Hadoop原理之——HDFS原理
Hadoop 3个核心组件:
分布式文件系统:Hdfs——实现将文件分布式存储在很多的服务器上(hdfs是一个基于Linux本地文件系统上的文件系统)
分布式运算编程框架:Mapreduce——实现在很多机器上分布式并行运算
分布式资源调度平台:Yarn——帮用户调度大量的mapreduce程序,并合理分配运算资源
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得都。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
HDFS的关键元素:
1、Block:将一个文件进行分块,通常是64M。
2、NameNode:保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一 一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在 Hadoop2.* 开始支持 activity-standy 模式----如果主 NameNode 失效,启动备用主机运行 NameNode。
3、DataNode:分布在廉价的计算机上,用于存储Block块文件。
如果你想了解大数据的学习路线,想学习大数据知识以及需要免费的学习资料可以加群:784789432.欢迎你的加入。每天下午三点开直播分享基础知识,晚上20:00都会开直播给大家分享大数据项目实战。
一、HDFS运行原理
1、NameNode和DataNode节点初始化完成后,采用RPC进行信息交换,采用的机制是心跳机制,即DataNode节点定时向NameNode反馈状态信息,反馈信息如:是否正常、磁盘空间大小、资源消耗情况等信息,以确保NameNode知道DataNode的情况;
2、NameNode会将子节点的相关元数据信息缓存在内存中,对于文件与Block块的信息会通过fsImage和edits文件方式持久化在磁盘上,以确保NameNode知道文件各个块的相关信息;
3、NameNode负责存储fsImage和edits元数据信息,但fsImage和edits元数据文件需要定期进行合并,这时则由SecondNameNode进程对fsImage和edits文件进行定期合并,合并好的文件再交给NameNode存储。
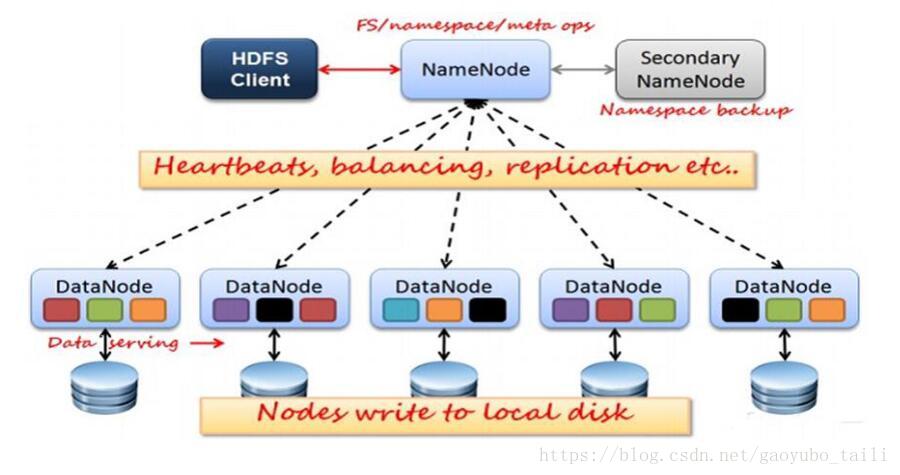
二、HDFS数据合并原理
1、NameNode初始化时会产生一个edits文件和一个fsimage文件,edits文件用于记录操作日志,比如文件的删除或添加等操作信息,fsImage用于存储文件与目录对应的信息以及edits合并进来的信息,即相当于fsimage文件在这里是一个总的元数据文件,记录着所有的信息;
2、随着edits文件不断增大,当达到设定的一个阀值的时候,这时SecondaryNameNode会将edits文件和fsImage文件通过采用http的方式进行复制到SecondaryNameNode下(在这里考虑到网络传输,所以一般将NameNode和SecondaryNameNode放在相同的节点上,这样就无需走网络带宽了,以提高运行效率),同时NameNode会产生一个新的edits文件替换掉旧的edits文件,这样以保证数据不会出现冗余;
