CDH-5.9.2整合spark2
1.编写目的:由于cdh-5.9.2自带spark版本是spark1.6,现需要测试spark2新特性,需要整合spark2,
且spark1.x和spark2.x可以同时存在于cdh中,无需先删除spark1.x;
2.安装包下载
2.1首先下载csd包,地址: http://archive.cloudera.com/spark2/csd/

2.2 parcel包下载地址:http://archive.cloudera.com/spark2/parcels/2.1.0.cloudera1/

需要注意的是要下载对应的版本和对应的操作系统包;
3.安装开始
将安装包放到对应目录,修改安装包所属用户,以及组,如下图:


将该节点执行 :
service cloudera-scm-server restart
service cloudera-scm-agent restart
然后点击主机->Parcel页面,看是否多了个spark2的选项。如下图,你这里此时应该是分配按钮,点击,等待操作完成后,点击激活按钮

然后在dashboard页面,向集群添加服务,就可以看到spark2:

我这里把spark2的history server装在了第三个节点:

至此,安装完成;
4.测试验证:
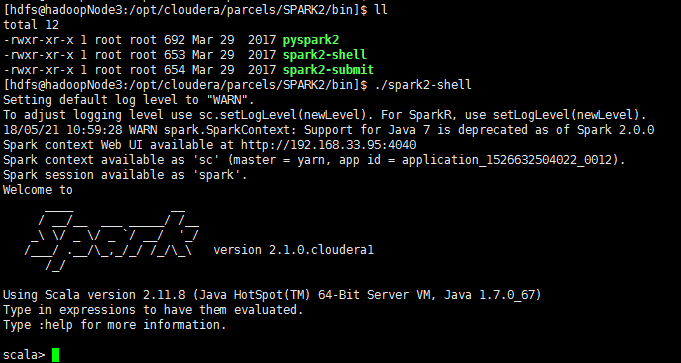
spark2-shell启动成功;
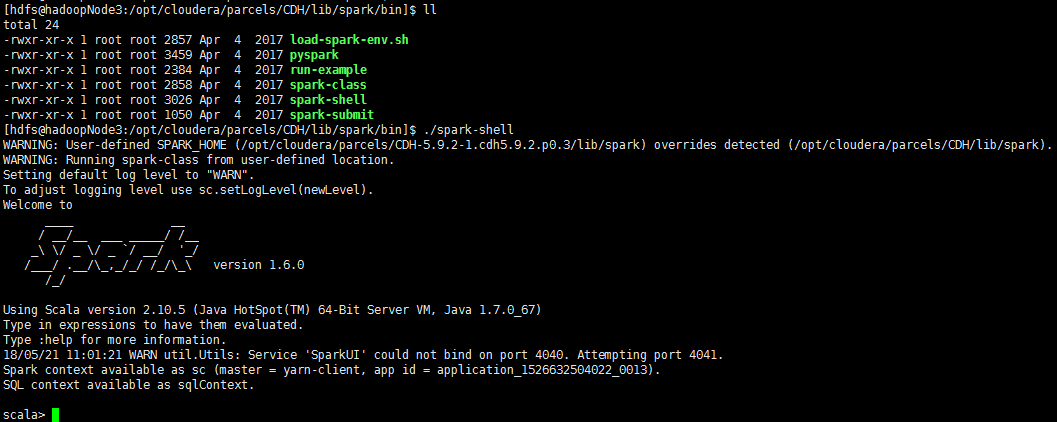
spark-shell,即spark1也启动成功;
=====》使用spark-submit模式几条job:
[hdfs@hadoopNode3:/opt/cloudera/parcels/SPARK2/bin]$ ./spark2-submit --master yarn --deploy-mode cluster --conf spark.driver.memory=2g --class org.apache.spark.examples.SparkPi --executor-cores 4 /opt/cloudera/parcels/CDH/lib/spark/examples/lib/spark-examples-1.6.0-cdh5.9.2-hadoop2.6.0-cdh5.9.2.jar
[hdfs@hadoopNode3:/opt/cloudera/parcels/CDH/lib/spark/bin]$ ./spark-submit --master yarn --deploy-mode cluster --conf spark.driver.memory=2g --class org.apache.spark.examples.SparkPi --executor-cores 4 /opt/cloudera/parcels/CDH/lib/spark/examples/lib/spark-examples-1.6.0-cdh5.9.2-hadoop2.6.0-cdh5.9.2.jar

