KNN-笔记(2)
1 - kd Tree
KD树是一种对K维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。KD树其实就是二叉树,表现为对K维空间的一个划分,构造kd树相当于不断的用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域,即kd树就是二叉树在高维上的扩展。kd树的每个节点最后对应于一个k维超矩形区域。kd树搜索的平均计算复杂度是\(O(logN)\)。假如维度是k, 而样本点一共N个,那么最好是\(N >> 2^k\)。否则kd树基于维度需要回溯比较的次数基本等同于线性一个个比较的次数。所以这时候通常会使用如sift中的近似最近邻方法(best-bin-first search),也就是不需要找到最匹配的那些样本点,而是放弃一定的精度来加快速度。
在看别人博客的时候,发现对KD树有2种不同理解,一种如统计学习方法中说的,树中内部节点也是样本点,如这里;而另一种,树内部的节点是划分点,样本点全都在叶子节点上,如这里。
1.1 - 构造过程
这里先介绍内部节点是样本点的构造过程:
构造过程;假设训练集一共\(n\)个样本点,每个样本点特征维度都是\(k\)。
1)构造根节点:先计算所有样本第1维组成的向量的中位数。然后将该中位数表示的样本作为根节点\(r_0\);将该维度上小于中位数的样本点划分到左子树\(RL\);大于该中位数的样本点划分到右子树\(RR\);
2)构造后续节点:对于步骤1)划分到左子树的所有样本点,按照它们第2维度找中位数,并将中位数对应的样本作为该子树的根节点\(r_{1l}\),将小于该中位数的样本点划分到该子树对应的左子树,大于的划分到该子树对应的右子树;
通过不断的找中位数表示的样本,不断的对k维空间进行分割,直到两边子树只剩下一个样本作为叶子节点。这样的kd树是平衡的,不过却不一定是最优的。
ps:(1)当划分层数太深,而维度不够用时,从头开始,即从第1维接着开始; (2)树的每个节点都对应一个样本。
拿《统计学习方法》例3.2来说,假设训练集样本有{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}
第0层根节点,找第1维中位数对应样本点:[2,4,5,7,8,9],中位数从[5,7]中挑中7,得当前根节点为(7,2),分得左子树{(2,3),(4,7),(5,4)};右子树{(8,1),(9,6)}
第1层根节点,找第2维中位数对应样本点:左子树:[3,4,7]-4;右子树[1,6]-6。分得第1层
左子树{(2,3)}【(5,4)】{(4,7)};右子树{(8,1)}【(9,6)】
第2层,因为第一层分割后只剩下每个根节点对应的左右子树都只有一个样本,作为叶子节点,所以无需再分,结果如下图:
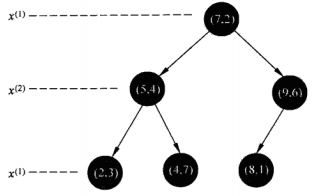
图1.1 二维情况下的kd树构造例子
ps:这样虽然得到的树是平衡的,不过觉得不利于搜索。而如这里:在轴的选取上采用方差最大的那个轴作为当前轴是个较好的方法,不过这有一点就是,在当前轴划分之后,不同空间中的样本点的最大方差轴可能会变。所以就需要每一次划分都去重新计算每个轴的方差,并选取最大轴,然后选取中位数,可见比轴轮询的方式多了一步,更耗时了,有利有弊。
1.1.1 - 3维空间中的kd树
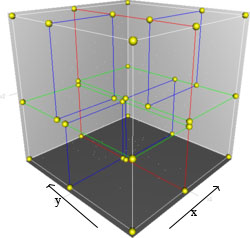
图1.2 三维情况下的kd-树空间划分。首先是x轴的红色超平面将3维空间划分成2个子空间,然后每个子空间中,基于z轴的绿色超平面接着各自划分成2个子空间.这时候有四个子空间了,最后基于y轴的蓝色超平面将每个空间划分成2个子空间。该图是基于坐标轴的轮询,且不重复划分,所以多少个坐标轴,就划分几次,这时候一共8个子空间.