3、SecondaryNameNode拿到这两个文件后,会在内存中进行合并成一个fsImage.ckpt的文件,合并完成后,再通过http的方式将合并后的文件fsImage.ckpt复制到NameNode下,NameNode文件拿到fsImage.ckpt文件后,会将旧的fsimage文件替换掉,并且改名成fsimage文件。
通过以上几步则完成了edits和fsimage文件的合并,依此不断循环,从而到达保证元数据的正确性。
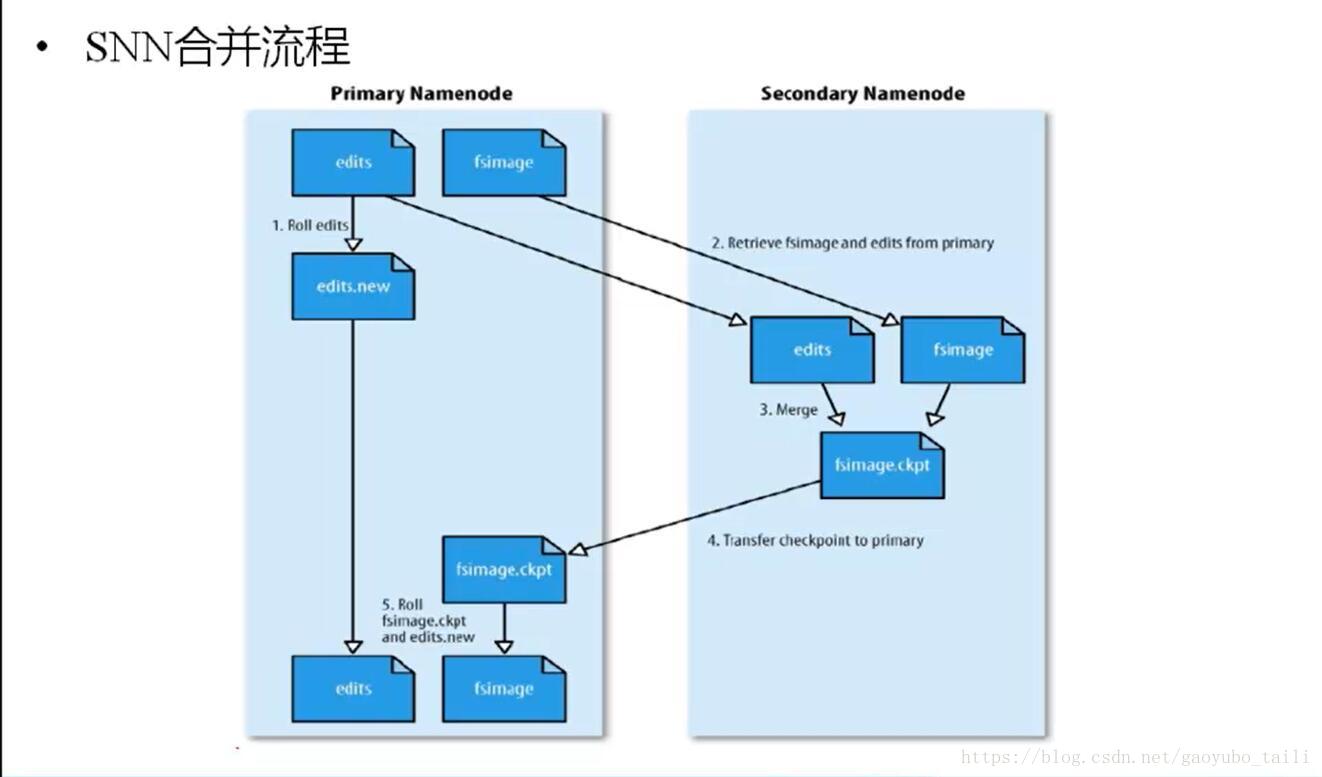
三、HDFS写原理
1、HDFS客户端提交写操作到NameNode上,NameNode收到客户端提交的请求后,会先判断此客户端在此目录下是否有写权限,如果有,然后进行查看,看哪几个DataNode适合存放,再给客户端返回存放数据块的节点信息,即告诉客户端可以把文件存放到相关的DataNode节点下;
2、客户端拿到数据存放节点位置信息后,会和对应的DataNode节点进行直接交互,进行数据写入,由于数据块具有副本replication,在数据写入时采用的方式是先写第一个副本,写完后再从第一个副本的节点将数据拷贝到其它节点,依次类推,直到所有副本都写完了,才算数据成功写入到HDFS上,副本写入采用的是串行,每个副本写的过程中都会逐级向上反馈写进度,以保证实时知道副本的写入情况;
3、随着所有副本写完后,客户端会收到数据节点反馈回来的一个成功状态,成功结束后,关闭与数据节点交互的通道,并反馈状态给NameNode,告诉NameNode文件已成功写入到对应的DataNode。
代码实现
- /*
- * 测试HDFS写入数据
- */
- @Test
- public void Test1() throws IOException {
- // 加载配置文件
- Configuration conf = new Configuration();
- FileSystem fs = FileSystem.get(conf);
- Path path = new Path("/gyb/student.txt");
- // 产生IO流
- FSDataOutputStream fsio = fs.create(path);
- // 包装输出IO流
- BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(fsio));
- // 包装输入IO流
- BufferedReader br = new BufferedReader(
- new InputStreamReader(new FileInputStream("student.txt")));
- String line = null;
- while ((line = br.readLine()) != null) {
- bw.write(line);
- bw.newLine();
- bw.flush();
- }
- bw.close();
- br.close();
- }
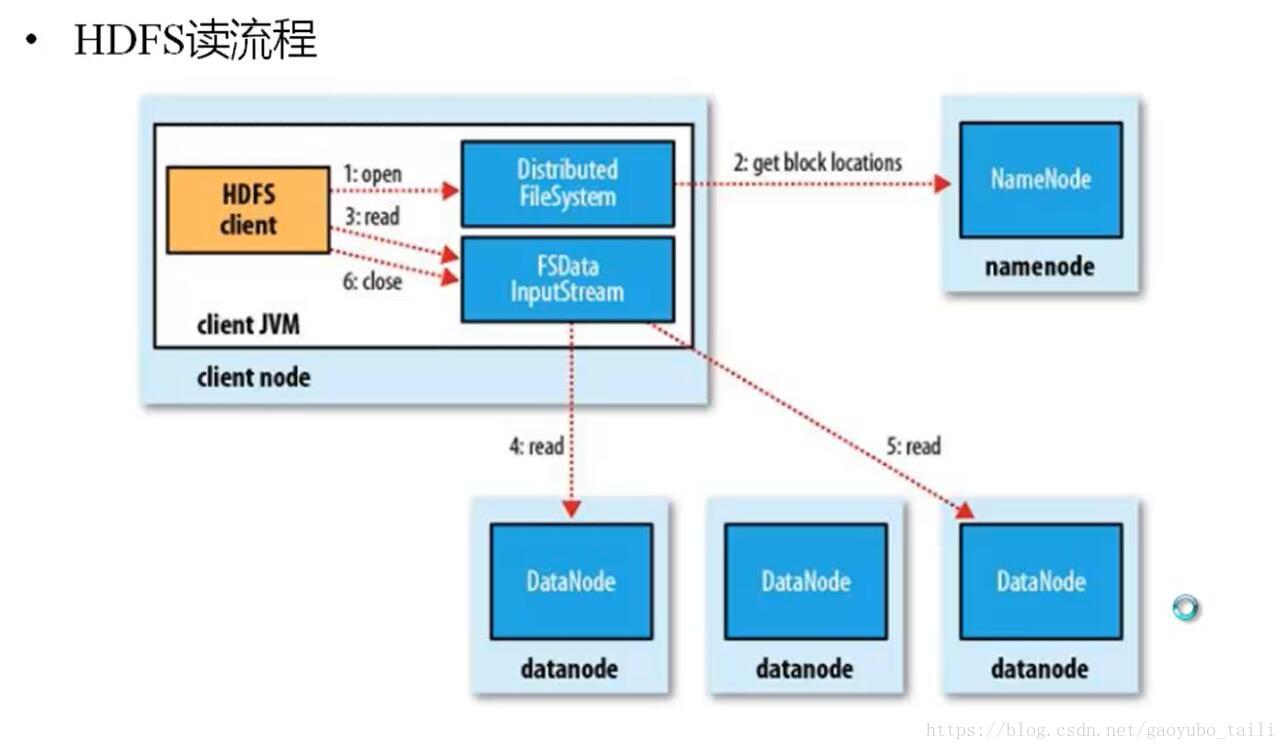