可以看到用集群模式也都能运行job成功
五.问题总结:
1.在安装过程中,可能会碰到在向集群添加spark2这个服务时候,没有spark2这个选项,这个是csd文件没有放对路劲;
2.在集群其他节点运行spark2的时候,会报错
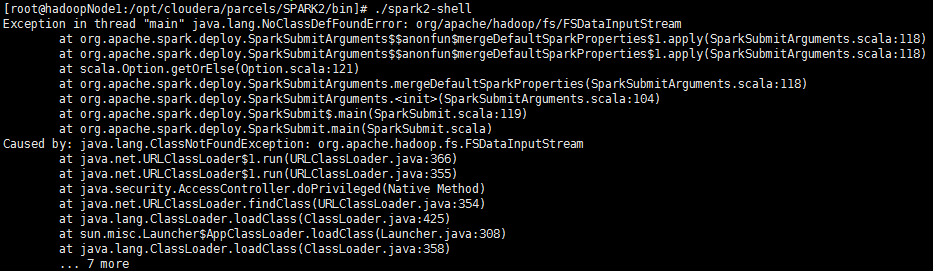
spark2安装在哪个节点,就要到对应节点运行,否则会有这个报错;
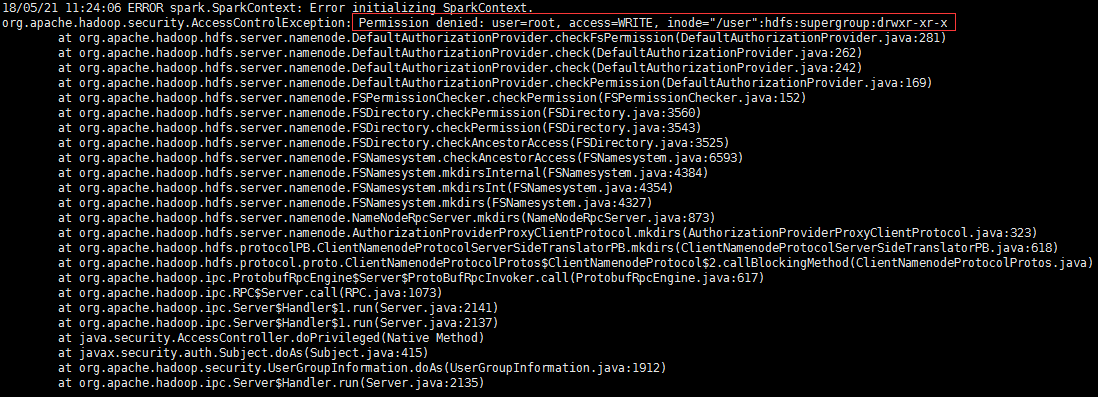
3.运行spark2对应命令,要切换到hdfs用户,否则会报错:
CDH-5.9.2整合spark2的更多相关文章
- CDH下集成spark2.2.0与kafka(四十一):在spark+kafka流处理程序中抛出错误java.lang.NoSuchMethodError: org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/util/Collection;)V
错误信息 19/01/15 19:36:40 WARN consumer.ConsumerConfig: The configuration max.poll.records = 1 was supp ...
- 开源版本 hadoop-2.7.5 + apache-hive-2.1.1 + spark-2.3.0-bin-hadoop2.7整合使用
一,开源软件版本: hadoop版本 : hadoop-2.7.5 hive版本 :apache-hive-2.1.1 spark版本: spark-2.3.0-bin-hadoop2.7 各个版本到 ...
- CentOS7安装CDH 第十章:CDH中安装Spark2
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- Ambari HDP 下 SPARK2 与 Phoenix 整合
1.环境说明 操作系统 CentOS Linux release 7.4.1708 (Core) Ambari 2.6.x HDP 2.6.3.0 Spark 2.x Phoenix 4.10.0-H ...
- spark-2.0.0与hive-1.2.1整合
SparkSQL与Hive的整合 1. 拷贝$HIVE_HOME/conf/hive-site.xml和hive-log4j.properties到 $SPARK_HOME/conf/ 2. 在$SP ...
- 将CDH中的hive和hbase相互整合使用
一..hbase与hive的兼容版本: hive0.90与hbase0.92是兼容的,早期的hive版本与hbase0.89/0.90兼容,不需要自己编译. hive1.x与hbase0.98.x或则 ...
- CDH spark2切换成anaconda3的问题
最近spark2有同事想用anaconda3做开发,原因是上面可以跑机器学习的库(服务器因为没外网pip装whl确实麻烦) 1.先在每台机器安装anaconda3 2.把用户的~/.bashrc配置进 ...
- SparkStreaming整合flume
SparkStreaming整合flume 在实际开发中push会丢数据,因为push是由flume将数据发给程序,程序出错,丢失数据.所以不会使用不做讲解,这里讲解poll,拉去flume的数据,保 ...
