推荐模型AutoRec:原理介绍与TensorFlow2.0实现
1. 简介
本篇文章先简单介绍论文思路,然后使用Tensoflow2.0、Keras API复现算法部分。包括:
自定义模型
自定义损失函数
自定义评价指标RMSE
就题目而言《AutoRec: Autoencoders Meet Collaborative Filtering》,自编码机遇见协同过滤,可见是使用自编码机结合协同过滤思想进行的算法。论文经过数据集Movielens和Netfix验证有不错的效果,更重要的是它是对特征交叉引入深度学习的开端,论文两页,简单易懂。
2. 算法模型
令m个用户,n个物品,构成用户-物品矩阵,每个物品对被用户进行评分。根据协同过滤思想,有基于用户的方式,也有基于物品的方式,取决于输入是物品分表示的用户向量,还是用户评分表示物品向量$r{i},r{u}$。自编码机部分将评分向量进行低维压缩,用低维空间表示评分向量,并对向量不同部分进行交叉,然后重构向量。
算法模型图为:
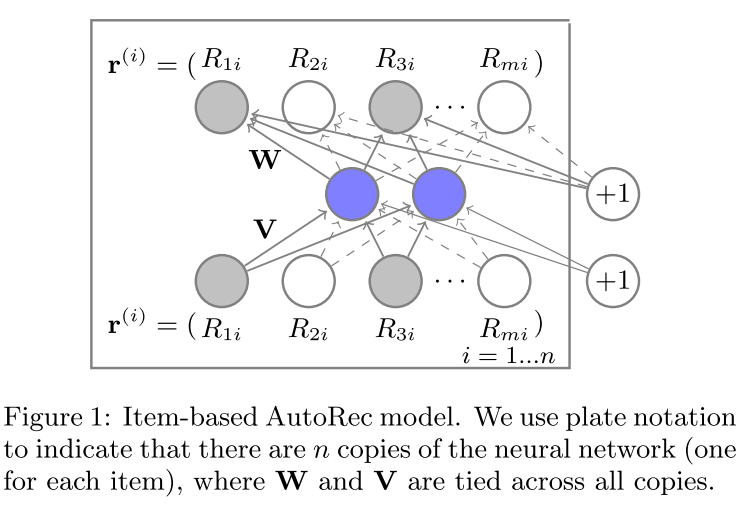
采用的模型公式为(基本就是逻辑回归的方式):
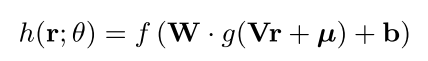
其中,中间的神经元数量,即映射低维空间设为k,则k是一个超参数根据效果进行调控。
需要注意的部分是
每个评分向量(无论物品还是用户向量),都存在稀疏性即没有用户对其进行评分,则在反向传播的过程中不能考虑这部分内容;
为了防止过拟合,需要在损失函数中添加W和V参数矩阵正则化:
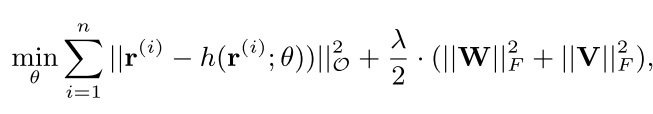
前一部分为真实值与预测值的平方误差(仅仅计算有评分的部分),第二部分为正则项,所求为F范数。
预测公式:
若是基于物品的AutoRec(I-AutoRec)则,输入待求的物品向量,到下面预测公式中,得到一个完整的向量,求第几个用户就取第几个维度从而得到此用户对此物品的评分,即

基于用户的AutoRec(U-AutoRec)表示类似。
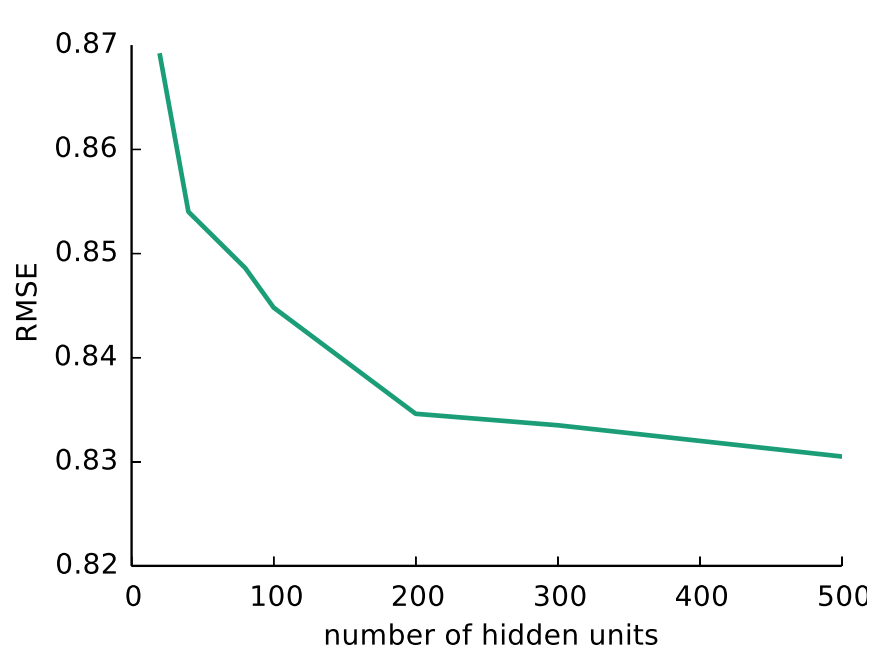
实验验证
论文的评价方式,使用的RMSE,与其他算法比较得到比较好的参数是k=500,f映射使用线性函数,g映射使用Sigmoid函数。

3. 代码复现
复现包括网络模型,损失函数,以及评价指标三部分,由于部分的改动不能直接使用TF原生的库函数。
首先导入需要使用的工具包:
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
定义模型
基于Keras的API的模型定义需要继承Model类,重写方法call(前向传播过程),如果需要加入dropout的模型需要将训练和预测分开可以使用参数training=None的方式来指定,这里不需要这个参数,因此省略。
class AutoRec(keras.Model):
def __init__(self, feature_nums, hidden_units, **kwargs):
super(AutoRec, self).__init__()
self.feature_nums = feature_nums # 基于物品则为物品特征数-即用户数,基于用户则为物品数量
self.hidden_units = hidden_units # 论文中的k参数
self.encoder = keras.layers.Dense(self.hidden_units, input_shape=[self.feature_nums], activation='sigmoid') # g映射
self.decoder = keras.layers.Dense(self.feature_nums, input_shape=[self.hidden_units]) # f映射
def call(self, X):
# 前向传播
h = self.encoder(X)
y_hat = self.decoder(h)
return y_hat
定义损失函数
此损失函数虽然为MSE形式,但是在计算的过程中发现,仅仅计算有评分的部分,无评分部分不进入损失,同时还有正则化,这里一起写出来。
基于Keras API的方式,需要继承Loss类,和方法call初始化传入model参数为了取出W和V参数矩阵。
