golang实现并发爬虫二(简单调度器)
那么这篇文章就大概说下,如何在上一个版本中进行升级改造,使之成为一个多任务版本的爬虫。加快我们爬取的速度。
话不多说,先看图:
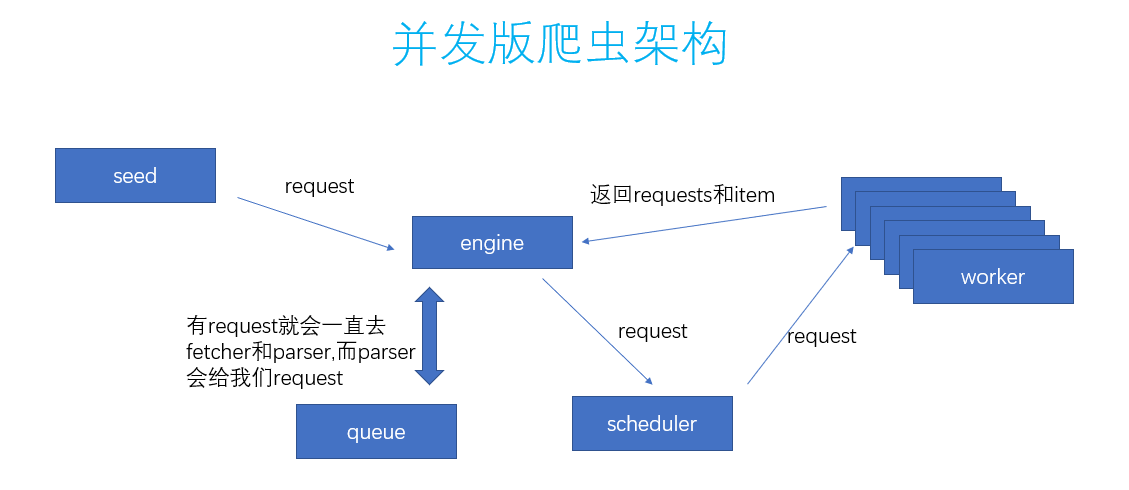
其实呢,实现方法就是加了一个scheduler的模块,所有的request都由scheduler去交给worker。
另外呢,这里的worker,也就是上文提到过的fetcher和parser的一个过程。
worker的数量由我们自己在调用engine的时候传入。
每一个worker都是一个groutine。这样可以加快抓取速度,尤其是fetcher那块的。代码如下:
func createWorker(in chan Request, out chan ParseResult) {
go func() {
for {
request := <-in
res, err := Worker(request)
if err != nil {
continue
}
out <- res
}
}()
}
这里的关键呢,就在于scheduler如何分配。
第一种方案是来一个request就给到workChan。
func (s *SimpleScheduler) Submit(r simple_con_engine.Request) {
s.workChan <- r
}
但是,这种方案是不行的。
因为worker的速度太快,而这个给到workChan的速度太慢,会导致卡死。
那么,解决办法可以是每来一个request就都开一个groutine,就可以解决这个事情了。代码也就是这样了:
func (s *SimpleScheduler) Submit(r simple_con_engine.Request) {
go func() { s.workChan <- r }()
}
scheduler做的事情也就是这样了:
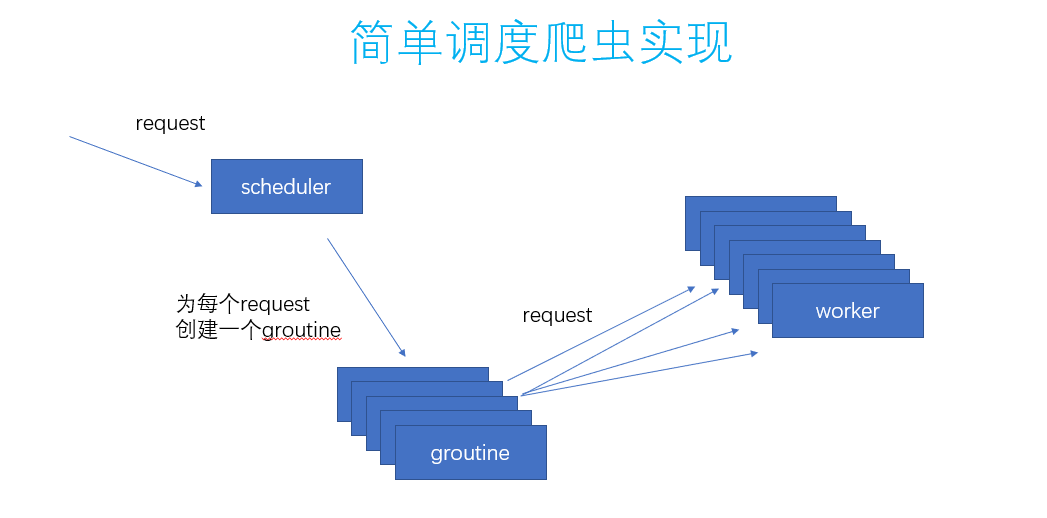
这个就可以并发的去执行爬虫的任务了,通过这个scheduler的调度。
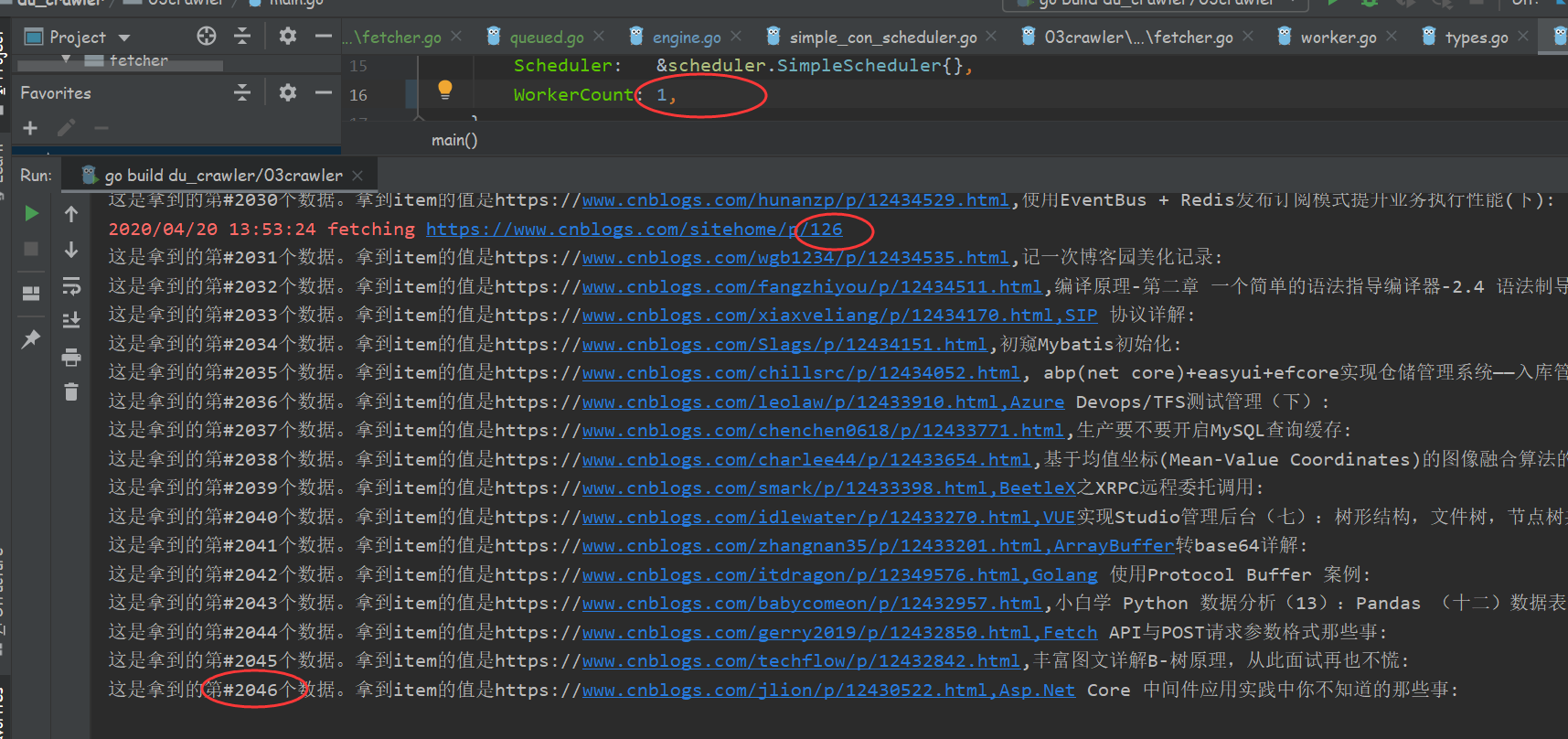
经测当workerCount为1时,其实也就相当于是单任务版爬虫为30秒爬取了2046条数据。
当workerCount为10时,这个使用了简单调度器的爬虫为30秒爬取了条数据,实际效率不止增加了10倍。

这个使用scheduler去实现简单调度器的并发版爬虫的源码可有:
有。
https://github.com/anmutu/du_crawler/tree/master/03crawler
那么,这个多任务版本的爬虫有什么缺点吗:
有。
当engine给到scheduler的每一个request的时候就会创建一个groutine,这个避免dead lock,但是就会创建无数个groutine,我们的控制力度就小了好多。
golang实现并发爬虫二(简单调度器)的更多相关文章
- golang实现并发爬虫三(用队列调度器实现)
欲看此文,必先可先看: golang实现并发爬虫一(单任务版本爬虫功能) gollang实现并发爬虫二(简单调度器) 上文中的用简单的调度器实现了并发爬虫. 并且,也提到了这种并发爬虫的实现可以提高爬 ...