- geotrellis使用(二十五)将Geotrellis移植到spark2.0
目录 前言 升级spark到2.0 将geotrellis最新版部署到spark2.0(CDH) 总结 一.前言 事情总是变化这么快,前面刚写了一篇博客介绍如何将geotrellis移植 ...
随机推荐
- pthread使用
https://developer.apple.com/library/content/documentation/Cocoa/Conceptual/Multithreading/CreatingTh ...
- Linux 进程状态标识 Process State Definition
From : http://www.linfo.org/process_state.html 译者:李秋豪 进程状态标识是指在进程描述符中状态位的值. 进程,也可被称为任务,是指一个程序运行的实例. ...
- 【转】Spring boot 打成jar包问题总结
http://www.cnblogs.com/xingzc/p/5972488.html 1.Unable to find a single main class from the following ...
- SQL中char、varchar、nvarchar、text 的区别
char char是定长的,也就是当你输入的字符小于你指定的数目时,char(8),你输入的字符小于8时,它会再后面补空值.当你输入的字符大于指定的数时,它会截取超出的字符. nvarchar(n) ...
- Viewpager实现今日头条顶部导航的功能
利用简单的Textview 和Viewpager实现滑动.点击换页的效果,效果图如下: 先上布局文件代码: <?xml version="1.0" encoding=&quo ...
- 两台电脑在不同情况下ping的情况
两台计算机(交叉连接) 同一网段 ,可以ping通.不同网段,不可以 两台计算机通过一台交换机连接 同一网段 ,可以ping通.不同网段,不可以.同一网段,同一Vlan,不可以. 综上:跨网段通信,必 ...
- Vue+Electron实现简单桌面应用
之前一直使用C#编写桌面应用,也顺带写一些Web端应用.最近在看node时发现常用的vscode是用electron编写的,一种想吃螃蟹的念头就涌了上来. 在网上找了找electron的资料,也研究了 ...
- 1486: [HNOI2009]最小圈
Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 3129 Solved: 1543[Submit][Status][Discuss] Descripti ...
- 搭建docker registry (htpasswd 认证)
1,拉取docker registry 镜像 docker pull registry 2,创建证书存放目录 mkdir -p /home/registry 3,生成CA证书Edit your /et ...
- ES6、7、8、9新语法新特性
前言 如果你擅长这种扩散式学习方式,不妨再进一步温习一下整个 ES6 引入的新特性,笔者强烈推荐阮一峰老师的 ECMAScript 6 入门 一书. ES2018 引入的特性还太新,单在对 ES6 特 ...