mask_zero表示没有评分的部分不进入损失函数,同时要保证数据类型统一tf.int32,tf.float32否则会报错。
class Mse_Reg(keras.losses.Loss):
def __init__(self, model, reg_factor=None):
super(Mse_Reg, self).__init__()
self.model = model
self.reg_factor = reg_factor
def call(self, y_true, y_pred) :
y_sub = y_true - y_pred
mask_zero = y_true != 0
mask_zero = tf.cast(mask_zero, dtype=y_sub.dtype)
y_sub *= mask_zero
mse = tf.math.reduce_sum(tf.math.square(y_sub)) # mse损失部分
reg = 0.0
if self.reg_factor is not None:
weight = self.model.weights
for w in weight:
if 'bias' not in w.name:
reg += tf.reduce_sum(tf.square(w)) # 求矩阵的Frobenius范数的平方
return mse + self.reg_factor * 0.5 * reg
return mse
定义RMSE评价指标
定义评价指标需要继承类Metric,方法update_state和result以及reset,reset方法感觉使用较少,主要是更新状态和得到结果。
class RMSE(keras.metrics.Metric):
def __init__(self):
super(RMSE, self).__init__()
self.res = self.add_weight(name='res', dtype=tf.float32, initializer=tf.zeros_initializer())
def update_state(self, y_true, y_pred, sample_weight=None):
y_sub = y_true - y_pred
mask_zero = y_true != 0
mask_zero = tf.cast(mask_zero, dtype=y_sub.dtype)
y_sub *= mask_zero
values = tf.math.sqrt(tf.reduce_mean(tf.square(y_sub)))
self.res.assign_add(values)
def result(self):
return self.res
定义数据集
定义好各个部分之后,就可以构造训练集然后训练模型了。
get_data表示从path中加载数据,然后加数据通过pandas的透视表功能构造一个行为物品,列为用户的矩阵;
data_iter表示通过tf.data构造数据集。
# 定义数据
def get_data(path, base_items=True):
data = pd.read_csv(path)
rate_matrix = pd.pivot_table(data, values='rating', index='movieId', columns='userId',fill_value=0.0)
if base_items:
return rate_matrix
else :
return rate_matrix.T
def data_iter(df, shuffle=True, batch_szie=32, training=False) :
df = df.copy()
X = df.values.astype(np.float32)
ds = tf.data.Dataset.from_tensor_slices((X, X)).batch(batch_szie)
if training:
ds = ds.repeat()
return ds
训练模型
万事俱备,就准备数据放给模型就好了。
要说明的是,如果fit的时候不设置steps_per_epoch会在数据量和batch大小不能整除的时候报迭代器的超出范围的错误。设置了此参数当然也要加上validation_steps=2,不然还是会报错,不信可以试试看。
