Filebeat+ELK部署文档
在日常运维工作中,对于系统和业务日志的处理尤为重要。今天,在这里分享一下自己部署的Filebeat+ELK开源实时日志分析平台的记录过程,有不对的地方还望指出。
简单介绍:
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
Filebeat+ELK是四个开源工具组成,简单解释如下:
Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch 进行集中式存储和分析。
Elasticsearch:是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash:是一个完全开源的工具,它可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
Kibana:也是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
这里之所以用Filebeat+ELK是因为Filebeat相对于logstash而言,更轻量级,占用系统资源少。
实验拓扑图
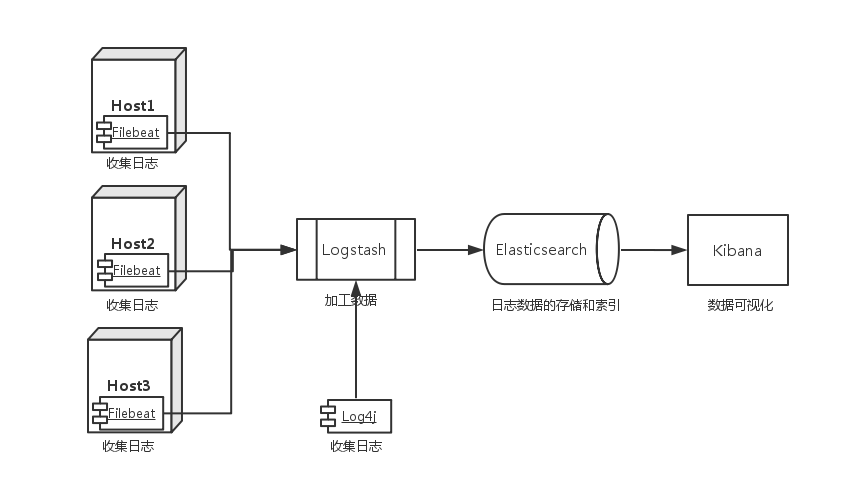
环境信息:
| 操作系统 | ip地址 | 软件 |
| centos6.9 | 10.104.34.101 | filebeat6.2.4 |
| centos6.8 | 10.135.67.165 | Logstash6.2.4 |
| centos6.8 | 10.135.67.165 | Elasticsearch6.2.4 |
| centos6.8 | 10.135.173.165 | Kibana6.2.4 |
我这里把elasticsearch和logstash部署在同一台服务器上了。
安装步骤:
1、配置Java环境:(安装elasticsearch的时候需要有Java环境,jdk可以去oracle官方网站下载,版本号可以和我的不一样)
#rpm -ivh jdk-8u102-linux-x64.rpm

2、安装elasticsearch:
#wget -P /usr/local/src/ https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
#cd /usr/local/src
#tar xvf elasticsearch-6.2..tar.gz
#cp elasticsearch-6.2./config/elasticsearch.yml elasticsearch-6.2.4/config/elasticsearch.yml.default --备份elasticsearch的默认配置文件,以防止修改时出错

bootstrap.memory_lock: false
bootstrap.system_call_filter: false
这两行配置主要是为了解决之后启动elasticsearch会报检测失败的一个错,报错内容如下:
system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
原因:这是在因为Centos6不支持SecComp,而ES5.2.0版本之后默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。
添加elastic用户,tar包启动必须使用普通用户运行
#useradd elastic
#chown -R elastic. /usr/local/src/elasticsearch-6.2.
打开sysctl.conf文件,添加如下内容:
#vim /etc/sysctl.conf
vm.max_map_count =
#sysctl -p /etc/sysctl.conf
打开/etc/security/limits.conf文件,修改打开文件句柄数
#vim /etc/security/limits.conf --添加如下内容
* soft nofile
* hard nofile
* soft nproc
* hard nproc
切换到elastic普通用户
#su - elastic
$cd /usr/local/src/elasticsearch-6.2.4
$./bin/elasticsearch
第一次启动需要一些时间,因为需要做一些初始化动作,如果没启动成功请查系elasticsearch的相关日志解决。注意上面只是前台启动调试,在后台需要加&,需要重新启动。
查看端口是否开启:
curl简单的测试下:

3、安装logstash
#wget -P /usr/local/src https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz
#cd /usr/local/src/
#tar xvf logstash-6.2..tar.gz
4、安装filebeat
#wget -P /usr/local/src https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-linux-x86_64.tar.gz
#cd /usr/local/src
#tar xvf filebeat-6.2.-linux-x86_64.tar.gz
#cp /usr/local/src/filebeat-6.2./filebeat.yml /usr/local/src/filebeat-6.2./filebeat.yml.default
编辑filebeat.yml文件,内容如下:

启动filebeat服务:
#cd /usr/local/src/filebeat-6.2.
#./filebeat & --在后台运行
注意:filebeat没有监听端口,主要看日志和进程,filebeat监听的文件记录信息在/usr/local/src/filebeat-6.2.4/data/registry里面

然后新建一个logstash启动指定logstash.conf的配置文件,内容如下:
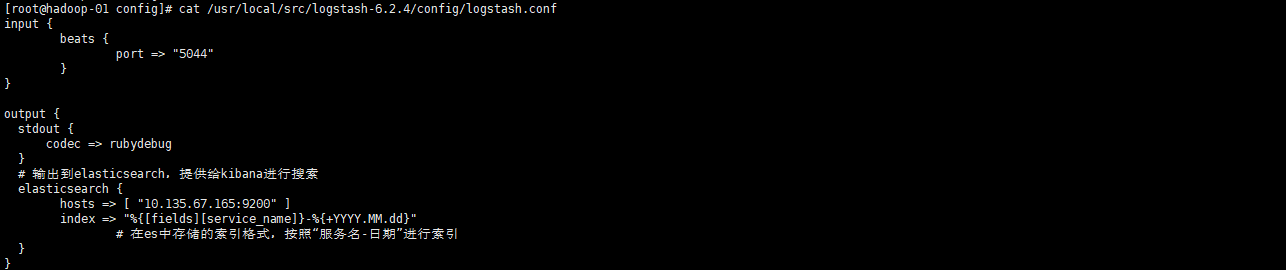
这里我们只配置了input和output部分,其实Logstash默认有input、filter、output三个区域,但一般至少配置input和output部分就够了,并且logstash的默认配置文件logstash.yml我们选择不修改就行。
下面我们启动logstash,然后进行先进行简单的测试:
#cd /usr/local/src/logstash-6.2.
#./bin/logstash -e 'input { stdin { } } output { stdout { } }' --先进行不指定配置文件测试
当我们输入hello world的时候,对应的下面也会输出

接下来指定配置文件logstash.conf进行测试:
#cd /usr/local/src/logstash-6.2.
#./bin/logstash -f config/logstash.conf --这里我们先前台启动方便调试,待调试成功后再后台启动

