Event Recommendation Engine Challenge分步解析第二步
一、请知晓
本文是基于Event Recommendation Engine Challenge分步解析第一步,需要读者先阅读上篇文章解析
二、用户相似度计算
第二步:计算用户相似度信息
由于用到:users.csv,我们先看看其内容(看前10行)
import pandas as pd
df_users = pd.read_csv('users.csv')
df_users.head(10)
结果如下,有国家,有地区:
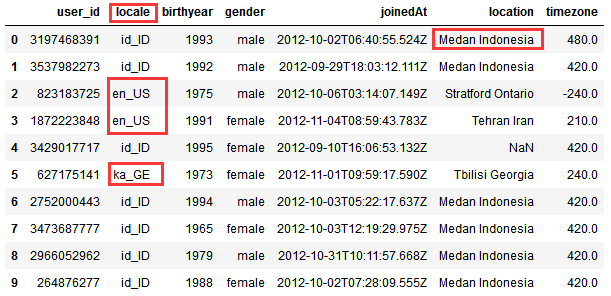
我们使用locale和pycountry模块来将字符串转换成数值:
locale.locale_alias字典
import locale
locale.locale_alias

下面我们来看看如何对users.csv的信息列进行处理,转换成数值型
1) locale列处理
import locale
from collections import defaultdict localeIdMap = defaultdict(int)
for i, l in enumerate(locale.locale_alias.keys()):
localeIdMap[l] = i + 1
for each in localeIdMap:
print(each, '\t', localeIdMap[each])
代码示例结果:
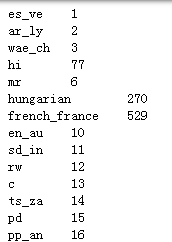
所以传给localeIdMap一个locale的字符串,就可以将其转换成数值型,如果传入的字符串不在localeIdMap的key中,则返回0,这也就体现了defaultdict(int)的作用
print(localeIdMap['en_GB'.lower()])
print(localeIdMap['en_US'.lower()])
print(localeIdMap['id_ID'.lower()])
print(localeIdMap['ka_GE'.lower()])
代码示例结果:
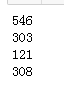
2)birthyear列处理
该列处理比较简单,存在就直接转换成数值,不存在就用0填充
def getBirthYearInt(birthYear):
try:
return 0 if birthYear=="None" else int(birthYear)
except:
return 0
print(getBirthYearInt(1992))
print(getBirthYearInt(None))
代码示例结果:
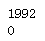
3)gender列处理:male转换为1, female转换为2,空值用0填充
from collections import defaultdict
genderIdMap = defaultdict(int, {'male':1, 'female':2})
print(genderIdMap['male'])
print(genderIdMap['female'])
print(genderIdMap[None])
代码示例结果:
4)joinedAt列处理
我们发现该列信息有些共性特点:
import pandas as pd
df_users = pd.read_csv('users.csv')
df_users['joinedAt']
代码示例结果:
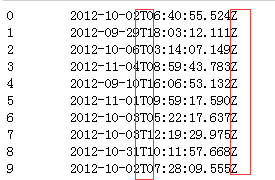
我们发现该列要么是None,要么是上面的时间字符串,均有T在中间和S在尾部,根据这个共性我们用datetime模块,提取时间信息:
import datetime
def getJoinedYearMonth(dateString):
try:
dttm = datetime.datetime.strptime(dateString, "%Y-%m-%dT%H:%M:%S.%fZ")
return "".join( [str(dttm.year), str(dttm.month)] )
except:
return 0
df_users['joinedAt'].map(getJoinedYearMonth)
代码示例结果(这里要注意dateString为None的情况,也就是说dateString必须符合后面的格式才行,所以这里加了try,但是except的返回值并不代表用0值填充合适)
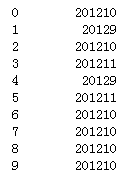
5)location列处理
我们来看看users.csv中location列信息(前20行):
df_users['location']
代码示例结果:

我们使用pycountry模块来将此列转换为数值型,pycountry.countries是个迭代器:
import pycountry
for i, c in enumerate(pycountry.countries):
print(i, c)
代码示例结果:

import pycountry
from collections import defaultdict
countryIdMap = defaultdict(int)
for i, c in enumerate(pycountry.countries):
countryIdMap[c.name.lower()] = i + 1
for each in countryIdMap:
print(each, '\t', countryIdMap[each])
代码示例结果:
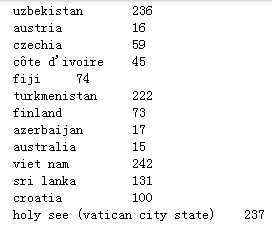