如上图所示,kd树就是基于二叉树的多维空间划分。
1.2 - 搜索过程
这里以所有样本点为叶子节点做说明,叶子节点不参与中间的空间划分 (因懒于画图,直接找到了别人的图[3])
步骤:
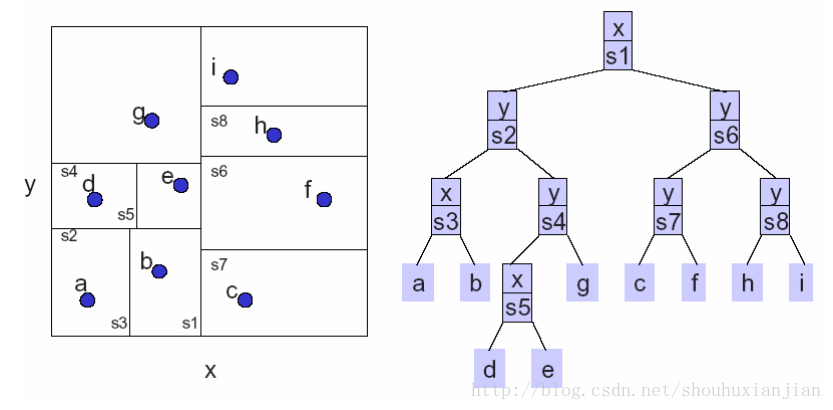
图2.1 2维情况下kd树构造
如上图所示,是一个基于2维情况下构造好的kd树,其中较为清楚的说明了每一次划分时候选取的轴,可以看出这里采用的是方差最大的形式。
2.1 - 先找到最底层叶子节点
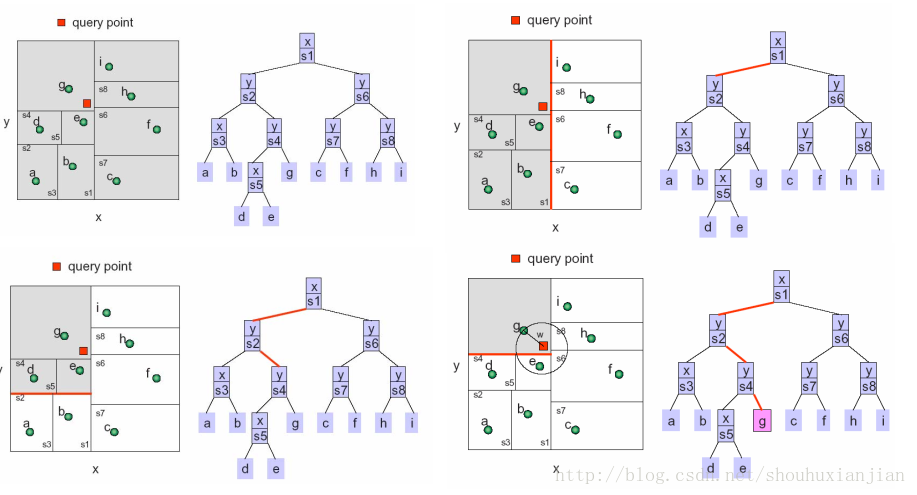
图2.2 给定一个询问点,找到最底层叶子节点g
上图中,首先一直找到底,找到与其最接近的叶子节点g,并计算2点之间的距离(保持平方,不开根可以节省运算),将当前距离作为最近距离R(表示以询问点为圆心,R为圆的半径平方)。
2.2 - 往上回溯
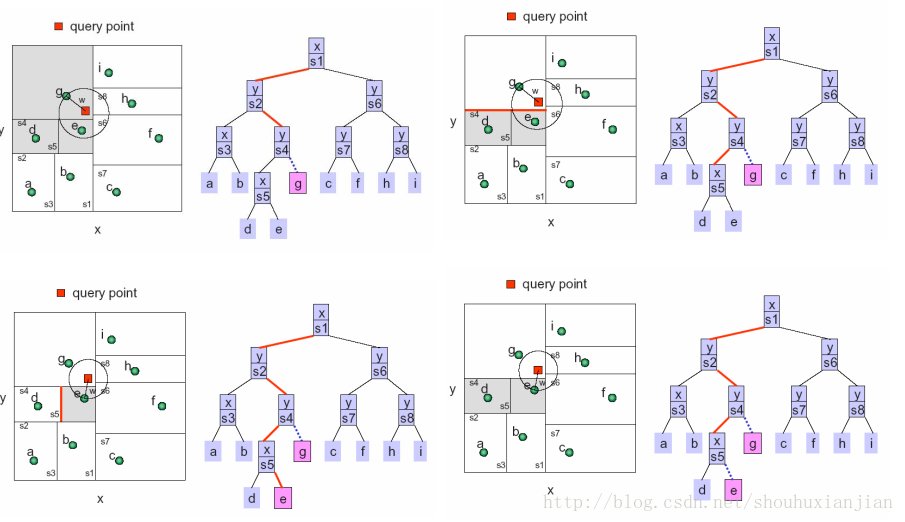
图2.3 往上回溯
虚线表示往上回溯的步骤:
i)首先在得到g点基础上,计算询问点(红色方块)与上一层即(y|s4)表示的超平面(二维上是线)之间的距离,看该点与该超平面的距离是否小于R,以此作为是否需要到,g点的父节点,的另一边子树搜索。因为小于R,所以需要过去搜索。