path = 'ratings.csv' # 我这里用的是10w数据,不是原始的movielens-1m
# I-AutoRec,num_users为特征维度
rate_matrix = get_data(path)
num_items, num_users = rate_matrix.shape
# 划分训练测试集
BARCH = 128
train, test = train_test_split(rate_matrix, test_size=0.1)
train, val = train_test_split(train, test_size=0.1)
train_ds = data_iter(train, batch_szie=BARCH, training=True)
val_ds = data_iter(val, shuffle=False)
test_ds = data_iter(test, shuffle=False)
# 定义模型
net = AutoRec(feature_nums=num_users, hidden_units=500) # I-AutoRec, k=500
net.compile(loss=Mse_Reg(net), #keras.losses.MeanSquaredError(),
optimizer=keras.optimizers.Adam(),
metrics=[RMSE()])
net.fit(train_ds, validation_data=val_ds, epochs=10, validation_steps=2, steps_per_epoch=train.shape[0]//BARCH)
loss, rmse = net.evaluate(test_ds)
print('loss: ', loss, ' rmse: ', rmse)
预测
df = test.copy()
X = df.values.astype(np.float32)
ds = tf.data.Dataset.from_tensor_slices(X) # 这里没有第二个X了
ds = ds.batch(32)
pred = net.predict(ds)
# 随便提出来一个测试集中有的评分看看预测的分数是否正常,pred包含原始为0.0的分数现在已经预测出来分数的。
print('valid: pred user1 for item1: ', pred[1][X[1].argmax()], 'real: ', X[1][X[1].argmax()])
得到结果(没有达到论文的精度,可能是数据量不足,而valid部分可以看到预测的精度还是凑合的):

4. 小结
本篇文章主要是针对AutoRec论文的主要部分进行了介绍,然后使用TensorFlow2.0的Keras接口实现了自定义的模型,损失,以及指标,并训练了I-AutoRec模型。
关于AutoRec要说的是,
编码器部分如果使用深层网络比如三层会增加预测的准确性;
自编码器部分的输出向量经过了编码过程的泛化相当于对缺失部分有了预测能力,这是自编码机用于推荐的原因;
I-AutoRec推荐过程,需要输入物品的矩阵然后得到每个用户对物品的预测评分,然后取用户自己评分的Top可以进行推荐,U-AutoRec只需要输入一次目标用户的向量就可以重建用户对所有物品的评分,然后得到推荐列表,但是用户向量可能稀疏性比较大影响最终的推荐效果。
AutoRec使用了单层网络,存在表达能力不足的问题,但对于基于机器学习的矩阵分解,协同过滤来说,由于这层网络的加入特征的表达能力得到提高。
推荐模型AutoRec:原理介绍与TensorFlow2.0实现的更多相关文章
- 推荐模型DeepCrossing: 原理介绍与TensorFlow2.0实现
DeepCrossing是在AutoRec之后,微软完整的将深度学习应用在推荐系统的模型.其应用场景是搜索推荐广告中,解决了特征工程,稀疏向量稠密化,多层神经网路的优化拟合等问题.所使用的特征在论文中 ...
- 推荐模型NeuralCF:原理介绍与TensorFlow2.0实现
1. 简介 NCF是协同过滤在神经网络上的实现--神经网络协同过滤.由新加坡国立大学与2017年提出. 我们知道,在协同过滤的基础上发展来的矩阵分解取得了巨大的成就,但是矩阵分解得到低维隐向量求内积是 ...
