Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle。。。相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量。相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuffle过程进行了优化。
那么我们从RDD的iterator方法开始:

我们可以看到,它调用了cacheManager的getOrCompute方法,如果分区任务第一次执行还没有缓存,那么会调用computeOrReadCheckpoint。如果某个partition任务执行失败,可以利用DAG重新调度,失败的partition任务将从检查点恢复状态,而那些已经成功执行的partition任务由于其执行结果已经缓存到存储体系,所以调用CacheManager.getOrCompue方法,不需要再次执行。
在computeOrReadCheckpoint中,如果存在检查点时,则进行中间数据的拉取,否则将会重新执行compute,我们知道RDD具有linkage机制,所以可以直接找到其父RDD。

那么compute方法实现了什么呢?从最底层的HadoopRDD看起,所有类型的RDD都继承自抽象RDD类。HadoopRDD compute方法如下图:
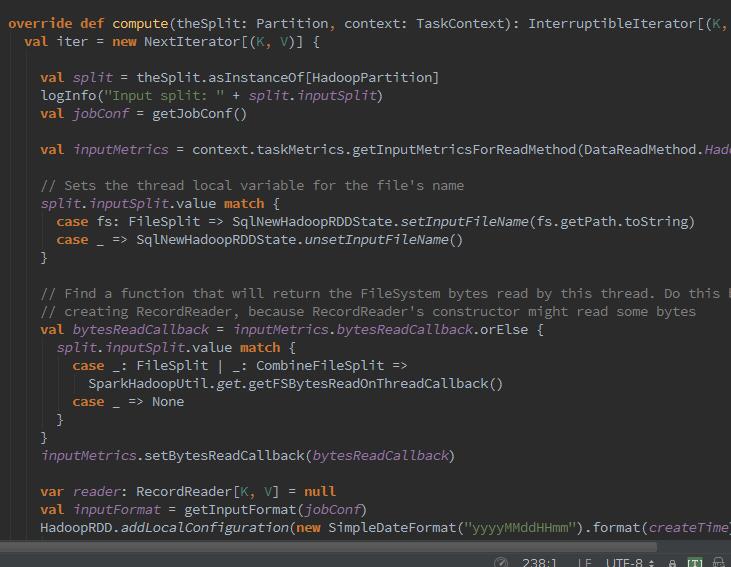
它实现了一个NextIterator的一个内部类,你有没有发现那个"input split:"这个日志很熟悉,没错,就是跑任务时在container日志中打印的日志信息,也就是第一次数据获取。然后这个内部类搞了一些事情,从broadcast中获取jobConf(hadoop的Configuration)、创建inputMetrics用于计算字节读取的测量信息。随之RecoredReader读取数据之前创建bytesReadCallback,是用来获取当前线程从文件系统读取的字节数。随后获取inputFormat:
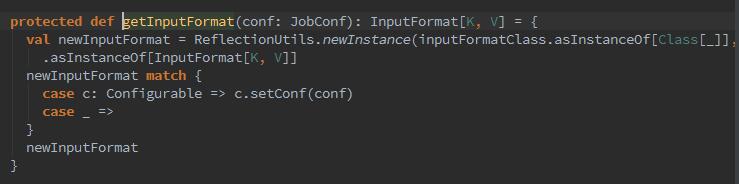
随后加入hadoop的配置信息,再通过 reader:RecordReader读取数据。最终会new出一个InterruptibleIterator对象。这个对象用于map结束后的SortShuffleWriter的write方法。因为本身mapReduce的过程就是要写入磁盘的,如图:
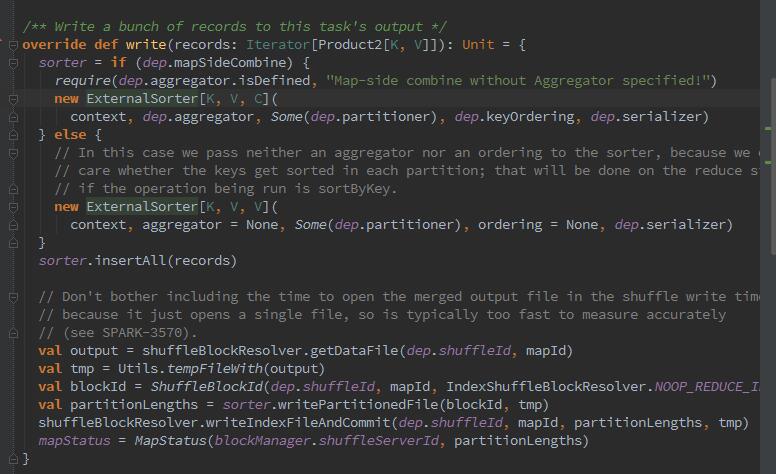
查阅资料,它主要干了如下事情:
1、创建ExternalSorter,调用insertAll将计算结果写入缓存。
2、调用shuffleBlockManager.getDataFile方法获取当前任务要输出的文件路径。
3、调用shuffleBlockManager.consolidateId创建blockId。
4、调用ExternalSorter的writePartitionFile将中间结果持久化。
5、调用shuffleBlockManager.writeIndexFile方法创建索引文件。
6、最终创建MapStatus。
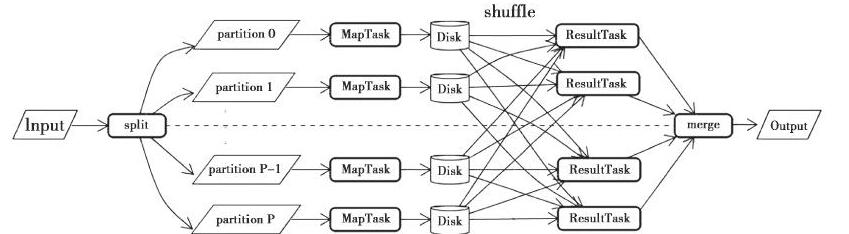
这里有个重中之重,也就是Hadoop MapReduce过程的问题所在:
1、Hadoop在reduce任务获取到map任务的中间输出后,会对这些数据在磁盘上进行merge sort,产生更多的磁盘I/O.
