【爬虫综合作业】猫眼电影TOP100分析
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
一.爬虫对象
猫眼电影TOP100排行榜
二.代码如下
import requests
import re,json
from lxml import etree
import csv class Spider():
def open_csv(self):
'''
在CSV文件的开头写一行标题
:return:
'''
with open('data.csv', 'a', newline='', encoding='utf-8') as f:
spamwriter = csv.writer(f)
spamwriter.writerow(['名称', '主演', '上映时间', '评分']) def __get_page(self,url,headers):
'''
获取文本内容
:param url:
:param headers:
:return:
'''
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except Exception:
return None def __parse_page(self,html):
'''
解析HTML,并得到提取的数据
:param html:
:return:
'''
data = etree.HTML(html) results = data.xpath('//*[@class="board-wrapper"]/dd/div/div')
for result in results:
# 电影名称 电影主演 电影上映日期 评分
ws = [
result.xpath('./div[1]/p[1]/a/text()')[0],
result.xpath('./div[1]/p[2]/text()')[0].strip(),
result.xpath('./div[1]/p[3]/text()')[0],
result.xpath('./div[2]/p/i[1]/text()')[0] + result.xpath('./div[2]/p/i[2]/text()')[0],
] #保存到CSV
with open('data.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(ws) def run(self):
'''
程序运行入口
:return:
'''
self.open_csv() for i in range(11):
url ='http://maoyan.com/board/4?offset={}'.format(10*i)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)'
' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
html = self.__get_page(url,headers)
self.__parse_page(html) #实例化类
spider = Spider()
spider.run()
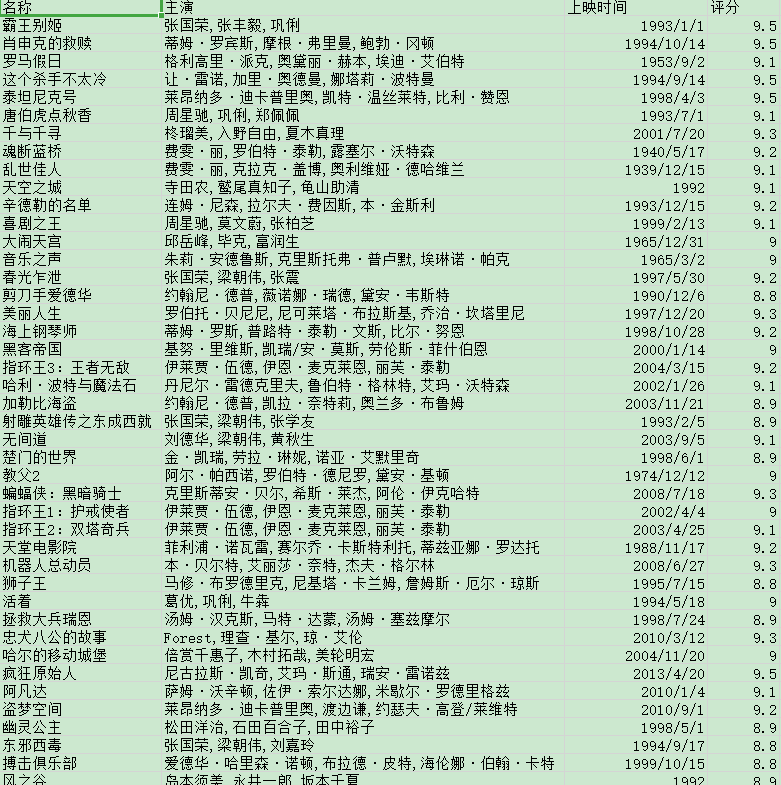
三.运行结果

四.数据分析
(1)电影评分比例
一部电影质量由评分能直接体现出来,而总体评分分布能体现出播放器的质量。
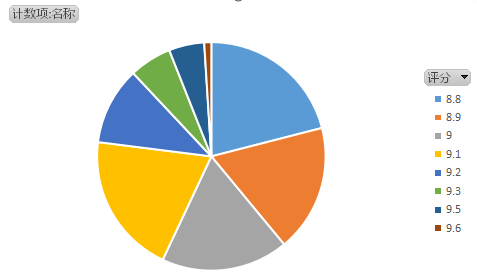
由上图看出8.8-9.1分数的电影比较多,所以猫眼电影的质量还是可以的。
(2)电影的成功除了质量之外,发布的时间也是很重要的。
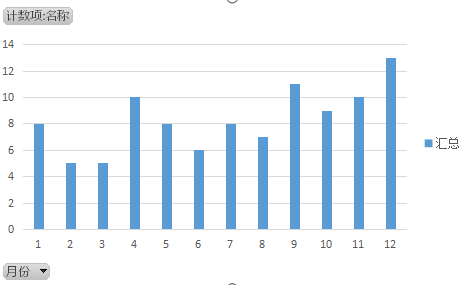
大家看电影都知道,电影基本在假期上映更有热度,这里统计出来,发现下半年的电影比上半年电影好很多。
(3)通过数据透视表可以看出,在猫眼电影TOP100排行榜中,有一部由周星驰主演的《大话西游之月光宝盒》评分远远超过其他的电影,看来星爷的经典难以被超越

【爬虫综合作业】猫眼电影TOP100分析的更多相关文章
- python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests.BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名.图片.名称.演 ...