然后看看对location列是如何转换成数值型的:
import pycountry
from collections import defaultdict
countryIdMap = defaultdict(int)
for i, c in enumerate(pycountry.countries):
countryIdMap[c.name.lower()] = i + 1 def getCountryId(location):
if (isinstance( location, str)) and len(location.strip()) > 0 and location.rfind(' ') > -1:
return countryIdMap[ location[location.rindex(' ') + 2: ].lower() ]
else:
return 0
print(getCountryId('San Dimas California'))
print(getCountryId('Jogjakarta Indonesia'))
代码示例结果:
也就是location是字符串,不为空,并且从右边查询连续两个空格的索引大于-1,也就是存在两个连续空格,就获得两个空格后面的字符串,并转换为数值ID
6)timezone列处理:比较简单,存在值就转换为int型,不存在用0填充
def getTimezoneInt(timezone):
try:
return int(timezone)
except:
return 0
print(getTimezoneInt(-240))#-240
print(getTimezoneInt(240))
print(getTimezoneInt(None))
7)将上面处理的1-6列进行归一化
self.userMatrix矩阵的处理中归一化使用了sklearn.preprocessing.normalize()函数,归一化后方便计算两个user的相似度
这里只计算Event Recommendation Engine Challenge分步解析第一步中的uniqueUserPairs,他们因为同一个event事件关联起来了,有联系
计算相关性用到了scipy.spatial.distance.correlation(u, v) #计算向量u和v之间的相关系数(pearson correlation coefficient, Centered Cosine)
8)第二步完整代码
from collections import defaultdict
import locale, pycountry
import scipy.sparse as ss
import scipy.io as sio
import itertools
#import cPickle
#From python3, cPickle has beed replaced by _pickle
import _pickle as cPickle import scipy.spatial.distance as ssd
import datetime
from sklearn.preprocessing import normalize class ProgramEntities:
"""
我们只关心train和test中出现的user和event,因此重点处理这部分关联数据,
经过统计:train和test中总共3391个users和13418个events
"""
def __init__(self):
#统计训练集中有多少独立的用户的events
uniqueUsers = set()#uniqueUsers保存总共多少个用户:3391个
uniqueEvents = set()#uniqueEvents保存总共多少个events:13418个
eventsForUser = defaultdict(set)#字典eventsForUser保存了每个user:所对应的event
usersForEvent = defaultdict(set)#字典usersForEvent保存了每个event:哪些user点击
for filename in ['train.csv', 'test.csv']:
f = open(filename)
f.readline()#跳过第一行
for line in f:
cols = line.strip().split(',')
uniqueUsers.add( cols[0] )
uniqueEvents.add( cols[1] )
eventsForUser[cols[0]].add( cols[1] )
usersForEvent[cols[1]].add( cols[0] )
f.close() self.userEventScores = ss.dok_matrix( ( len(uniqueUsers), len(uniqueEvents) ) )
self.userIndex = dict()
self.eventIndex = dict()
for i, u in enumerate(uniqueUsers):
self.userIndex[u] = i
for i, e in enumerate(uniqueEvents):
self.eventIndex[e] = i ftrain = open('train.csv')
ftrain.readline()
for line in ftrain:
cols = line.strip().split(',')
i = self.userIndex[ cols[0] ]
j = self.eventIndex[ cols[1] ]
self.userEventScores[i, j] = int( cols[4] ) - int( cols[5] )
ftrain.close()