2、当数据量很小,但是map任务和reduce任务数目很多时,会产生很多网络I/O.
那么spark的优化在于:
1、map任务逐条输出计算结果,而不是一次性输出到内存,并使用AppendOnlyMap缓存及其聚合算法对中间结果进行聚合,大大减少了中间结果所占内存的大小。
2、当超出myMemoryThreshold的大小时,将数据写入磁盘,防止内存溢出。
3、reduce任务也是逐条拉取,并且也用了AppendOnlyMap缓存,并在内存中进行聚合和排序,也大大减少了数据占用的内存。
4、reduce任务对将要拉取的Block按照BlockManager划分,然后将同一blockManager地址中的Block累积为少量网络请求,减少网络I/O.
这里有个参数,spark.shuffle.sort.bypassMergeThreshold,修改bypassMergeThreshold的大小,在分区数量小的时候提升计算引擎的性能。这个参数主要在partition的数量小于bypassMergeThreshold的值时,就不再Executor中执行聚合和排序操作,知识将各个partition直接写入Executor中进行存储。
还有一个参数,spark.shuffle.sort.bypassMergeSort,这个参数标记是否传递到reduce端再做合并和排序,当没有定义aggregator、ordering函数,并且partition数量小于等于bypassMergeThreshold时,bypassMergeSort为true.如果bypassMergeSort为true,map中间结果将直接输出到磁盘,就不会占用内存。
那么 哪些Block从本地获取、哪些需要远程拉取,是获取中间计算结果的关键。那么reduce端如何处理多个map任务的中间结果?
这里有个优化的参数spark.reducer.maxMbInFlight,这是单次航班请求的最大字节数,意思是一批请求,这批请求的字节总数不能超过maxBytesInFlight,而且每个请求的字节数不能超过maxBytesInfFlight的五分之一,这样做是为了提高请求的并发度,允许5个请求分别从5个节点拉取数据。
调优方案:
1、在map端溢出分区文件,在reduce端合并组合
bypassMergeSort不使用缓存,将数据按照paritition写入不同文件,最后按partition顺序合并写入同一文件。但没有指定聚合、排序函数,且partition数量较小时,一般蚕蛹这种方式。它将多个bucket合并到一个文件,减少map输出的文件数量,节省磁盘I/O,最终提升了性能。

2、在map端简单排序、排序分组,在reduce端合并并组合
在缓存中利用指定的排序函数对数据按照partition或者Key进行排序,按partition顺序合并写入同一文件。当没有指定聚合函数,且partition数量大时,采用这种方式。
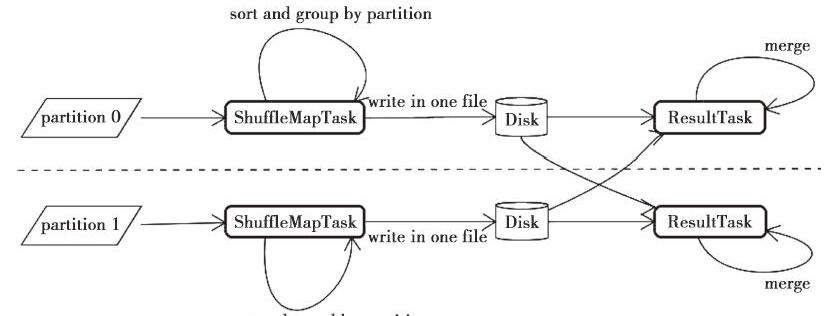
3、在map端缓存中聚合、排序分组,在reduce端组合
在缓存中对数据按照key聚合,并且利用指定的排序函数对数据按照partition或者key进行排序,最后按partition顺序合并写入同一文件。当指定了聚合函数时,采用这种方式。
参考文献:《深入理解Spark:核心思想与源码分析》
Spark Shuffle数据处理过程与部分调优(源码阅读七)的更多相关文章
- [Spark性能调优] 源码补充 : Spark 2.1.X 中 Unified 和 Static MemoryManager
本课主题 Static MemoryManager 的源码鉴赏 Unified MemoryManager 的源码鉴赏 引言 从源码的角度了解 Spark 内存管理是怎么设计的,从而知道应该配置那个参 ...