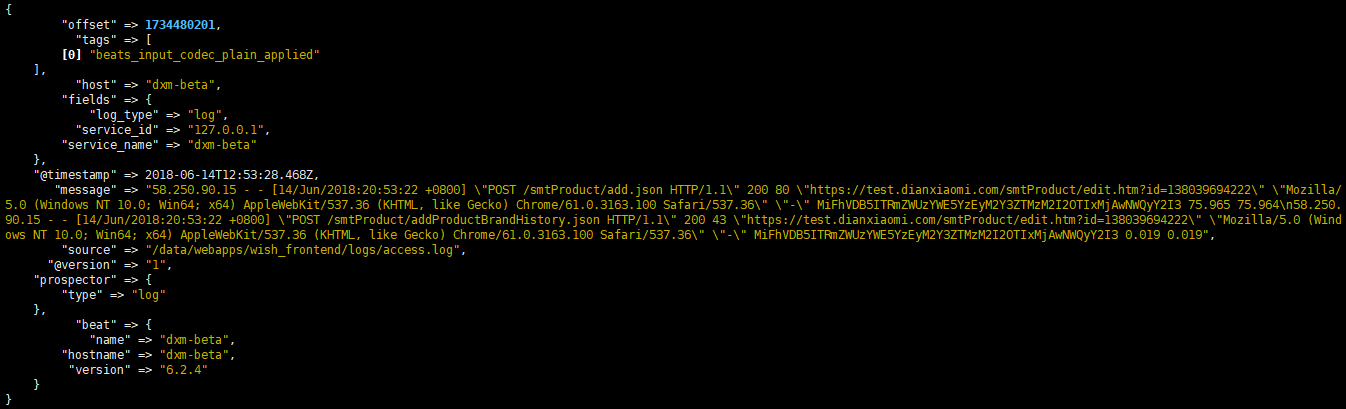
这个启动完一会后会输出如下数据,这些数据就是filebeat从access.log里采集过来的日志,其实这些数据也输入到了elasticsearch当中,可以用curl http://ip:9200/_search?pretty
进行验证(ip为elasticsearch的ip)
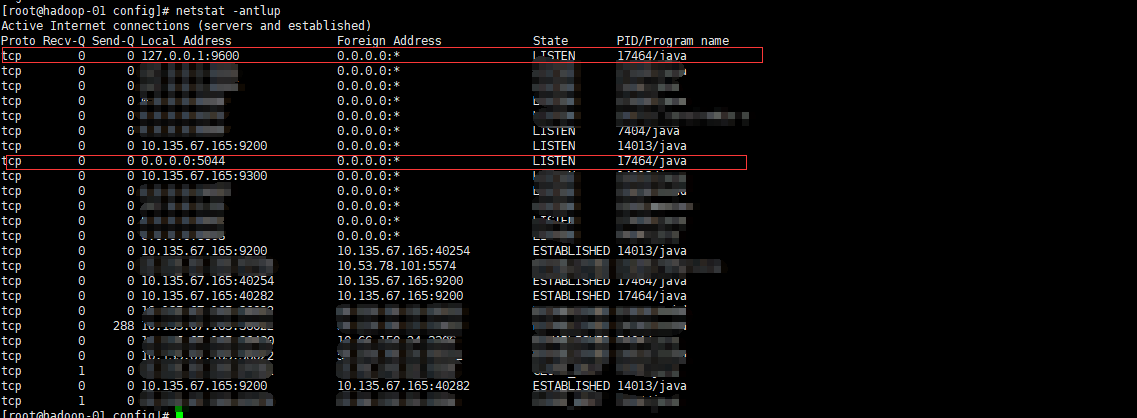
当然我们也可以看到对应的端口9600和5044是开启的
5、安装kibana
#wget -P /usr/local/src https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
#cd /usr/local/src
#tar xvf kibana-6.2.-linux-x86_64.tar.gz
#cp kibana-6.2.-linux-x86_64/config/kibana.yml kibana-6.2.-linux-x86_64/config/kibana.yml.default
编辑kibana的配置文件

这里server.host理论上来说配置成本服务器的外网ip即可,但是我用的云服务器,配置成相应的外网ip在启动的时候会报无法分配对应的ip地址,至于是什么原因我也没搞明白,但是配置成0.0.0.0后就可
以正常启动。

打开浏览器输入:http://ip:5601(ip为kibana的外网ip地址)

