【NLP】How to Generate Embeddings?
How to represent words.
0 .
Native represtation: one-hot vectors
Demision: |all words|
(too large and hard to express senmatic similarity)
Idea:produce dense vector representations based on the context/use of words
So, there are Three main approaches:
1.
Count-based methods
(1) Define a basis vocabulary C(lower than all words dimision) of context words(expect:the、a、of…)
(2) Define a word window size W
(3) Count the basis vocabulary words occurring W words to the left or right of each instance of a target word in the corpus
(4) From a vector represtation of the target word based on these counts
Example-express:


We can calculate the similarity of two words using inner product or cosine.
For instance.

2.
Neural Embedding Models(Main Idea)
To generate an embedding matrix in R(|all words| * |context words|) which looks like:
 (count based vectors)
(count based vectors)
Rows are word vectores.
We can retrieve a certain word vector with one-hot vector.

(One)generic idea behind embedding learning:
(1) Collect instances ti∈inst(t) of a word t of vocab V
(2) For each instance, collect its context word c(ti) (e.g.k-word window)
(3) Define some score function score(ti,c(ti),θ,E) with upper bound on output
(4) Define a loss

(5) Estimate:
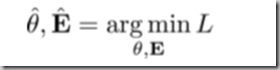
(6) Use the estimated E as the embedding matrix
Attention:
Scoring function estimates whether a sentence(or the object word and its context) is said or used normally by a people,so the higher the score,the more likely it is.
3.
C&W
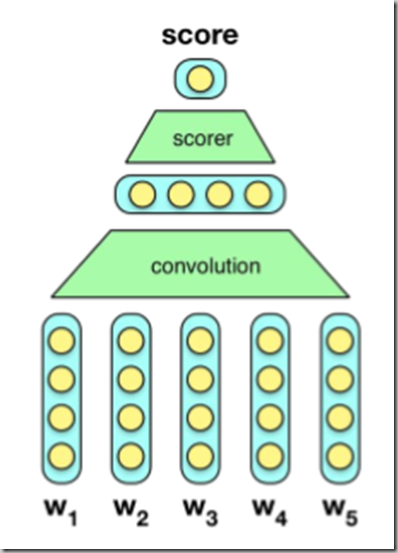
Firstly,we embed all words in a sentence with E.
Then,sentence(w1,w2,w3,w4,w5) goes through a convolution layer(maybe just simpal connection layer).
Then,it goes through a simpal MLP.
Then,it goes through the ‘scorer’layer and output the final Score.
Minimize the loss function(!),and use the parameter matrix of input layer and ..


4. Word2Vec
1) CBoW(contextual bag of words)
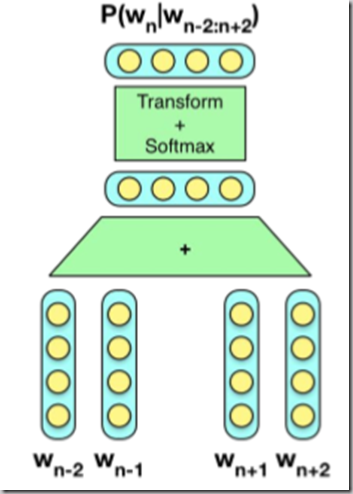

2) Skip-gram:


【NLP】How to Generate Embeddings?的更多相关文章
- 【NLP】前戏:一起走进条件随机场(一)
前戏:一起走进条件随机场 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有 ...
- 【NLP】基于自然语言处理角度谈谈CRF(二)
基于自然语言处理角度谈谈CRF 作者:白宁超 2016年8月2日21:25:35 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】基于机器学习角度谈谈CRF(三)
基于机器学习角度谈谈CRF 作者:白宁超 2016年8月3日08:39:14 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都 ...
- 【NLP】基于统计学习方法角度谈谈CRF(四)
基于统计学习方法角度谈谈CRF 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】条件随机场知识扩展延伸(五)
条件随机场知识扩展延伸 作者:白宁超 2016年8月3日19:47:55 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有应 ...
- 【NLP】Tika 文本预处理:抽取各种格式文件内容
Tika常见格式文件抽取内容并做预处理 作者 白宁超 2016年3月30日18:57:08 摘要:本文主要针对自然语言处理(NLP)过程中,重要基础部分抽取文本内容的预处理.首先我们要意识到预处理的重 ...
- [转]【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理 阅读目录
[NLP]干货!Python NLTK结合stanford NLP工具包进行文本处理 原贴: https://www.cnblogs.com/baiboy/p/nltk1.html 阅读目录 目 ...
- 【NLP】Conditional Language Models
Language Model estimates the probs that the sequences of words can be a sentence said by a human. Tr ...
- 【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理
干货!详述Python NLTK下如何使用stanford NLP工具包 作者:白宁超 2016年11月6日19:28:43 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的 ...
随机推荐
- C# Oracle 时间字符串转时间类型
C# 字符串转时间类型 yyyy-MM-dd HH:mm:ss yyyy-MM-dd hh:mm:ss d 月中的某一天.一位数的日期没有前导零. dd 月中的某一天.一位数的日期有一个前导零. d ...
- 测试工具使用-Qunit单元测试使用过程
031302620 应课程要求写一篇单元测试工具的博客,但是暂时没用到java,所以不想使用junit(对各种类都不熟悉的也不好谈什么测试),原计划是要用phpunit,但是安装经历了三个小时,查阅各 ...
- 1、话说linux内核
1.内核和发行版的区别 到底什么是操作系统 linux.windows.android.ucos就是操作系统 操作系统本质上是一个程序,由很多个源文件构成,需要编译连接成操作系统程序(vmlinz.z ...
- UVA12253 简单加密法 Simple Encryption
这题到现在还是只有我一个人过?太冷门了吧,毕竟你谷上很少有人会去做往年ACM比赛的题 题面意思很简单,每次给出\(K_1\),让你求一个\(K_2\)满足\(K_1^{K_2}\equiv K_2(\ ...
- JVM总括:目录
JVM总括:目录 JVM总括一-JVM内存模型 JVM总括二-垃圾回收:GC Roots.回收算法.回收器 JVM总括三-字节码.字节码指令.JIT编译执行 JVM总括四-类加载过程.双亲委派模型.对 ...
- Python股票分析系列——基础股票数据操作(二).p4
该系列视频已经搬运至bilibili: 点击查看 欢迎来到Python for Finance教程系列的第4部分.在本教程中,我们将基于Adj Close列创建烛台/ OHLC图,这将允许我介绍重新采 ...
- C#.NET 大型通用信息化系统集成快速开发平台 4.1 版本 - 访问记录功能改进
当用户数据非常庞大时需要一个功能,就是统计各种账户的访问系统的情况,用户数量的各种参数需要让管理者心里有个数. 1:信息系统中有多少有效账户?可以很方便能知道具体个数,让管理者心里有个数. 2:某个公 ...
- Docker镜像的修改和自定义
一.docker镜像的更新 (1)启动镜像,写入一些文件或者更新软件 docker run -it 3afd47092a0e[root@44652ba46352 /]# ls (2)更新镜像 dock ...
- Python魔法函数
python中定义的以__开头和结尾的的函数.可以随意定制类的特性.魔法函数定义好之后一般不需要我们自己去调用,而是解释器会自动帮我们调用. __getitem__(self, item) 将类编程一 ...
- lower_bound函数与upper_bound函数
头文件 : algorithm vector<int>a a中的元素必须升序,用的是二分 lower_bound(a.begin(),a.end(),k) 返回a容器中,最右边的小于等于k ...