sio.mmwrite('PE_userEventScores', self.userEventScores) #为了防止不必要的计算,我们找出来所有关联的用户或者关联的event
#所谓关联用户指的是至少在同一个event上有行为的用户user pair
#关联的event指的是至少同一个user有行为的event pair
self.uniqueUserPairs = set()
self.uniqueEventPairs = set()
for event in uniqueEvents:
users = usersForEvent[event]
if len(users) > 2:
self.uniqueUserPairs.update( itertools.combinations(users, 2) )
for user in uniqueUsers:
events = eventsForUser[user]
if len(events) > 2:
self.uniqueEventPairs.update( itertools.combinations(events, 2) )
#rint(self.userIndex)
cPickle.dump( self.userIndex, open('PE_userIndex.pkl', 'wb'))
cPickle.dump( self.eventIndex, open('PE_eventIndex.pkl', 'wb') ) #数据清洗类
class DataCleaner:
def __init__(self):
#一些字符串转数值的方法
#载入locale
self.localeIdMap = defaultdict(int) for i, l in enumerate(locale.locale_alias.keys()):
self.localeIdMap[l] = i + 1 #载入country
self.countryIdMap = defaultdict(int)
ctryIdx = defaultdict(int)
for i, c in enumerate(pycountry.countries):
self.countryIdMap[c.name.lower()] = i + 1
if c.name.lower() == 'usa':
ctryIdx['US'] = i
if c.name.lower() == 'canada':
ctryIdx['CA'] = i for cc in ctryIdx.keys():
for s in pycountry.subdivisions.get(country_code=cc):
self.countryIdMap[s.name.lower()] = ctryIdx[cc] + 1 self.genderIdMap = defaultdict(int, {'male':1, 'female':2}) #处理LocaleId
def getLocaleId(self, locstr):
#这样因为localeIdMap是defaultdict(int),如果key中没有locstr.lower(),就会返回默认int 0
return self.localeIdMap[ locstr.lower() ] #处理birthyear
def getBirthYearInt(self, birthYear):
try:
return 0 if birthYear == 'None' else int(birthYear)
except:
return 0 #性别处理
def getGenderId(self, genderStr):
return self.genderIdMap[genderStr] #joinedAt
def getJoinedYearMonth(self, dateString):
dttm = datetime.datetime.strptime(dateString, "%Y-%m-%dT%H:%M:%S.%fZ")
return "".join( [str(dttm.year), str(dttm.month) ] ) #处理location
def getCountryId(self, location):
if (isinstance( location, str)) and len(location.strip()) > 0 and location.rfind(' ') > -1:
return self.countryIdMap[ location[location.rindex(' ') + 2: ].lower() ]
else:
return 0 #处理timezone
def getTimezoneInt(self, timezone):
try:
return int(timezone)
except:
return 0 class Users:
"""
构建user/user相似度矩阵
"""
def __init__(self, programEntities, sim=ssd.correlation):#spatial.distance.correlation(u, v) #计算向量u和v之间的相关系数
cleaner = DataCleaner()
nusers = len(programEntities.userIndex.keys())#3391
#print(nusers)
fin = open('users.csv')
colnames = fin.readline().strip().split(',') #7列特征
self.userMatrix = ss.dok_matrix( (nusers, len(colnames)-1 ) )#构建稀疏矩阵
for line in fin:
cols = line.strip().split(',')
#只考虑train.csv中出现的用户,这一行是作者注释上的,但是我不是很理解
#userIndex包含了train和test的所有用户,为何说只考虑train.csv中出现的用户
if cols[0] in programEntities.userIndex:
i = programEntities.userIndex[ cols[0] ]#获取user:对应的index
self.userMatrix[i, 0] = cleaner.getLocaleId( cols[1] )#locale
self.userMatrix[i, 1] = cleaner.getBirthYearInt( cols[2] )#birthyear,空值0填充
self.userMatrix[i, 2] = cleaner.getGenderId( cols[3] )#处理性别
self.userMatrix[i, 3] = cleaner.getJoinedYearMonth( cols[4] )#处理joinedAt列
self.userMatrix[i, 4] = cleaner.getCountryId( cols[5] )#处理location
self.userMatrix[i, 5] = cleaner.getTimezoneInt( cols[6] )#处理timezone
fin.close() #归一化矩阵
self.userMatrix = normalize(self.userMatrix, norm='l1', axis=0, copy=False)
sio.mmwrite('US_userMatrix', self.userMatrix) #计算用户相似度矩阵,之后会用到
self.userSimMatrix = ss.dok_matrix( (nusers, nusers) )#(3391,3391)
for i in range(0, nusers):
self.userSimMatrix[i, i] = 1.0 for u1, u2 in programEntities.uniqueUserPairs:
i = programEntities.userIndex[u1]
j = programEntities.userIndex[u2]
if (i, j) not in self.userSimMatrix:
#print(self.userMatrix.getrow(i).todense()) 如[[0.00028123,0.00029847,0.00043592,0.00035208,0,0.00032346]]
#print(self.userMatrix.getrow(j).todense()) 如[[0.00028123,0.00029742,0.00043592,0.00035208,0,-0.00032346]]
usim = sim(self.userMatrix.getrow(i).todense(),self.userMatrix.getrow(j).todense())
self.userSimMatrix[i, j] = usim
self.userSimMatrix[j, i] = usim
sio.mmwrite('US_userSimMatrix', self.userSimMatrix) print('第1步:统计user和event相关信息...')
pe = ProgramEntities()
print('第1步完成...\n') print('第2步:计算用户相似度信息,并用矩阵形式存储...')
Users(pe)
print('第2步完成...\n')
针对该步使用的变量作简单介绍:
self.userMatrix:user稀疏矩阵,shape为(3391,6),3391为train和test中出现的所有user,6列为users.csv中后面user的6列信息,并且已经做了数值转换和归一化
self.userSimMatrix:用户相似度稀疏矩阵,shape为(3391,3391),这里只计算了分步解析第一步中uniqueUserPairs,我们只需要计算出对同一个event有响应的用户之间的相似度,uniqueUserPairs保存了这样的UserPair
import pandas as pd
round(pd.DataFrame(userSimMatrix))
代码示例结果:
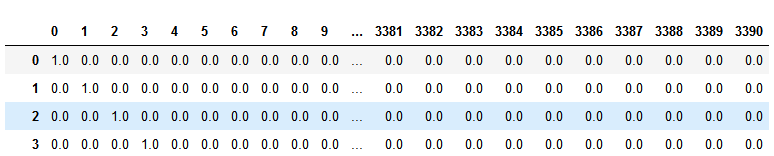
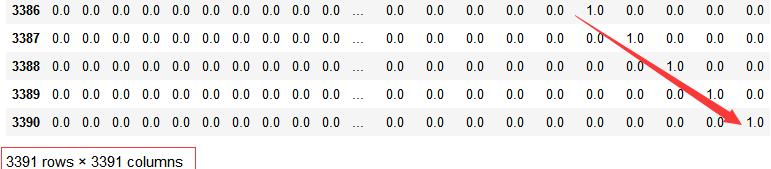
userSimMatrix:用户相似度稀疏矩阵,同一个event有响应的用户之间的相似度
至此,第二步完成,哪里有不明白的请留言
我们继续看Event Recommendation Engine Challenge分步解析第三步
Event Recommendation Engine Challenge分步解析第二步的更多相关文章
- Event Recommendation Engine Challenge分步解析第七步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第六步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第五步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第四步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第一步
一.简介 此项目来自kaggle:https://www.kaggle.com/c/event-recommendation-engine-challenge/ 数据集的下载需要账号,并且需要手机验证 ...
