scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):
在手机端打开慕课网,fiddler查看如图注意圈起来的位置
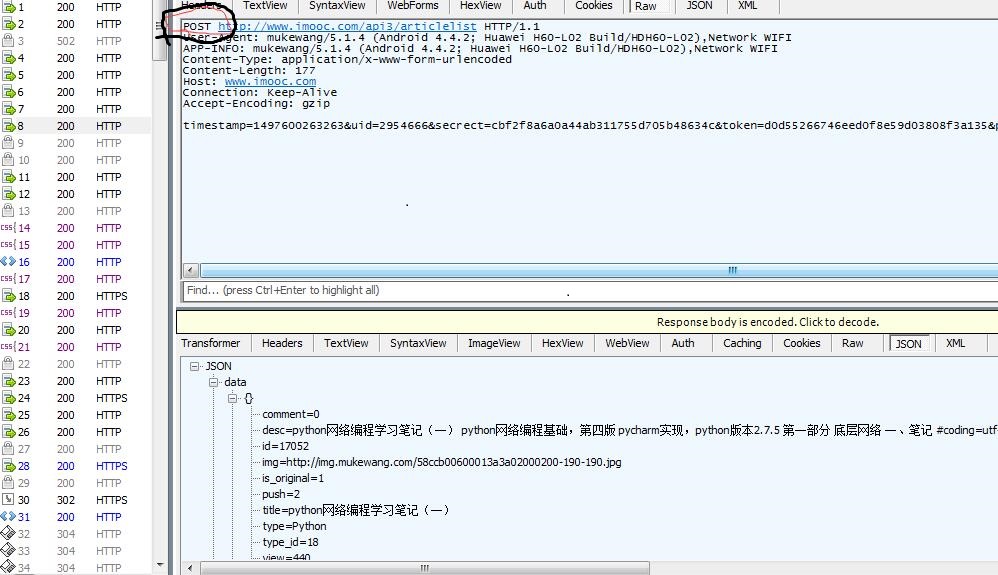
经过分析只有画线的page在变化

上代码:
items.py
import scrapy class ImoocItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#id
id=scrapy.Field()
#标题
title=scrapy.Field()
#类别
tag=scrapy.Field()
#内容
content=scrapy.Field()
#爬取时间
crawl_time=scrapy.Field()
spiders/IMooc.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import json
from imooc.items import ImoocItem
from datetime import datetime from scrapy.http import FormRequest
class ImoocSpider(scrapy.Spider):
name = 'IMooc'
allowed_domains = ['www.imooc.com']
headers={
"User - Agent":"mukewang/5.1.4 (Android 4.4.2; Huawei H60-L02 Build/HDH60-L02),Network WIFI",
"APP-INFO":"mukewang/5.1.4 (Android 4.4.2; Huawei H60-L02 Build/HDH60-L02),Network WIFI",
"Host":"www.imooc.com",
"Connection":"Keep-Alive",
"Content-Type":"application/x-www-form-urlencoded"
}
def start_requests(self):
url="http://www.imooc.com/api3/articlelist"
requests = []
for i in range(1,60):
formdata={
"typeid":"",
"page":str(i),
}
request = FormRequest(url, callback=self.parse_item, formdata=formdata,headers=self.headers)
requests.append(request)
return requests
def parse_item(self, response):
datas=json.loads(response.text)["data"]
for data in datas:
item=ImoocItem()
item["id"]=data["id"]
item["title"]=data["title"]
item["tag"]=data["type"]
item["content"]=data["desc"]
item["crawl_time"]=datetime.now()
yield item
pipelines.py
import pymysql
class ImoocPipeline(object):
def process_item(self, item, spider):
con = pymysql.connect(host="127.0.0.1", user="youusername", passwd="youpassword", db="imooc", charset="utf8")
cur = con.cursor()
sql = ("insert into imooc_shouji(id,title,tag,content,crawl_time)"
"VALUES(%s,%s,%s,%s,%s)")
lis = (item["id"],item["title"],item["tag"],item["content"],item["crawl_time"])
cur.execute(sql, lis)
con.commit()
cur.close()
con.close()
return item
settings.py
BOT_NAME = 'imooc' SPIDER_MODULES = ['imooc.spiders']
NEWSPIDER_MODULE = 'imooc.spiders'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 5
ITEM_PIPELINES = {
'imooc.pipelines.ImoocPipeline': 300,
}
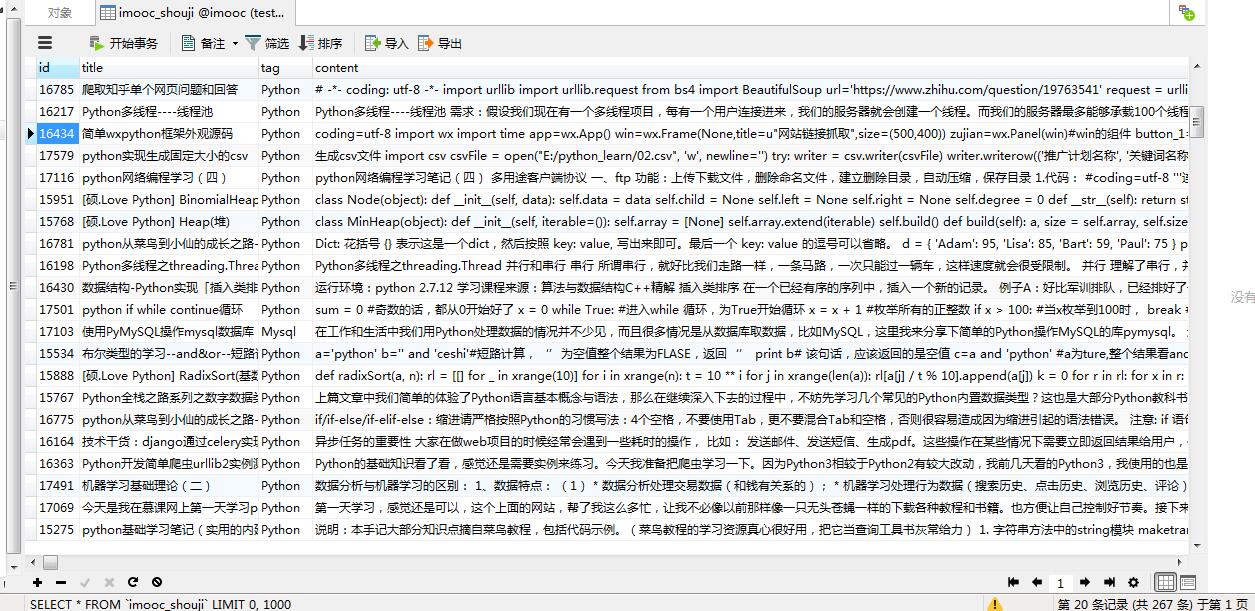
只爬取python相关的手记如下图:
scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):的更多相关文章
- scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):
一般来说爬虫类框架抓取Ajax动态页面都是通过一些第三方的webkit库去手动执行html页面中的js代码, 最后将生产的html代码交给spider分析.本篇文章则是通过利用fiddler抓包获取j ...