- golang中GPM模型原理与调度器设计策略
一.GMP模型原理first: 1. 全局队列:存放待运行的G2. P的本地队列:同全局队列类似,存放待运行的G,存储的数量有限:256个,当创建新的G'时,G'优先加入到P的本地队列,如果队列已满, ...
- golang实现并发爬虫一(单任务版本爬虫功能)
目的是写一个golang并发爬虫版本的演化过程. 那么在演化之前,当然是先跑通一下单任务版本的架构. 正如人走路之前是一定要学会爬走一般. 首先看一下单任务版本的爬虫架构,如下: 这是单任务版本爬虫的 ...
- golang版并发爬虫
准备爬取内涵段子的几则笑话,先查看网址:http://www.budejie.com/text/ 简单分析后发现每页的url呈加1趋势 第一页: http://www.budejie.com/text ...
- python简单爬虫(二)
上一篇简单的实现了获取url返回的内容,在这一篇就要第返回的内容进行提取,并将结果保存到html中. 一 . 需求: 抓取主页面:百度百科Python词条 https://baike.baidu. ...
- golang的并发
Golang的并发涉及二个概念: goroutine channel goroutine由关键字go创建. channel由关键字chan定义 channel的理解稍难点, 最简单地, 你把它当成Un ...
- scrapy 基础组件专题(七):scrapy 调度器、调度器中间件、自定义调度器
一.调度器 配置 SCHEDULER = 'scrapy.core.scheduler.Scheduler' #表示scrapy包下core文件夹scheduler文件Scheduler类# 可以通过 ...
- 第十四章 kubernetes 核心技术-调度器
一.概述 一个容器平台的主要功能就是为容器分配运行时所需要的计算,存储和网络资源.容器调 度系统负责选择在最合适的主机上启动容器,并且将它们关联起来.它必须能够自动的处 理容器故障并且能够在更多的主机 ...
- YARN的capacity调度器主要配置分析
yarn中一个基本的调度单元是队列. yarn的内置调度器: 1.FIFO先进先出,一个的简单调度器,适合低负载集群.2.Capacity调度器,给不同队列(即用户或用户组)分配一个预期最小容量,在每 ...
随机推荐
- Springboot学习笔记【持续更新】
1.Springboot四大核心: 自动配置 与Spring应用程序和常见的应用功能,Springboot能自动提供相关配置 起步依赖 告诉Springboot需要什么功能,它就能引入需要的依赖库 A ...
- python之道14
看代码写结果: def wrapper(f): def inner(*args,**kwargs): print(111) ret = f(*args,**kwargs) print(222) ret ...
- Kannada-MNIST:一个新的手写数字数据集
TLDR: 我正在传播2个数据集: Kannada-MNIST数据集:28x28灰度图像:60k 训练集 | 10k测试集 Dig-MNIST:28x28灰度图像:10240(1024x10)(见下图 ...
- PHP7内核(六):变量之zval
记得网上流传甚广的段子"PHP是世界上最好的语言",暂且不去讨论是否言过其实,但至少PHP确实有独特优势的,比如它的弱类型,即只需要$符号即可声明变量,使得PHP入手门槛极低,成为 ...
- PHP7内核(五):系统分析生命周期
上篇文章讲述了模块初始化阶段之前的准备工作,本篇我来详细介绍PHP生命周期的五个阶段. 一.模块初始化阶段 我们先来看一下该阶段的每个函数的作用. 1.1.sapi_initialize_reques ...
- coding++:拦截器拦截requestbody数据如何防止流被读取后数据丢失
1):现在开发的项目是基于SpringBoot的maven项目,拦截器的使用很多时候是必不可少的,当有需要需要你对body中的值进行校验,例如加密验签.防重复提交.内容校验等等. 2):当你开开心心的 ...
- coding++:java-自定义签名+拦截器
本次案例工具为:SpringBoot <version>1.5.19.RELEASE</version> Code: 1.annotations package com.m ...
- 2020年Java多线程与并发系列22道高频面试题(附思维导图和答案解析)
前言 现在不管是大公司还是小公司,去面试都会问到多线程与并发编程的知识,大家面试的时候这方面的知识一定要提前做好储备. 关于多线程与并发的知识总结了一个思维导图,分享给大家 1.Java中实现多线程有 ...
- SciPy - 正态性 与 KS 检验
假设检验的基本思想 若对总体的某个假设是真实的,那么不利于或者不能支持这一假设的事件A在一次试验中是几乎不可能发生的:如果事件A真的发生了,则有理由怀疑这一假设的真实性,从而拒绝该假设: 假设检验实质 ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...