- Spark BlockManager的通信及内存占用分析(源码阅读九)
之前阅读也有总结过Block的RPC服务是通过NettyBlockRpcServer提供打开,即下载Block文件的功能.然后在启动jbo的时候由Driver上的BlockManagerMaster对 ...
- MapReduce shuffle过程剖析及调优
MapReduce简介 在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的.数据从Mapper输出到Reducer接收,是一个很复杂的过程,框架处理了所有问 ...
- Spark数据本地化-->如何达到性能调优的目的
Spark数据本地化-->如何达到性能调优的目的 1.Spark数据的本地化:移动计算,而不是移动数据 2.Spark中的数据本地化级别: TaskSetManager 的 Locality L ...
- Spark机器学习——模型选择与参数调优之交叉验证
spark 模型选择与超参调优 机器学习可以简单的归纳为 通过数据训练y = f(x) 的过程,因此定义完训练模型之后,就需要考虑如何选择最终我们认为最优的模型. 如何选择最优的模型,就是本篇的主要内 ...
- Spark SQL概念学习系列之性能调优
不多说,直接上干货! 性能调优 Caching Data In Memory Spark SQL可以通过调用sqlContext.cacheTable("tableName") 或 ...
- Spark源码阅读之存储体系--存储体系概述与shuffle服务
一.概述 根据<深入理解Spark:核心思想与源码分析>一书,结合最新的spark源代码master分支进行源码阅读,对新版本的代码加上自己的一些理解,如有错误,希望指出. 1.块管理器B ...
- Spark技术内幕:Stage划分及提交源码分析
http://blog.csdn.net/anzhsoft/article/details/39859463 当触发一个RDD的action后,以count为例,调用关系如下: org.apache. ...
- Spark技术内幕: Task向Executor提交的源码解析
在上文<Spark技术内幕:Stage划分及提交源码分析>中,我们分析了Stage的生成和提交.但是Stage的提交,只是DAGScheduler完成了对DAG的划分,生成了一个计算拓扑, ...
随机推荐
- Tomcat version 7.0 only support J2EE 1.2。。。。。。。
刚开始使用eclipse编程,换了eclipse版本后导入项目,出现下的报错
- git format-patch & git apply & git clean
一.打补丁 git format-patch & git apply 最近在工作中遇到打补丁的需求,一来觉得直接传文件有些low(而且我尝试了一下,差点把项目代码毁了) ,二来也是想学习一下, ...
- web安全之sqlload_file()和into outfile()
load_file() 条件:要有file_priv权限 知道文件的绝对路径 能使用union 对web目录有读权限 如果过滤啦单引号,则可以将函数中的字符进行hex编码 步骤: 1.读/etc/in ...
- google.GIS小例子
var map; var array = [[41.774166667, 85.943055556], [43.864052, 87.560499]];//经纬度 var array1 = [&quo ...
- Joomla及其类似软件的说明分析
Joomla不单单是一款免费的软件,还是在国外相当知名的及内容管理.web开发及手机应用开发等为一体的一套系统.Joomla是使用PHP语言加上MySQL数据库所开发的软件系统,可以在Linux. W ...
- DLL编程学习
原文出处:http://www.blogjava.net/wxb_nudt/archive/2007/09/11/144371.html DLL编写教程 半年不能上网,最近网络终于通了,终于可以更新博 ...
- JSTL配置
1.下载jakarta-taglibs-standard-1.1.2.zip(在Weblogic中必须下载1.0版http://jakarta.apache.org/site/downloads/do ...
- Roslyn 学习笔记(二)
参考:https://github.com/dotnet/roslyn/wiki/Getting-Started-C%23-Syntax-Analysis 语法分析过程主要用到以下类或结构: Synt ...
- Geolocation API 原理及方法
使用IP地址:基于Web的数据库:无线网络连接定位:三角测量:GPS技术:来测量经度和纬度.(综合了所有技术)地理定位的精确度,有很多方法可以定位用户的地理位置,并且每种方法都有不同的精度.桌面浏览器 ...
- C的文件操作2
[转] C语言文件操作 概述 所谓文件(file)一般指存储在外部介质上数据的集合,比如我们经常使用的mp3.mp4.txt.bmp.jpg.exe.rmvb等等.这些文件各有各的用途,我们通常将它 ...