ii)以(y|s4)为根节点,找左边与询问方块最接近的叶子节点e,并计算当前的最近距离,因为与e的距离小于与g的距离,最近距离R被更新;
iii)如i)一样进行往上回溯。
总结:所以在节点查找的过程,就是找到叶子节点,进行比对,然后往上回溯其父节点表示的超平面是否相交,然后将另一边子树作为新的查找kd树对待。
这里需要插入关于在与内部节点(超平面)比较的解释:
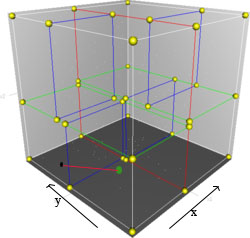
图2.4 3维情况下解释
如上图所示,假设黑点是询问点,而绿点是y轴负方向那边子空间中的一点,以黑点为球心,画一个r半径的圆。我们想要知道是否需要去,以蓝色为分割超平面,的另一边去寻找(即绿点)?在点之间计算距离是每个维度都需要计算的,而与超平面计算距离的时候,只需要计算该分割轴即可。通俗点说,就是黑点与绿点的距离是完整的距离计算,而黑点,与黑点绿点之间的蓝色超平面,的距离只需要计算y轴上差值(记得平方)即可。
完整的过程如下面几幅图:
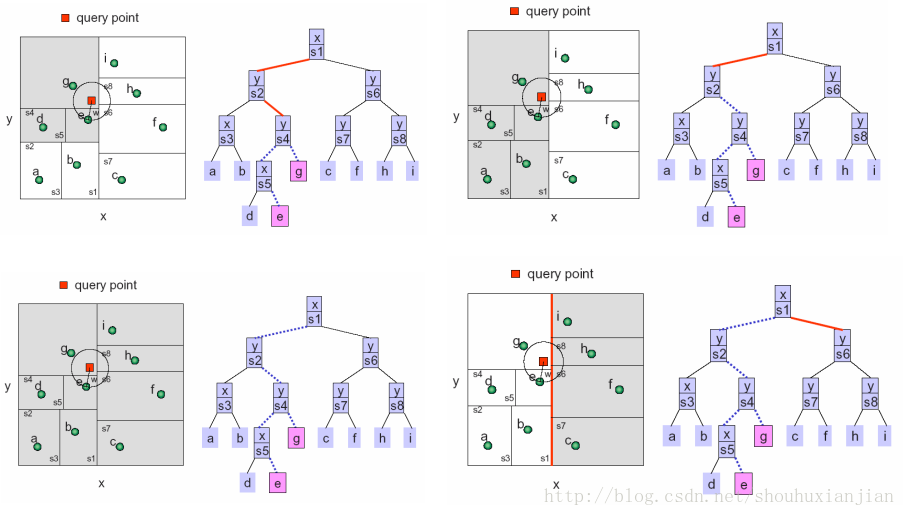
图2.5
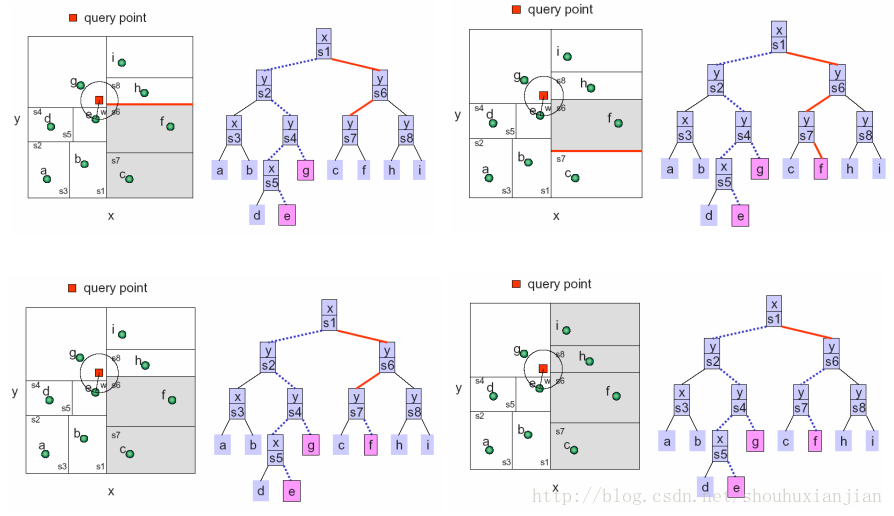
图2.6
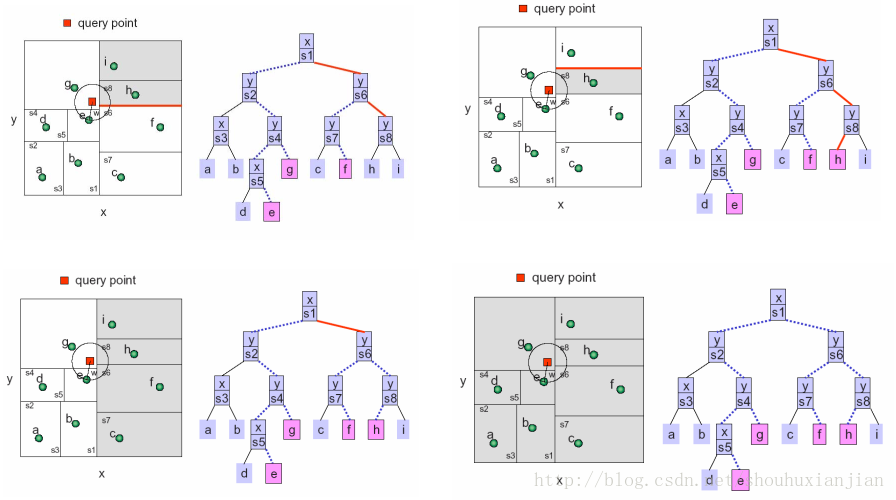
图2.7
2 - Ball Tree
参考资料:
[1] wiki,https://en.wikipedia.org/wiki/K-d_tree
[2] Beis, J.; Lowe, D. G. (1997). Shape indexing using approximate nearest-neighbour search in high-dimensional spaces. Conference on Computer Vision and Pattern Recognition. Puerto Rico. pp. 1000–1006
[3]Thinh Nguyen, Oregon State University. Lecture 13+: Nearest Neighbor Search (网页打不开可迅雷下载)
KNN-笔记(2)的更多相关文章
- KNN笔记
KNN笔记 先简单加载一下sklearn里的数据集,然后再来讲KNN. import numpy as np import matplotlib as mpl import matplotlib.py ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 第2章KNN算法笔记_函数classify0
<机器学习实战>知识点笔记目录 K-近邻算法(KNN)思想: 1,计算未知样本与所有已知样本的距离 2,按照距离递增排序,选前K个样本(K<20) 3,针对K个样本统计各个分类的出现 ...
