Reinforcement Learning: An Introduction读书笔记(4)--动态规划
> 目 录 <
- Dynamic programming
- Policy Evaluation (Prediction)
- Policy Improvement
- Policy Iteration
- Value Iteration
- Asynchronous Dynamic Programming
- Generalized Policy Iteration
> 笔 记 <
Dynamic programming(DP)
定义:a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP).
经典的DP算法处理RL problem的能力有限的原因:(1) 假设a perfect model with complete knowledge;(2) 巨大的计算开销
Policy Evaluation (Prediction)
policy evaluation: the iterative computation of the state-value function $v_{\pi}$ for a given policy $\pi$.

用迭代=的方法实现评估: 旧的value = expected immediate rewards + 从后继states获得的values
这种更新操作叫做expected update,因为它基于所有可能的后继states的期望,而非单个next state sample。
存储方式:有two-array version(同时存储old和new value) 和 in-place algorithm(只存储new value)两种,通常采用后者,收敛的更快。

Policy Improvement
我们计算policy的价值函数的目的是希望能够帮助我们找到更好的policy。
Policy improvement theorem:
两个确定的策略$\pi$和$\pi'$,如果满足:
那么策略$\pi'$一定比$\pi$好or跟它一样好。因此,策略$\pi'$可以在所有state上得到更多or相等的expected return:
证明如下:
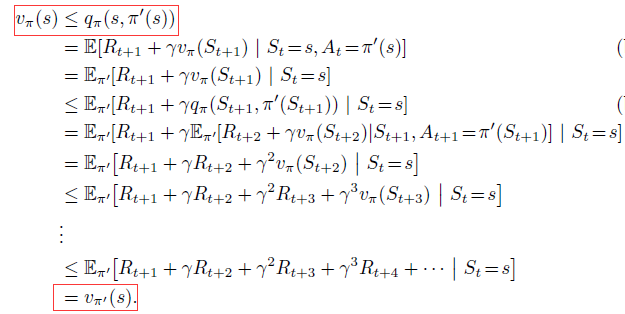
Policy improvement:
定义: Policy improvement refers to the computation of an improved policy given the value function for that policy.
相比原始策略$\pi$,如果我们在所有states上采用贪心算法来选择action,那么得到的新策略如下:
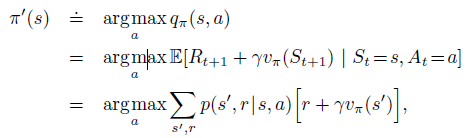
因为其满足policy improvement theorem的条件,所以新的greedy policy $\pi'$要比old policy更好。我们可以根据这一性质,不断地对policy进行改进,直到new policy和old policy一样好,即$v_{\pi}=v_{\pi'}$,此时对所有的states满足:
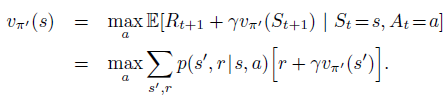
该式子正是Bellman optimality equation,因此$v_{\pi'}$一定是$\v_{*}$, 策略$\pi$和$\pi‘’$一定是最优策略。
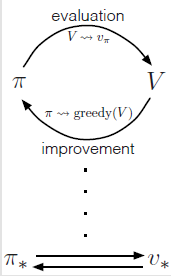
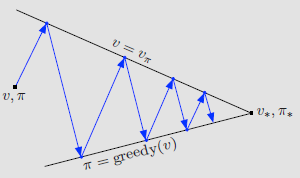
Policy Iteration
定义: 一种把policy evaluation和policy improvement结合在一起的常见的DP方法。
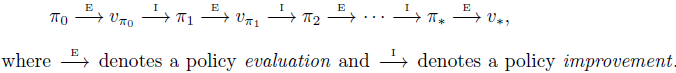
因为finite MDP只有有限数量的策略,因此最终总会在有限步数内收敛到一个optimal policy和optimal value function。

Value Iteration
policy iteration的缺点:每一轮迭代都需要执行policy evaluation,而policy evaluation需要对state set扫描多次并且$\v_{\pi}$最终很久才能收敛。
改进方法:可否让policy evaluation早一些停止?value iteration不再等policy evaluation收敛,而是只对所有state扫描一次就停止。将policy evaluation和policy improvement的步骤同时进行:

Asynchronous Dynamic Programming
之前讨论的DP方法的缺点在于:需要对MDP中所有states进行扫描、操作,导致效率低下。
Asynchronous DP algorithms: 是in-place iterative DP algorithms,这类算法可以按照任意顺序更新state的value,并且不管其他states当前的value是何时更新的。
需要注意的是,avoiding state sweeps并不意味着我们可以减少计算量,其好处是(1) 可以让我们尽快利用更新后的value来提升policy,并且减少更新那些无用的states。(2)可以实时计算,所以可以实现iterative DP algorithm at the same time that agent is actually experiencing the MDP。agent经历可以用于决定更新那些states。
Generalized Policy Iteration
generalized policy iteration (GPI):policy-evaluation and policy-improvement processes interaction
Reinforcement Learning: An Introduction读书笔记(4)--动态规划的更多相关文章
- Reinforcement Learning: An Introduction读书笔记(3)--finite MDPs
> 目 录 < Agent–Environment Interface Goals and Rewards Returns and Episodes Policies and Val ...
- Reinforcement Learning: An Introduction读书笔记(1)--Introduction
> 目 录 < learning & intelligence 的基本思想 RL的定义.特点.四要素 与其他learning methods.evolutionary m ...
- Reinforcement Learning: An Introduction读书笔记(2)--多臂机
> 目 录 < k-armed bandit problem Incremental Implementation Tracking a Nonstationary Problem ...
- 《Machine Learning Yearing》读书笔记
——深度学习的建模.调参思路整合. 写在前面 最近偶尔从师兄那里获取到了吴恩达教授的新书<Machine Learning Yearing>(手稿),该书主要分享了神经网络建模.训练.调节 ...
- Machine Learning for hackers读书笔记(六)正则化:文本回归
data<-'F:\\learning\\ML_for_Hackers\\ML_for_Hackers-master\\06-Regularization\\data\\' ranks < ...
- 《算法导论》读书笔记之动态规划—最长公共子序列 & 最长公共子串(LCS)
From:http://my.oschina.net/leejun2005/blog/117167 1.先科普下最长公共子序列 & 最长公共子串的区别: 找两个字符串的最长公共子串,这个子串要 ...
- Machine Learning for hackers读书笔记(三)分类:垃圾邮件过滤
#定义函数,打开每一个文件,找到空行,将空行后的文本返回为一个字符串向量,该向量只有一个元素,就是空行之后的所有文本拼接之后的字符串 #很多邮件都包含了非ASCII字符,因此设为latin1就可以读取 ...
- Machine Learning for hackers读书笔记_一句很重要的话
为了培养一个机器学习领域专家那样的直觉,最好的办法就是,对你遇到的每一个机器学习问题,把所有的算法试个遍,直到有一天,你凭直觉就知道某些算法行不通.
- Machine Learning for hackers读书笔记(十二)模型比较
library('ggplot2')df <- read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\12-Model_C ...
随机推荐
- Openvswitch手册(7): Interfaces
我们来看Interfaces ofport: OpenFlow port number for this interface. type: system: An ordinary network de ...
- flask上下文详解
一.前言 了解过flask的python开发者想必都知道flask中核心机制莫过于上下文管理,当然学习flask如果不了解其中的处理流程,可能在很多问题上不能得到解决,当然我在写本篇文章之前也看到了很 ...
- 微服务中Feign快速搭建
在微服务架构搭建声明性REST客户端[feign].Feign是一个声明式的Web服务客户端.这使得Web服务客户端的写入更加方便 要使用Feign创建一个界面并对其进行注释.它具有可插入注释支持,包 ...
- Android 代码混淆配置总结
一.前言 为何需要混淆呢?简单的说,就是将原本正常的项目文件,对其类,方法,字段,重新命名,a,b,c,d,e,f…之类的字母,达到混淆代码的目的,这样反编译出来,结构乱糟糟的,看了也头大. 另外说明 ...
- 12、json、GridView、缓存
1.解析json数据: public class PhotosData { public int retcode; public PhotosInfo data; public class Photo ...
- 微信小程序 - 相对定位和绝对定位 - 相对路径和绝对路径
微信小程序 - 相对定位和绝对定位 相对定位relative,绝对定位absolute 相对定位:元素是相对自身进行定位,参照物是自己. 绝对定位:元素是相对离它最近的一个父级元素进行定位. 相对定位 ...
- MD5( 信息摘要算法)的概念原理及python代码的实现
简述: message-digest algorithm 5(信息-摘要算法).经常说的“MD5加密”,就是它→信息-摘要算法. md5,其实就是一种算法.可以将一个字符串,或文件,或压缩包,执行md ...
- react-native热更新之CodePush详细介绍及使用方法
react-native热更新之CodePush详细介绍及使用方法 2018年03月04日 17:03:21 clf_programing 阅读数:7979 标签: react native热更新co ...
- 使用maven插件构建docker镜像
为什么要用插件 主要还是自动化的考虑,如果额外使用Dockerfile进行镜像生成,可能会需要自己手动指定jar/war位置,并且打包和生成镜像间不同步,带来很多琐碎的工作. 插件选择 使用比较多的是 ...
- Redis(4)---主从复制
Redis主从复制 一.环境搭建 既然是主从复制,那肯定需要多个redis服务器,下面我先创建3个服务器,™的端口号分别是:6379.6380.6381. 1.复制默认配置文件redis ...