4. Spark在集群上运行
*以下内容由《Spark快速大数据分析》整理所得。
读书笔记的第四部分是讲的是Spark在集群上运行的知识点。
一、Spark应用组件介绍
二、Spark在集群运行过程
三、Spark配置
四、Spark资源分配
一、Spark应用组件介绍
Spark应用组件有三个:驱动器、集群管理器和执行器。
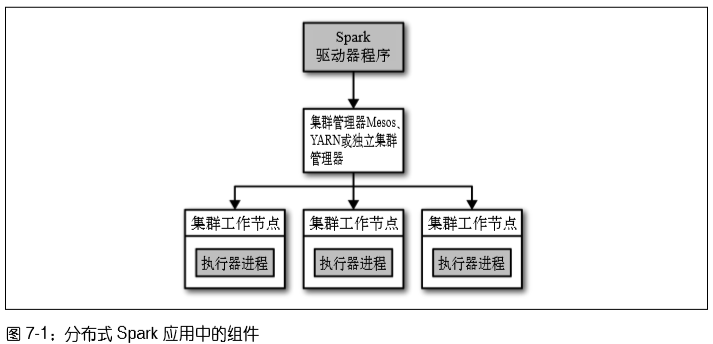
- 驱动器节点:有两个职责:把用户转为任务和为执行器节点调度任务。
- 执行器节点:负责在Spark作业中运作任务。
- 集群管理器:Spark依赖于集群管理器来启动执行器节点。
集群管理器:为了方便多人调度时合理的进行资源管理,许多集群管理器支持队列,可以为队列定义不同优先级或容量限制,这样Spark 就可以把作业提交到相应的队列中。
集群管理器分为两种:
(1) 独立集群管理器:由一个主节点和几个工作节点组成,各自都分配一定量的内存和CPU核心。可以在一堆机器上运行Spark。
(2) Hadoop YARN与Hadoop Mesos之类的集群管理器:能与别的分布式应用共享的集群。
二、Spark在集群运行过程
Spark在集群上运行的过程如下:
(1) 用户通过 spark-submit 脚本提交应用。
(2) spark-submit 脚本启动驱动器程序,调用用户定义的main()方法。
(3) 驱动器程序与集群管理器通信,申请资源以启动执行器节点。
(4) 集群管理器为驱动器程序启动执行器节点。
(5) 驱动器进程执行用户应用中的操作。根据程序中所定义的对 RDD 的转化操作和行动操作,驱动器节点把工作以任务的形式发送到执行器进程。
(6) 任务在执行器程序中进行计算并保存结果。
(7) 如果驱动器程序的main()方法退出,或者调用了 SparkContext.stop() ,驱动器程序会 终止执行器进程,并且通过集群管理器释放资源。
提交应用样本示例:
# [options] 是要传给 spark-submit 的标记列表
# <app jar | python File> 表示包含应用入口的 JAR 包或 Python 脚本。
# [app options] 是传给你的应用的选项
bin/spark-submit [options] <app jar | python file> [app options]
bin/spark-submit my_script.py
三、Spark配置
配置Spark有三种方式(优先级由高到低):
(1) SparkConf配置:在用户代码中显式调用 set() 。
# 创建一个conf对象
conf = new SparkConf() # 修改配置信息
conf.set("spark.app.name", "My Spark App")
conf.set("spark.master", "local[4]")
conf.set("spark.ui.port", "36000") # 重载默认端口配置 # 使用这个配置对象创建一个SparkContext
sc = SparkContext(conf)
(2) 命令行参数配置:通过 spark-submit --conf 传递参数。
# 在运行时使用标记设置配置项的值
$ bin/spark-submit \ --class com.example.MyApp \
--master local[4] \
--name "My Spark App" \
--conf spark.ui.port=36000 \
myApp.jar
(3) 配置文件配置: --properties-file 指向写好的配置文件的路径。
# 运行时使用默认文件设置配置项的值
bin/spark-submit \
--class com.example.MyApp \
--properties-file my-config.conf \
myApp.jar
四、Spark资源分配
在独立集群管理器中,资源分配的两个设置:
(1) 执行器进程内存: --executor-memory
(2) 占用核心总数的最大值: --total-executor-cores
例子:以--executor-memory 1G和--total-executor-cores 8提交应用,Spark会在不同机器上启动8个执行器进程,每个1GB内存。
YARN:--executor-memory和--executor-cores
Mesos:--executor-memory和--total-executor-cores
4. Spark在集群上运行的更多相关文章
- spark在集群上运行
1.spark在集群上运行应用的详细过程 (1)用户通过spark-submit脚本提交应用 (2)spark-submit脚本启动驱动器程序,调用用户定义的main()方法 (3)驱动器程序与集群管 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- 在集群上运行Spark
Spark 可以在各种各样的集群管理器(Hadoop YARN.Apache Mesos,还有Spark 自带的独立集群管理器)上运行,所以Spark 应用既能够适应专用集群,又能用于共享的云计算环境 ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
随机推荐
- mysql5.5和5.6的一些区别
timestamp 5.5中 直接写timestamp不加长度 5.6 中 写的timestamp(3) datatime 5.5中 直接写datetime 不加长度 5.6中 可以添加长度(3 ...
- 多测师讲解自动化测试 _RFalert弹框._高级讲师肖sir
alert弹框定位 Open Browser file:///D:\\bao\\baoan\\alert弹框.html gc sleep 2 Handle Alert accept #点击确定 Han ...
- python -re库
正则表达式的语法 正则表达式语法由字符和操作符构成 正则表达式的常用操作符: print("--正则表达式常用操作符--") mata="11356352135 abcd ...
- Linux最常用的命令大全
Linux最常用的命令大全 按功能索引 目录处理命令 ls mkdir pwd cd rmdir cp mv rm 文件处理命令 touch cat tac more less head tail l ...
- widows安装ffmpeg
首先下载ffmpeg的windows版本https://ffmpeg.zeranoe.com/builds/ 解压到d盘 win+r cmd 说明成功了
- 如何使用 Gin 和 Gorm 搭建一个简单的 API 服务 (一)
介绍 Go 语言最近十分火热,但对于新手来说,想立马上手全新的语法和各种各样的框架还是有点难度的.即使是基础学习也很有挺有挑战性. 在这篇文章中,我想用最少的代码写出一个可用的 API 服务. ...
- linux(centos8):awk在系统运维中的常用例子
一,awk的作用 1,用途 AWK是一种处理文本文件的语言, 是一个强大的文本分析工具 2,awk和sed的区别 awk适合按列(域)操作, sed适合按行操作 awk适合对文件的读取分析, sed适 ...
- C# Webservice中如何实现方法重载--(方法名同名时出现的问题)
本文摘抄自:http://blog.sina.com.cn/s/blog_53b720bb0100voh3.html 1.Webservice中的方法重载问题(1)在要重载的WebMethod上打个M ...
- CentOS 网卡固定地址配置
修改4个文件后重启网卡 vim /etc/default/grub GRUB_CMDLINE_LINUX="resume=UUID=05dbb36b-dbba-40a3-ba99-1b044 ...
- Spring In Action 5th中的一些错误
引言 最近开始学习Spring,了解到<Spring实战>已经出到第五版了,遂打算跟着<Spring实战(第五版)>来入门Spring,没想到这书一点也不严谨,才看到第三章就发 ...