- 一文上手TensorFlow2.0(一)
目录: Tensorflow2.0 介绍 Tensorflow 常见基本概念 从1.x 到2.0 的变化 Tensorflow2.0 的架构 Tensorflow2.0 的安装(CPU和GPU) Te ...
- TensorFlow模型部署到服务器---TensorFlow2.0
前言 当一个TensorFlow模型训练出来的时候,为了投入到实际应用,所以就需要部署到服务器上.由于我本次所做的项目是一个javaweb的图像识别项目.所有我就想去寻找一下java调用Tenso ...
- 『TensorFlow2.0正式版教程』极简安装TF2.0正式版(CPU&GPU)教程
0 前言 TensorFlow 2.0,今天凌晨,正式放出了2.0版本. 不少网友表示,TensorFlow 2.0比PyTorch更好用,已经准备全面转向这个新升级的深度学习框架了. 本篇文章就 ...
- Google工程师亲授 Tensorflow2.0-入门到进阶
第1章 Tensorfow简介与环境搭建 本门课程的入门章节,简要介绍了tensorflow是什么,详细介绍了Tensorflow历史版本变迁以及tensorflow的架构和强大特性.并在Tensor ...
- 04 MapReduce原理介绍
大数据实战(上) # MapReduce原理介绍 大纲: * Mapreduce介绍 * MapReduce2运行原理 * shuffle及排序 定义 * Mapreduce 最早是由googl ...
- [转]MySQL主从复制原理介绍
MySQL主从复制原理介绍 一.复制的原理 MySQL 复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新.删除等等).每个从服务器从主服务器接收主服务器已经记录到其二进制日志的保存的更新,以 ...
- ThinkPHP 的模型使用详细介绍--模型的核心(七)
原文:ThinkPHP 的模型使用详细介绍--模型的核心(七) 注意:本节是ThinkPhp框架对数据操作的核心处理部分 大家还是在这里看清楚可以将其剪切放到代码编辑器中查看 本章节给大家着重介绍模型 ...
随机推荐
- Atcoder ABC161 A~E
传送门 A - ABC Swap 1 #include <iostream> 2 #include <cstdio> 3 #include <cstring> 4 ...
- Strategic game POJ - 1463 树型dp
//题意:就是你需要派最少的士兵来巡查每一条边.相当于求最少点覆盖,用最少的点将所有边都覆盖掉//题解://因为这是一棵树,所以对于每一条边的两个端点,肯定要至少有一个点需要放入士兵,那么对于x-&g ...
- python代理池的构建2——代理ip是否可用的处理和检查
上一篇博客地址:python代理池的构建1--代理IP类的构建,以及配置文件.日志文件.requests请求头 一.代理ip是否可用的处理(httpbin_validator.py) #-*-codi ...
- 已处理证书链,但是在不受信任提供程序信任的根证书中终止 - Windows 7安装.Net Framework 4.6.2时出现此问题
https://blog.csdn.net/inchat/article/details/104294302
- WPF Animation For SizeChanged Of UIElement
效果图 学到一个新词: Show me the money 背景 这几天查资料,看到 CodeProject 上面的一篇 Post <Advanced Custom TreeView Layou ...
- servlet相关知识点
一.servlet的生命周期 Servlet(Sever Applet),全称是Java Servlet,是用java编写的服务器程序.Servlet是指任何实现了这个Servlet接口的类. ser ...
- python yield && scrapy yield
title: python yield && scrapy yield date: 2020-03-17 16:00:00 categories: python tags: 语法 yi ...
- UML类图设计神器 AmaterasUML 的配置及使用
最近写论文需要用到UML类图,但是自己画又太复杂,干脆找了个插件,是Eclipse的,也有IDEA的,在这里我简单说下Eclipse的插件AmaterasUML 的配置与使用吧. 点击这里下载Amat ...
- Java | 在 Java 中执行动态表达式语句: 前中后缀、Ognl、SpEL、Groovy、Jexl3
在一些规则集或者工作流项目中,经常会遇到动态解析表达式并执行得出结果的功能. 规则引擎是一种嵌入在应用程序中的组件,它可以将业务规则从业务代码中剥离出来,使用预先定义好的语义规范来实现这些剥离出来的业 ...
- three.js all in one
three.js all in one https://www.npmjs.com/package/three # yarn add three # OR $ npm i three https:// ...