四、HDFS读原理
1、HDFS客户端提交读操作到NameNode上,NameNode收到客户端提交的请求后,会先判断此客户端在此目录下是否有读权限,如果有,则给客户端返回存放数据块的节点信息,即告诉客户端可以到相关的DataNode节点下去读取数据块;
2、客户端拿到块位置信息后,会去和相关的DataNode直接构建读取通道,读取数据块,当所有数据块都读取完成后关闭通道,并给NameNode返回状态信息,告诉NameNode已经读取完毕。
代码实现
- /*
- * 测试HDFS读出的操作
- */
- @Test
- public void Test3() throws IOException {
- // 加载配置类
- Configuration conf = new Configuration();
- FileSystem fs =FileSystem.newInstance(conf);
- Path path = new Path("/gyb/student.txt");
- FileStatus[] fileStatus = fs.listStatus(path);
- for (FileStatus fileStatus2 : fileStatus) {
- if(fileStatus2 != null && fileStatus2.isFile()) {
- //open方法只能传文件
- FSDataInputStream fsi = fs.open(path);
- // 包装IO流
- BufferedReader br = new BufferedReader(new InputStreamReader(fsi));
- while(br.ready()) {
- System.out.println(br.readLine());
- }
- }
- }
- System.out.println("--------over--------");
- }
Hadoop原理之——HDFS原理的更多相关文章
- hadoop学习之HDFS原理
HDFS原理 HDFS包括三个组件: NameNode.DataNode.SecondaryNameNode NameNode的作用是存储元数据(文件名.创建时间.大小.权限.与block块映射关系等 ...
- [Hadoop]Hadoop章2 HDFS原理及读写过程
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统. HDFS有很多特点: ① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份. ② ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理、深入解析Hadoop Common和HDFS架构设计与实现原理
这是我收集的两本关于Hadoop的书,高清PDF版,在此和大家分享: 1.<Hadoop技术内幕:深入理解MapReduce架构设计与实现原理>董西成 著 机械工业出版社2013年5月出 ...
- hadoop平台上HDFS和MAPREDUCE的功能、工作原理和工作过程