- Event Recommendation Engine Challenge分步解析第三步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- (转) Quick Guide to Build a Recommendation Engine in Python
本文转自:http://www.analyticsvidhya.com/blog/2016/06/quick-guide-build-recommendation-engine-python/ Int ...
- 卷积神经网络 cnnff.m程序 中的前向传播算法 数据 分步解析
最近在学习卷积神经网络,哎,真的是一头雾水!最后决定从阅读CNN程序下手! 程序来源于GitHub的DeepLearnToolbox 由于确实缺乏理论基础,所以,先从程序的数据流入手,虽然对高手来讲, ...
- Comprehensive Guide to build a Recommendation Engine from scratch (in Python) / 从0开始搭建推荐系统
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/, 一篇详细 ...
随机推荐
- 洛谷 P2921 [USACO08DEC]在农场万圣节Trick or Treat on the Farm
题目描述 每年,在威斯康星州,奶牛们都会穿上衣服,收集农夫约翰在N(1<=N<=100,000)个牛棚隔间中留下的糖果,以此来庆祝美国秋天的万圣节. 由于牛棚不太大,FJ通过指定奶牛必须遵 ...
- Elasticsearch 分片路由原理指定分片存储查询
Elasticsearch 项目中使用到Es的父子结构.在数据填充之后,查看每个节点的数据分布情况,发现有的节点数据多,有的节点少的情况,在未使用Es父级结构之前,每个节点的数据分布还算平均,如下图: ...
- Ionic的页面堆栈与Tabs菜单相遇的问题(页面堆栈有多个)
本来的需求: 新建的Ionic项目是Tabs菜单,假设有两个选项卡 A 和 B(从左到右),对应的两个页面的代码完全一样,使用了echarts 插件,并且使用了一个获取页面元素的方法,给自己的一个变量 ...
- 【Gym 100971G】Repair
BUPT 2017 summer training (for 16) #1B 题意 Alex is repairing his country house. He has a rectangular ...
- k短路模板(洛谷P2483 [SDOI2010]魔法猪学院)(k短路,最短路,左偏树,priority_queue)
你谷数据够强了,以前的A*应该差不多死掉了. 所以,小伙伴们快来一起把YL顶上去把!戳这里! 俞鼎力的课件 需要掌握的内容: Dijkstra构建最短路径树. 可持久化堆(使用左偏树,因其有二叉树结构 ...
- Hdoj 2018.母牛的故事 题解
Problem Description 有一头母牛,它每年年初生一头小母牛.每头小母牛从第四个年头开始,每年年初也生一头小母牛.请编程实现在第n年的时候,共有多少头母牛? Input 输入数据由多个测 ...
- [luogu3246][bzoj4540][HNOI2016]序列【莫队+单调栈】
题目描述 给定长度为n的序列:a1,a2,...,an,记为a[1:n].类似地,a[l:r](1<=l<=r<=N)是指序列:al,al+1,...,ar-1,ar.若1<= ...
- 「SCOI2016」围棋 解题报告
「SCOI2016」围棋 打CF后困不拉基的,搞了一上午... 考虑直接状压棋子,然后发现会t 考虑我们需要上一行的状态本质上是某个位置为末尾是否可以匹配第一行的串 于是状态可以\(2^m\)压住了, ...
- 清理XFCE4卸载残留
apt-get remove xfce4 apt-get remove xfce4* apt-get autoremove apt-get autoclean apt-get clean --- 更新 ...
- cf351B Jeff and Furik (树状数组)
逆序对数=0的时候,这个数列是有序的 然后交换相邻的,看哪个比较大,逆序对数会加1或减1 Jeff用的是最优策略所以他肯定让逆序对数-1 设f[i]表示Jeff操作前,逆序对数为i,最终的期望次数 那 ...