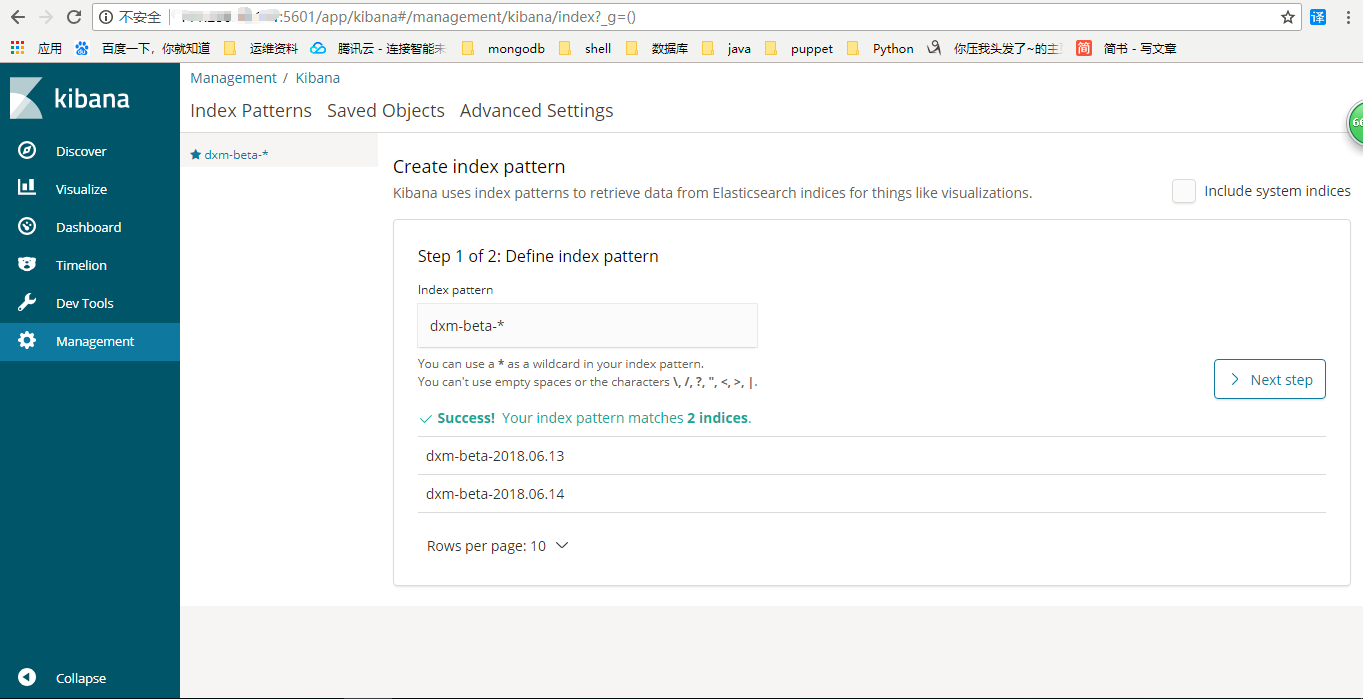
进来之后首先创建一个索引,然后输入Time Filter field name名字,均填完之后点击创建。
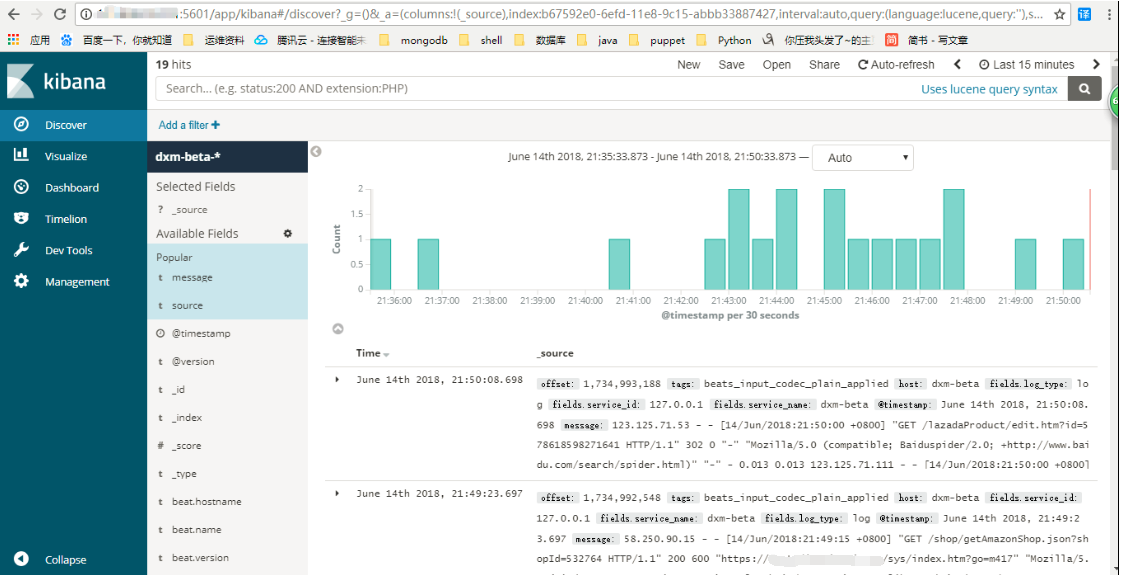
点击Discover可以看到采集的日志已经到kibana这里来了,至此,filebeat+elk日志分析系统就搭建完了,还有许多高级功能需不断学习。
Filebeat+ELK部署文档的更多相关文章
- ELK 部署文档
1. 前言 在日常运维工作中,对于系统和业务日志的处理尤为重要.尤其是分布式架构,每个服务都会有很多节点,如果要手工一个一个的去取日志,运维怕是要累死. 简单介绍: ELK 是 elasticsear ...
- PPTP部署文档
PPTP部署文档 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 欢迎加入:高级运维工程师之路 598432640 前言:这款VPN部署起来特别简单,想对OPENVON配 ...
- hadoop2.6.0汇总:新增功能最新编译 32位、64位安装、源码包、API下载及部署文档
相关内容: hadoop2.5.2汇总:新增功能最新编译 32位.64位安装.源码包.API.eclipse插件下载Hadoop2.5 Eclipse插件制作.连接集群视频.及hadoop-eclip ...
- supervisor 部署文档
supervisor 部署文档 supervisor 需要Python支持,如果不用系统的supervisor,单独安装python python 安装 #依赖 yum install python- ...
- centos6 Cacti部署文档
centos6 Cacti部署文档 1.安装依赖 yum -y install mysql mysql-server mysql-devel httpd php php-pdo php-snmp ph ...
- HP DL160 Gen9服务器集群部署文档
HP DL160 Gen9服务器集群部署文档 硬件配置=======================================================Server Memo ...
- Sqlserver2008安装部署文档
Sqlserver2008部署文档 注意事项: 如果你要安装的是64位的服务器,并且是新机器.那么请注意,你需要首先需要给64系统安装一个.net framework,如果已经安装此功能,请略过这一步 ...
- CDH简易离线部署文档
CDH 离线简易部署文档 文档说明 本文为开发部署文档,生产环境需做相应调整. 以下操作尽量在root用户下操作,避免权限问题. 目录 文档说明 2 文档修改历史记录 2 目录 3 ...
- Ceph分布式存储(luminous)部署文档-ubuntu18-04