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce ...
- 【Hadoop】HDFS原理、元数据管理
1.HDFS原理 2.元数据管理原理
随机推荐
- 修改虚拟机ip备份
修改虚拟机ip 因为别人写的很好,在此备份一下.
- 【NLP_Stanford课堂】语言模型3
一.产生句子 方法:Shannon Visualization Method 过程:根据概率,每次随机选择一个bigram,从而来产生一个句子 比如: 从句子开始标志的bigram开始,我们先有一个( ...
- tomcat运行报错Failed to start component [StandardEngine[Catalina].StandardHost[localhost].
tomcat运行报错Failed to start component [StandardEngine[Catalina].StandardHost[localhost].多半情况是找不到jar包 解 ...
- 三、docker学习笔记——安装postgresql
1.docker pull postgres 2.docker run --name postgres -e POSTGRES_PASSWORD=123456 -p 5432:5432 -d post ...
- Python初学者第七天 字符串及简单操作
7day 数据类型:字符串 1.定义 字符串是一个有序的字符的集合,用于储存和表示基本的文本信息.单.双.三引号之间的内容称之为字符串: a = ‘hello world!’ b = "你好 ...
- July 01st 2017 Week 26th Saturday
Kind hearts are more than coronets. 善良的心灵胜于显贵的地位. Some people say that this is a dog-eat-dog world, ...
- ThinkPHP最新版本SQL注入漏洞
如下controller即可触发SQL注入: code 区域 public function test() { $uname = I('get.uname'); $u = M('user')-> ...
- 利物浦VS热刺,我努力不去想,但利物浦真的在争冠
用这张图作为开头吧,早餐的时候打开网易,苏神破门红军4-0登榜首的新闻,习惯性的点进去看看KOP的评论,有一句回复『利物浦该夺冠了,多少年了.喜欢利物浦比喜欢老婆还早,老婆都成黄脸婆了.现在带着女 ...
- Bootstrap Multiselect
Getting Started Link the Required Files First, the jQuery library needs to be included. Then Twitter ...
- thinkphp5.0查询到的数据表中的路径是反斜杠导致无法正常显示图片怎么办?
添加到数据表中图片的路径有时会是反斜杠,这就导致了在url后面写路径的时候会识别不出来(不过src后面写路径就可以识别),所以就需要把路径中的反斜杠替换成正斜杠,代码如下: $datu = Db::q ...