- C#利用phantomJS抓取AjAX动态页面
在C#中,一般常用的请求方式,就是利用HttpWebRequest创建请求,返回报文.但是有时候遇到到动态加载的页面,却只能抓取部分内容,无法抓取到动态加载的内容. 如果遇到这种的话,推荐使用phan ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 十三 web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息, ...
- C#抓取AJAX页面的内容
原文 C#抓取AJAX页面的内容 现在的网页有相当一部分是采用了AJAX技术,所谓的AJAX技术简单一点讲就是事件驱动吧(当然这种说法可能很不全面),在你提交了URL后,服务器发给你的并不是所有是页面 ...
- 如何让搜索引擎抓取AJAX内容? 转
越来越多的网站,开始采用"单页面结构"(Single-page application). 整个网站只有一张网页,采用 Ajax 技术,根据用户的输入,加载不同的内容. 这种做法的 ...
- 如何让搜索引擎抓取AJAX内容?
越来越多的网站,开始采用"单页面结构"(Single-page application). 整个网站只有一张网页,采用Ajax技术,根据用户的输入,加载不同的内容. 这种做法的好处 ...
- scrapy下载中间件结合selenium抓取全国空气质量检测数据
1.所需知识补充 1.下载中间件常用函数 process_request(self, request, spider): 当每个request通过下载中间件是,该方法被调用 process_reque ...
随机推荐
- 2-17-MySQL读写分离-mysql-proxy
实验环境: mysql-proxy服务端: xuegod1 IP:192.168.10.31 mysql服务器(主,负责写)服务端:xuegod2 ...
- C#彩色艺术化二维码样式设计(仅说思路)
原文:C#彩色艺术化二维码样式设计(仅说思路) 仅讲思路,想要源码的请绕道. 一.样式 1.先看各种二维码的样式吧: (1)最简单的样式--黑白样式,如下图: 图1 最平常见到的二维码样式(如果 ...
- Windows程序设计画图实现哆啦A梦
在看雪论坛上看到的一个帖子,很喜欢,转载一下.原文地址:http://bbs.pediy.com/showthread.php?t=138630哆啦A梦是画出来的,不知道作者算这些坐标位置算了多久,真 ...
- C# XML 去xmlns:xsd和xmlns:xsi属性
public static XElement WithoutNamespaces(this XElement element) { if (element == null) return null; ...
- HTML5离线缓存攻击测试(二)
经过昨天的测试,发现使用离线缓存的网站会被攻击.但是,不使用离线缓存的网站就真的不会受到这样的攻击么? 据我理解,按照标准当浏览器请求manifest文件时,若没有请求到,或者文件发生改变,应当不使用 ...
- 同城快递公司Postmates近日完成1亿美元融资,美国外卖餐饮迎来一波融资热潮
美国外卖市场尚未出现一家独大的巨头,一部分原因是与中国的外卖平台相比,在美国,外卖平台要克服的难题可能更多. 4个月之前才完成3亿美元融资的美国同城快递公司Postmates近日又完成1亿美元融资,估 ...
- 匹配中文字符的正则表达式: [/u4e00-/u9fa5]
原文:匹配中文字符的正则表达式: [/u4e00-/u9fa5] 这里是几个主要非英文语系字符范围(google上找到的): 2E80-33FFh:中日韩符号区.收容康熙字典部首.中日韩辅助部首.注音 ...
- ARTS 12.24 - 12.28
从陈皓博主的专栏里学到一个概念,争取可以坚持下去: 每周一个 Algorithm,Review 一篇英文文章,总结一个工作中的技术 Tip,以及 Share 一个传递价值观的东西! 一个 Algori ...
- Go语言v1.8正式发布,有显著的性能提升和变化(go适合服务器编程、网络编程)
前言 Go语言现在在服务端的网络编程领域越来越火,尤其像IM即时通讯应用这种富网络应用且对服务端网络性能要求极高的场景,很高兴看到Golang发布了1.8正式版,希望在多核架构横行的时代多一些这种顺应 ...
- 解决C/C++程序执行一闪而过的方法(使用getchar,或者cin.get,不推荐system(“pause”))
简述 在VS编写控制台程序的时候,包括使用其他IDE(Visual C++)编写C/C++程序,经常会看到程序的执行结果一闪而过,要解决这个问题,可以在代码的最后加上system(“pause”).g ...