- <scrapy爬虫>爬取猫眼电影top100详细信息
1.创建scrapy项目 dos窗口输入: scrapy startproject maoyan cd maoyan 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # -*- ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- Python爬虫之requests+正则表达式抓取猫眼电影top100以及瓜子二手网二手车信息(四)
requests+正则表达式抓取猫眼电影top100 一.首先我们先分析下网页结构 可以看到第一页的URL和第二页的URL的区别在于offset的值,第一页为0,第二页为10,以此类推. 二.< ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- 爬虫练习之正则表达式爬取猫眼电影Top100
#猫眼电影Top100import requests,re,timedef get_one_page(url): headers={ 'User-Agent':'Mozilla/5.0 (Window ...
随机推荐
- 菜鸟python之路-第五章(记录读书点滴)
数字 1.数字类型 python支持多种数字类型:整型.长整型.布尔型.双精度浮点型.十进制浮点型和复数 . 创建数值对象并赋值 aint=1 along=-999999999999999L aflo ...
- 移动端设备中1px适配
方式1:伪类+transform实现,主要用transform中的scale缩放,缩放默认中心点是以x,y轴的50%处,因此需要用transform-origin调整中心点 html代码: <d ...
- DeepCTR专题:Neural Factorization Machines 论文学习和实现及感悟
papers地址:https://arxiv.org/pdf/1708.05027.pdf 借用论文开头,目前很多的算法任务都是需要使用category feature,而一般对于category f ...
- redis 脑裂等极端情况分析
脑裂真的是一个很头疼的问题(ps: 脑袋都裂开了,能不疼吗?),看下面的图: 一.哨兵(sentinel)模式下的脑裂 如上图,1个master与3个slave组成的哨兵模式(哨兵独立部署于其它机器) ...
- Datediff的使用(统计本日,昨日,本周,本月)
//统计本日,昨日,本周,本月添加的产品总数 //日期 DateTime DT = DateTime.Now; string day=DT.Date.ToS ...
- 忽略SIGPIPE信号
#include <stdlib.h> #include <sys/signal.h> void SetupSignal() { struct sigaction sa; // ...
- .Net memory management Learning Notes
Managed Heaps In general it can be categorized into 1) SOH and 2) LOH. size lower than 85K will be ...
- docker中的oracle-11g-安装配置
docker镜像:wnameless/oracle-xe-11g 启动镜像的命令: docker run -d -v /data/oracle_data:/data/oracle_data -p 11 ...
- springcould 微服务 搭建
摘自:https://www.cnblogs.com/lori/p/10615654.html (完整) springcloud~服务注册与发现Eureka的使用 服务注册与发现是微服务里的 ...
- Codeforces1100F. Ivan and Burgers(离线+线性基)
题目链接:传送门 思路: 按查询的右端点离线. 然后从左到右维护线性基. 每个基底更新为最右边的方案,可以让尽量多的查询享受到这个基底. 用ci维护后更新右端点为i的答案. 代码(析构1000ms,别 ...