大数据-Hadoop 伪分布模式
1. 分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
2. 执行步骤
(1)配置集群
(a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
[atguigu@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
修改JAVA_HOME 路径:
在Hadoop的目录下,vim Hadoop-env.sh

export JAVA_HOME=/opt/module/jdk1.8.0_144

(b)配置:core-site.xml

<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
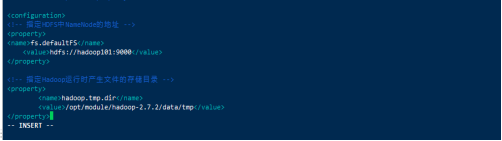
c)配置:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(2)启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
(b)启动NameNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode

(c)启动DataNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode

(3)查看集群
(a)查看是否启动成功
[atguigu@hadoop101 hadoop-2.7.2]$ jps
13586 NameNode
13668 DataNode
13786 Jps
大数据-Hadoop 伪分布模式的更多相关文章
- [大数据] hadoop伪分布式安装
注意:节点主机的hostname不要带"_"等字符,否则会报错. 一.安装jdk rpm -i jdk-7u80-linux-x64.rpm 配置java环境变量: vi + /e ...
- hadoop伪分布模式的配置和一些常用命令
大数据的发展历史 3V:volume.velocity.variety(结构化和非结构化数据).value(价值密度低) 大数据带来的技术挑战 存储容量不断增加 获取有价值的信息的难度:搜索.广告.推 ...
- Hadoop伪分布模式配置
本作品由Man_华创作,采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可.基于http://www.cnblogs.com/manhua/上的作品创作. 请先按照上一篇文章H ...
- 【原】Hadoop伪分布模式的安装
Hadoop伪分布模式的安装 [环境参数] (1)Host OS:Win7 64bit (2)IDE:Eclipse Version: Luna Service Release 2 (4.4.2) ( ...
- Linux环境搭建Hadoop伪分布模式
Hadoop有三种分布模式:单机模式.伪分布.全分布模式,相比于其他两种,伪分布是最适合初学者开发学习使用的,可以了解Hadoop的运行原理,是最好的选择.接下来,就开始部署环境. 首先要安装好Lin ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- hadoop伪分布模式安装
软件环境 操作系统 : OracleLinux-R6-U6 主机名: hadoop java: jdk1.7.0_75 hadoop: hadoop-2.4.1 环境搭建 1.软件安装 由于所需的软 ...
- Hadoop 伪分布模式安装
( 温馨提示:图片中有id有姓名,不要盗用哦,可参考流程,有问题评论区留言哦 ) 一.任务目标 1.了解Hadoop的3种运行模式 2.熟练掌握Hadoop伪分布模式安装流程 3.培养独立完成Hado ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
随机推荐
- 使用Apache Pulsar + Hudi构建Lakehouse方案了解下?
1. 动机 Lakehouse最早由Databricks公司提出,其可作为低成本.直接访问云存储并提供传统DBMS管系统性能和ACID事务.版本.审计.索引.缓存.查询优化的数据管理系统,Lakeho ...
- Spring的基础配置,以及注解
常用依赖 <dependencies> <!-- https://mvnrepository.com/artifact/org.springframework/spring-webm ...
- rabbit_消费者
import pika import json import time import os import ast import uuid import time import json import ...
- Docker学习(3) 容器基本操作
容器的基本操作
- Docker学习(1) 初识
Docker的使用场景 1 使用Docker容器开发,测试,部署服务 2 创建隔离的运行环境 3 搭建测试环境 4 构建多用户的平台及服务(PaaS)基础设施 5 提供软件即服务(SaaS)应用程序 ...
- java中的Class.forName的作用
Class.forName有什么作用 Class.forName(xxx.xx.xx) 返回的是一个类 首先你要明白在java里面任何class都要装载在虚拟机上才能运行.这句话就是装载类用的(和ne ...
- 工作流Activiti框架中的LDAP组件使用详解!实现对工作流目录信息的分布式访问及访问控制
Activiti集成LDAP简介 企业在LDAP系统中保存了用户和群组信息,Activiti提供了一种解决方案,通过简单的配置就可以让activit连接LDAP 用法 要想在项目中集成LDAP,需要在 ...
- 面试官:给我讲讲SpringBoot的依赖管理和自动配置?
1.前言 从Spring转到SpringBoot的xdm应该都有这个感受,以前整合Spring + MyBatis + SpringMVC我们需要写一大堆的配置文件,堪称配置文件地狱,我们还要在pom ...
- 【题解】入阵曲 luogu3941 前缀和 压维
丹青千秋酿,一醉解愁肠. 无悔少年枉,只愿壮志狂 题目 题目描述 小 F 很喜欢数学,但是到了高中以后数学总是考不好. 有一天,他在数学课上发起了呆:他想起了过去的一年.一年前,当他初识算法竞赛的 时 ...
- ES6中的Generator函数
今天小编发现一个es6中的新概念,同时也接触到了一个新关键字yeild,下面我就简单和大家聊聊es6中的generator函数.大家还可以关注我的微信公众号,蜗牛全栈. 一.函数声明:在functio ...