【Azure Developer】使用 Python SDK连接Azure Storage Account, 计算Blob大小代码示例
问题描述
在微软云环境中,使用python SDK连接存储账号(Storage Account)需要计算Blob大小?虽然Azure提供了一个专用工具Azure Storage Explorer可以统计出Blob的大小:
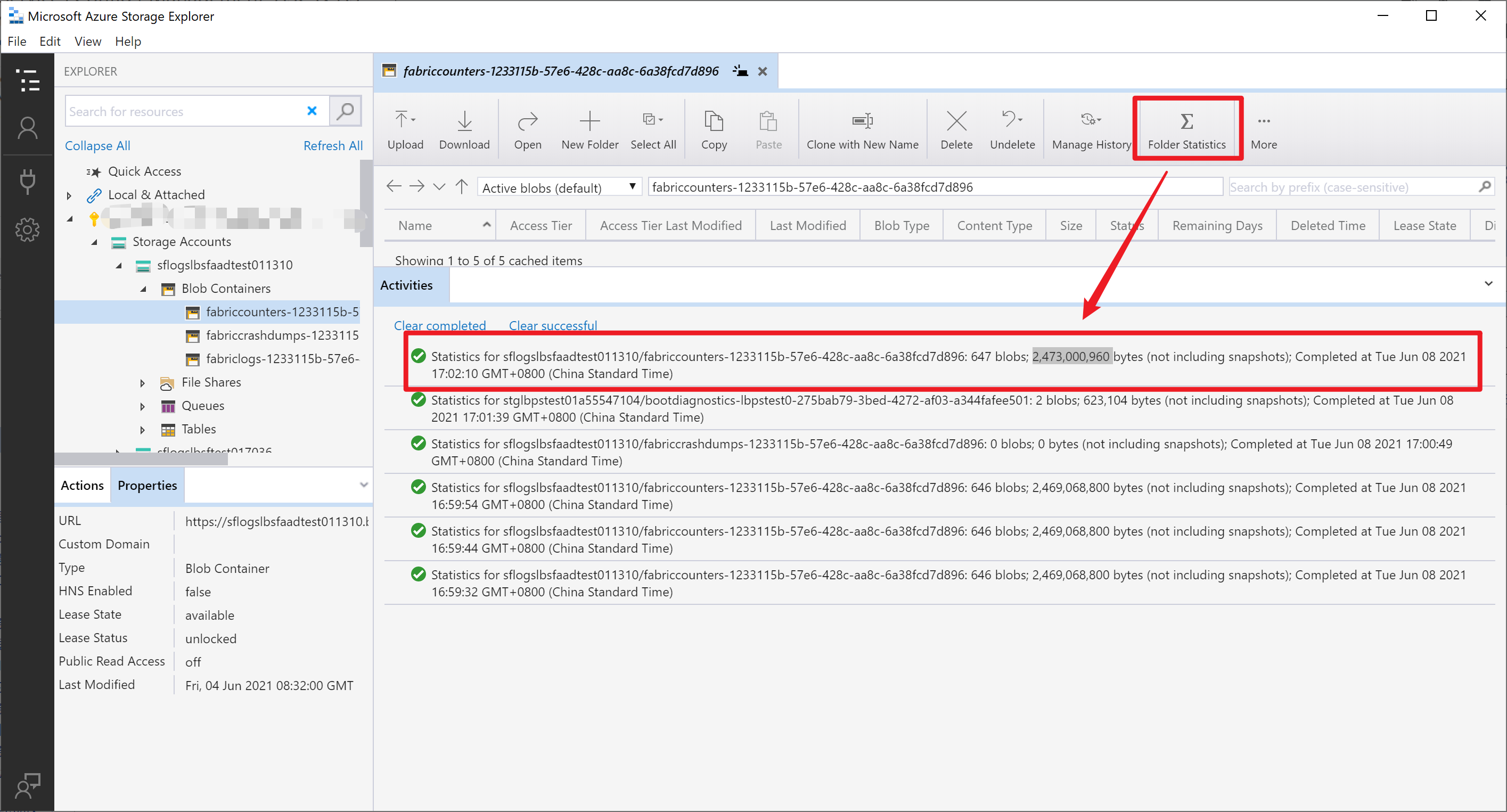
但是它也是只能一个Blob Container一个的统计,如果Container数量巨大,这将是一个繁琐的工作。而作为开发者,应该让代码来帮助完成。下文使用最快上手的Python代码来计算Blob中容量的大小。
完整代码
import os, uuid, datetime, threading
import logging
from azure.storage.blob import BlobServiceClient, BlobClient, ContainerClient, __version__ def calculateBlob(connect_string, count):
try:
blob_service_client = BlobServiceClient.from_connection_string(connect_string)
except Exception as e:
messages = str(count) + "Connect_String Error, Messages:" + e.args.__str__()
print(messages)
logging.info(messages)
else:
all_containers = blob_service_client.list_containers()
for c in all_containers:
count_name = c.name
print(count_name)
if count_name not in blobSize_Total:
blobSize_Total[count_name] = 0
if count_name not in blobSize_Daily:
blobSize_Daily[count_name] = 0
container_client = blob_service_client.get_container_client(count_name)
generator = container_client.list_blobs() total_size_container = 0
daily_size_container = 0 for blob in generator:
total_size_container += blob.size
blob_create_time = blob.creation_time.strftime("%Y%m%d")
if blob_create_time != now_date:
continue
else:
# Calculate BlobSize in this month
daily_size_container += blob.size
# blobSize_Daily[count_name] += blob.size # /(1024*1024) # content_length - bytes blobSize_Total[count_name] += total_size_container / (1024 * 1024)
blobSize_Daily[count_name] += daily_size_container / (1024 * 1024) return None if __name__ == '__main__':
# connect string
Connection_String_List ="DefaultEndpointsProtocol=https;AccountName=<storagename>;AccountKey=<key>;EndpointSuffix=core.chinacloudapi.cn"
# for i in Connection_String:
start = datetime.datetime.now()
print(start) # 定义全局变量 - blobSize_Daily & blobSize_Total
blobSize_Daily = {}
blobSize_Total = {} now_date = datetime.datetime.now().strftime("%Y%m%d") print("开始计算")
calculateBlob(Connection_String_List, 1)
print("计算完成") print("统计当前新增大小")
print(blobSize_Daily)
print("统计Blob总大小")
print(blobSize_Total)
end = datetime.datetime.now()
print(end)
如运行是没有Azure blob模块,可以使用 pip install azure-storage-blob 安装。以上代码运行结果如下:

如果有多个Storage Account,可以考虑加入多线程的方式来运行,在代码中增加一个myThread类,然后在 __main__ 中把 calculateBlob(Connection_String_List, 1) 运行替换为 many_thread(Connection_String_List) 即可。
class myThread(threading.Thread):
def __init__(self, threadID, name, connection_string):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.connection_string = connection_string
def run(self):
print("开始线程:" + self.name)
calculateBlob(self.connection_string, self.threadID)
print("退出线程:" + self.name)
def many_thread(Connection_String_List):
threads = []
for i in range(len(Connection_String_List)): # 循环创建32个线程
t = myThread(i, "Thread-" + str(i), Connection_String_List[i])
threads.append(t)
for t in threads: # 循环启动32个线程 - 对应64个storage account
t.start()
for t in threads:
t.join()
遇见问题
在多线程执行时,可能会遇见问题:("Connection broken: ConnectionResetError(10054, 'An existing connection was forcibly closed by the remote host', None, 10054, None)", ConnectionResetError(10054, 'An existing connection was forcibly closed by the remote host', None, 10054, None)),出现此问题大都是由于客户端使用了已经断开的连接导致所导致的。所以一定要仔细调试多线程关闭代码。是否是把还需要运行的线程给关闭了。导致了以上的错误消息。
附录一:多线程计算Blob的完整代码
import os, uuid, datetime, threading
import logging
from azure.storage.blob import BlobServiceClient, BlobClient, ContainerClient, __version__ def calculateBlob(connect_string, count):
try:
blob_service_client = BlobServiceClient.from_connection_string(connect_string)
except Exception as e:
messages = str(count) + "Connect_String Error, Messages:" + e.args.__str__()
print(messages)
logging.info(messages)
else:
all_containers = blob_service_client.list_containers()
for c in all_containers:
count_name = c.name
print(count_name)
if count_name not in blobSize_Total:
blobSize_Total[count_name] = 0
if count_name not in blobSize_Daily:
blobSize_Daily[count_name] = 0
container_client = blob_service_client.get_container_client(count_name)
generator = container_client.list_blobs() total_size_container = 0
daily_size_container = 0 for blob in generator:
total_size_container += blob.size
blob_create_time = blob.creation_time.strftime("%Y%m%d")
if blob_create_time != now_date:
continue
else:
# Calculate BlobSize in this month
daily_size_container += blob.size