- opencv2.4.13+python2.7学习笔记--使用 knn对手写数字OCR
阅读对象:熟悉knn.了解opencv和python. 1.knn理论介绍:算法学习笔记:knn理论介绍 2. opencv中knn函数 路径:opencv\sources\modules\ml\in ...
- 机器学习笔记(5) KNN算法
这篇其实应该作为机器学习的第一篇笔记的,但是在刚开始学习的时候,我还没有用博客记录笔记的打算.所以也就想到哪写到哪了. 你在网上搜索机器学习系列文章的话,大部分都是以KNN(k nearest nei ...
- 学习笔记之k-nearest neighbors algorithm (k-NN)
k-nearest neighbors algorithm - Wikipedia https://en.wikipedia.org/wiki/K-nearest_neighbors_algorith ...
- 机器学习实战(Machine Learning in Action)学习笔记————02.k-邻近算法(KNN)
机器学习实战(Machine Learning in Action)学习笔记————02.k-邻近算法(KNN) 关键字:邻近算法(kNN: k Nearest Neighbors).python.源 ...
- kNN算法笔记
kNN算法笔记 标签(空格分隔): 机器学习 kNN是什么 kNN算法是k-NearestNeighbor算法,也就是k邻近算法.是监督学习的一种.所谓监督学习就是有训练数据,训练数据有label标好 ...
- retrival and clustering: week 2 knn & LSH 笔记
华盛顿大学 <机器学习> 笔记. knn k-nearest-neighbors : k近邻法 给定一个 数据集,对于查询的实例,在数据集中找到与这个实例最邻近的k个实例,然后再根据k个最 ...
- 【cs231n作业笔记】一:KNN分类器
安装anaconda,下载assignment作业代码 作业代码数据集等2018版基于python3.6 下载提取码4put 本课程内容参考: cs231n官方笔记地址 贺完结!CS231n官方笔记授 ...
随机推荐
- Cesium-知识点(Viewer)
Cesium之Viewer的构造(转自:https://blog.csdn.net/zhy905692718/article/details/78865107) Viewer属于Cesium的控件部分 ...
- onmouseover和onmouseenter区别
onmouseover和onmouseenter都是鼠标进入时触发,onmouseover在所选元素的子元素间切换的时候也触发! <!doctype html><html lang= ...
- DAY4(PYTHON)列表的嵌套,range,for
li=['a','b','开心','c'] print(li[2].replace ( ' 心 ', ' kaixin ' ) ) 输出:'a','b','开kaixin','c' li= ['abc ...
- (后端)SpringBoot中Mybatis打印sql(转)
原文地址:https://www.cnblogs.com/expiator/p/8664977.html 如果使用的是application.properties文件,加入如下配置: logging. ...
- 记CSS格式化上下文
fomatting context 引言 主要讲解的是BFC上下文 本文是查看 史上最全面.最透彻的BFC原理剖析 的笔记 所以不会详解BFC, 只是记录学习心得, 以及重要规则避免原文失效 简介 F ...
- Maven和Solr简单总结
一.1.Maven介绍 Maven是一个项目管理工具,Maven通过POM项目对象模型,对象项目进行管理,通过一个配置文件(xml文件)进行项目的管理.对象项目的声明周期中每个阶段进行管理(清理,编译 ...
- MySQL 如何查看表的存储引擎
MySQL 如何查看表的存储引擎 在MySQL中如何查看单个表的存储引擎? 如何查看整个数据库有那些表是某个特殊存储引擎,例如MyISAM存储引擎呢?下面简单的整理一下这方面的知识点. 如果要查看 ...
- ORA-01440: column to be modified must be empty to decrease precision or scale
在修改表字段的NUMBER类型的精度或刻度时,你可能会遇到ORA-01440: column to be modified must be empty to decrease precision or ...
- logstash配置
input { #You must define a [type], otherwise you cannot get a field to cut. tcp { port => 5045 ty ...
- Python - 判断list是否为空
Python中判断list是否为空有以下两种方式: 方式一: list_temp = [] if len(list_temp): # 存在值即为真 else: # list_temp是空的 方式二: ...