,例如: 四季与天气的关 ...
- 亿级用户百TB级数据的AIOps 技术实践之路
关于面临的挑战 "因为专业性强,我认为反而让交互方式变简单了,打个点餐的比方,软件1.0阶段是,我要吃鱼香肉丝,我要吃辣的或是素一点的,根据清晰的接口上菜.而软件2.0阶段就是,我今天想吃开 ...
- 时序分解算法:STL
1. 详解 STL (Seasonal-Trend decomposition procedure based on Loess) [1] 为时序分解中一种常见的算法,将某时刻的数据\(Y_v\)分解 ...
- 网络KPI异常检测之时序分解算法
时间序列数据伴随着我们的生活和工作.从牙牙学语时的“1, 2, 3, 4, 5, ……”到房价的走势变化,从金融领域的刷卡记录到运维领域的核心网性能指标.时间序列中的规律能加深我们对事物和场景的认识, ...
- 用R分析时间序列(time series)数据
时间序列(time series)是一系列有序的数据.通常是等时间间隔的采样数据.如果不是等间隔,则一般会标注每个数据点的时间刻度. time series data mining 主要包括decom ...
- 时间序列异常检测算法S-H-ESD
1. 基于统计的异常检测 Grubbs' Test Grubbs' Test为一种假设检验的方法,常被用来检验服从正太分布的单变量数据集(univariate data set)\(Y\) 中的单个异 ...
- 【R语言学习】时间序列
时序分析会用到的函数 函数 程序包 用途 ts() stats 生成时序对象 plot() graphics 画出时间序列的折线图 start() stats 返回时间序列的开始时间 end() st ...
随机推荐
- 问题 J: Palindromic Password ( 2018组队训练赛第十五场) (简单模拟)
问题 J: Palindromic Password 时间限制: 3 Sec 内存限制: 128 MB提交: 217 解决: 62[提交][状态][讨论版][命题人:admin] 题目描述 The ...
- JVM之基本结构
1. Java虚拟机的架构 1.1 Java的NIO库允许Java程序使用直接内存,访问直接内存的速度优于Java堆.出于性能的考虑,读写频繁的场合会考虑使用直接内存. 1.2 本地方法栈和Java栈 ...
- C# MediaHelper
using System.Text; public class MediaHelper { private static MediaHelper media = null; private Media ...
- 如何做出一个更好的Machine Learning预测模型【转载】
作者:文兄链接:https://zhuanlan.zhihu.com/p/25013834来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 初衷 这篇文章主要从工程角度来 ...
- 响应式网页:用em,rem设置网页字体大小自适应
「rem」是指根元素(root element,html)的字体大小,好开心的是,从遥远的 IE6 到版本帝 Chrome 他们都约好了,根元素默认的 font-size 都是 16px.这样一个新的 ...
- 翻转长方形 (不知名oj中一道个人私题)--单调栈维护最大子矩形
怎么分析这道题呢? 首先 ,我们注意到一点: 不管怎么操作,任意一个2*2方格中的 "#"个数的奇偶性是不变的. 所以,如果一个2*2方格中有奇数个"#",这个 ...
- [Win] Win8权限机制导致R安装包失败
在Rstudio安装tidyselect的时候,提示 ERROR: compilation failed for package ‘tidyselect’ 搜了一下,在github上找到tidysel ...
- jenkins部署node项目
docker run -d --name jenkins -p 8081:8080 -v /home/jenkins_home:/home/jenkins_home jenkins
- js数组去除重复
1. let arr = [1,2,1,2,3,5,4,5,3,4,4,4,4]; let result = arr.sort().reduce((init, current)=>{ if(in ...
- java里的基本数据类型和引用数据类型
一.基本数据类型: byte:Java中最小的数据类型,在内存中占8位(bit),即1个字节,取值范围-128~127,默认值0 short:短整型,在内存中占16位,即2个字节,取值范围-32768 ...