Ceph分布式存储(luminous)部署文档 环境 ubuntu18.04 ceph version 12.2.7 luminous (stable) 三节点 配置如下 node1:1U,1G me ...
随机推荐
- sizeof和strlen()区别及用法
//sizeof是以字节为单位计算变量或类型所占内存大小,它是属于C语言运算符系列:而strlen()是一个函数,是计算字符串长度(也是以字节为单位,但略有区别):比如: char array[] = ...
- 面向对象_del
老师的博客http://www.cnblogs.com/Eva-J/articles/7351812.html#_label7 内置的方法有很多不一定全都在object中 #python3中,所有类都 ...
- 多线程中的event,用于多线程的协调
''' 简单的需求:红绿灯,红灯停,绿灯行 一个线程扮演红绿灯,每过一段时间灯变化,3-5个线程扮演车,红灯停,绿灯行 红绿灯线程和车的线程会相互依赖 这种场景怎么实现?---事件 切换一次灯就是一次 ...
- python 结巴分词学习
结巴分词(自然语言处理之中文分词器) jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于 ...
- Java的动态代理
什么是动态代理(dynamic proxy) 动态代理(以下称代理),利用Java的反射技术(Java Reflection),在运行时创建一个实现某些给定接口的新类(也称“动态代理类”)及其实例(对 ...
- CSS伪元素:before/CSS伪元素:before/:after content 显示Font Awesome字体图标:after content 显示Font Awesome字体图标
HTML <a href="javascript:volid(0);"><i class="icon-table"></i> ...
- 正益移动推出新产品正益工作 实现PaaS+SaaS新组合
近期,正益移动不仅将其AppCan 移动平台云化,还通过发布全新 SaaS 产品 -- 正益工作,这款集合了企业信息聚合.应用聚合.社交聚合为一体的企业移动综合门户,与 AppCan 平台一起实现了P ...
- flask刷新token
我们在做前后端分离的项目中,最常用的都是使用token认证. 登录后将用户信息,过期时间以及私钥一起加密生成token,但是比较头疼的就是token过期刷新的问题,因为用户在登录后,如果在使用过程中, ...
- mybatis 中 foreach collection的三种用法
foreach的主要用在构建in条件中,它可以在SQL语句中进行迭代一个集合. foreach元素的属性主要有 item,index,collection,open,separator,close. ...
- Electron桌面应用打包流程
一. 准备工作 1.npm的安装需要下载node.js,安装完node.js之后npm自然会有. 参考链接:http://www.runoob.com/nodejs/nodejs-install-se ...