# blobSize_Daily[count_name] += blob.size # /(1024*1024) # content_length - bytes blobSize_Total[count_name] += total_size_container / (1024 * 1024)
blobSize_Daily[count_name] += daily_size_container / (1024 * 1024) return None class myThread(threading.Thread): def __init__(self, threadID, name, connection_string):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.connection_string = connection_string def run(self):
print("开始线程:" + self.name)
calculateBlob(self.connection_string, self.threadID)
print("退出线程:" + self.name) def many_thread(Connection_String_List):
threads = []
for i in range(len(Connection_String_List)): # 循环创建32个线程
t = myThread(i, "Thread-" + str(i), Connection_String_List[i])
threads.append(t)
for t in threads: # 循环启动32个线程 - 对应64个storage account
t.start()
for t in threads:
t.join() if __name__ == '__main__':
# connect string
Connection_String_List = ['DefaultEndpointsProtocol=https;AccountName=<your storage account 1>;AccountKey=<Key 1>;EndpointSuffix=core.chinacloudapi.cn', 'DefaultEndpointsProtocol=https;AccountName=<your storage account 2>;AccountKey=<Key 2>;EndpointSuffix=core.chinacloudapi.cn']
# for i in Connection_String:
start = datetime.datetime.now()
print(start) # 定义全局变量 - blobSize_Daily & blobSize_Total
blobSize_Daily = {}
blobSize_Total = {} now_date = datetime.datetime.now().strftime("%Y%m%d") many_thread(Connection_String_List)
print("Main Thread End") print(blobSize_Daily)
print(blobSize_Total)
end = datetime.datetime.now()
print(end)
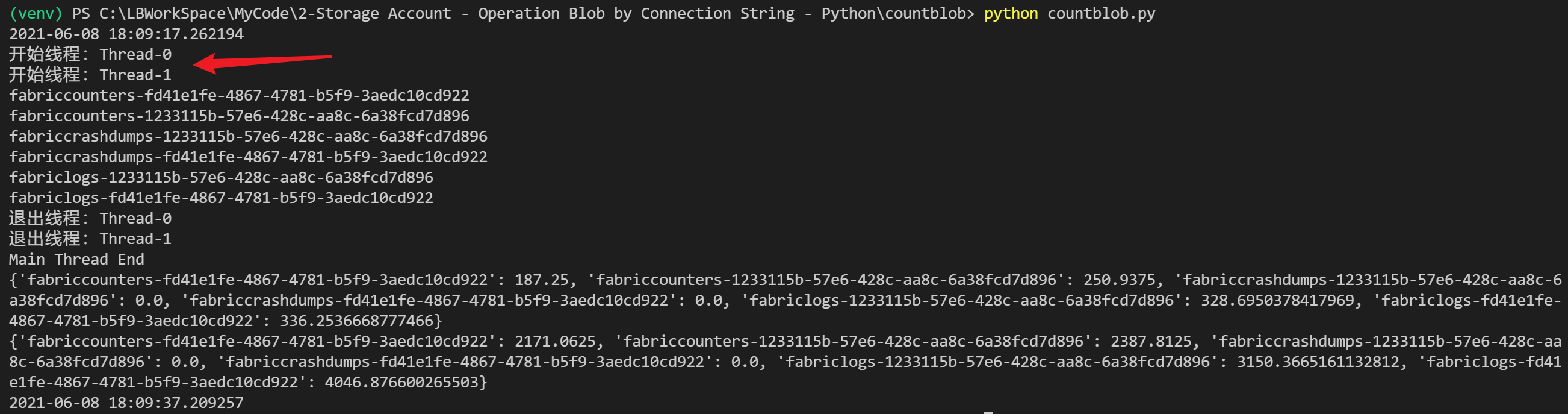
运行效果:
参考资料
快速入门:使用 Python v12 SDK 管理 blob :https://docs.azure.cn/zh-cn/storage/blobs/storage-quickstart-blobs-python
Python 列表(List) : https://www.runoob.com/python/python-lists.html
BlobServiceClient Class : https://docs.microsoft.com/en-us/python/api/azure-storage-blob/azure.storage.blob.blobserviceclient?view=azure-python
【Azure Developer】使用 Python SDK连接Azure Storage Account, 计算Blob大小代码示例的更多相关文章
- 使用Python SDK管理Azure Load Balancer
概述 下面将演示如何使用Python SDK管理中国区Azure Load balancer.关于Azure负载均衡器的详细功能介绍,请参考官方文档. Code Sample import os fr ...
- 【Azure Developer】Python 获取Micrisoft Graph API资源的Access Token, 并调用Microsoft Graph API servicePrincipals接口获取应用ID
问题描述 在Azure开发中,我们时常面临获取Authorization问题,需要使用代码获取到Access Token后,在调用对应的API,如servicePrincipals接口. 如果是直接调 ...
- 【Azure Developer】Python代码通过AAD认证访问微软Azure密钥保管库(Azure Key Vault)中机密信息(Secret)
关键字说明 什么是 Azure Active Directory?Azure Active Directory(Azure AD, AAD) 是 Microsoft 的基于云的标识和访问管理服务,可帮 ...
- 【Azure Developer】调用SDK的runPowerShellScript方法,在Azure VM中执行PowerShell脚本示例
当需要通过代码的方式执行PowerShell脚本时,可以参考以下的示例. Azure SDK中提供了两个方法来执行PowerShell脚本 (SDK Source Code: https://gith ...
- 【Azure Developer】使用Postman获取Azure AD中注册应用程序的授权Token,及为Azure REST API设置Authorization
Azure Active Directory (Azure AD) is Microsoft's cloud-based identity and access management service, ...
- 【Azure Developer】解决Azure Key Vault管理Storage的示例代码在中国区Azure遇见的各种认证/授权问题 - C# Example Code
问题描述 使用Azure密钥保管库(Key Vault)来托管存储账号(Storage Account)密钥的示例中,从Github中下载的示例代码在中国区Azure运行时候会遇见各种认证和授权问题, ...
- 【Azure Developer】【Python 】使用 azure.identity 和 azure.common.credentials 获取Azure AD的Access Token的两种方式
问题描述 使用Python代码,展示如何从Azure AD 中获取目标资源的 Access Token. 如要了解如何从AAD中获取 client id,client secret,tenant id ...
- 【Azure Developer】使用Microsoft Graph API 批量创建用户,先后遇见的三个错误及解决办法
问题描述 在先前的一篇博文中,介绍了如何使用Microsoft Graph API来创建Azure AD用户(博文参考:[Azure Developer]使用Microsoft Graph API 如 ...
- 【Azure 应用服务】Azure Function集成虚拟网络,设置被同在虚拟网络中的Storage Account触发,遇见Function无法触发的问题
一切为了安全,所有的云上资源如支持内网资源访问,则都可以加入虚拟网络 问题描述 使用Azure Function处理Storage Account中Blob 新增,更新,删除等情况.Storage A ...
随机推荐
- 功能:Java注解的介绍和反射使用
功能:Java注解的介绍和反射使用 一.注解 1.注解介绍 java注解(Annotation),又称为java标注,是jdk5.0引入的一种机制. Java 语言中的类.方法.变量.参数和包等都可以 ...
- 针对缓冲区保护技术(ASLR)的一次初探
0x01 前言 ASLR 是一种针对缓冲区溢出的安全保护技术,通过对堆.栈.共享库映射等线性区布局的随机化,通过增加攻击者预测目的地址的难度,防止攻击者直接定位攻击代码位置,达到阻止溢出攻击的目的的一 ...
- Windows Pe 第三章 PE头文件-EX-相关编程-1(PE头内容获取)
获取pE头相关的内容,就是类似如下内容 原理:比较简单,直接读取PE到内存,然后直接强转就行了. #include <windows.h> #include <stdio.h> ...
- Insert Pictures In Hexo Blog
After build my blog following the online course step by step , I began to try to write my own blog️ ...
- LINQ之查询语法
新开一节LINQ的入门讲解. LINQ(Language Integrated Query)语言集成查询,是C#语言的扩展,它的主要功能是从数据集中查询数据,就像通过sql语句从数据库查询数据一样(本 ...
- IP子网划分与聚合
一:IP地址: IP地址是由32位2进制数组成,每8位一组.由点分十进制表达. IP地址可以分为五类 A类(1.0.0.0-126.255.255.255),127.0.0.1 为本地回环地址. B类 ...
- UVa OJ 455 Periodic Strings
Periodic Strings A character string is said to have period k if it can be formed by concatenating ...
- BUAA软件工程_软件案例分析
写在前面 项目 内容 所属课程 2020春季计算机学院软件工程(罗杰 任健) (北航) 作业要求 软件案例分析 课程目标 培养软件开发能力 本作业对实现目标的具体作用 对案例进行分析以学习软件开发的经 ...
- 排坑·IPhone&IOS中不兼容正则中的断言匹配
阅文时长 | 1.14分钟 字数统计 | 1834.4字符 主要内容 | 1.问题切入 2.什么是断言匹配 3.断言匹配的替换方案 4.声明与参考资料 『排坑·IPhone&IOS中不兼容正则 ...
- COS 数据湖最佳实践:基于 Serverless 架构的入湖方案
01 前言 数据湖(Data Lake)概念自2011年被推出后,其概念定位.架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括 ETL 分析.数据转换及数据处理的下 ...