pandas 读mysql数据库(整个表或者表的指定列)
问题1:如何从数据库中读取整个表数据到DataFrame中?
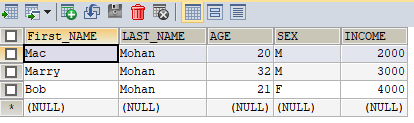
首先,来看很容易想到的的办法
def read_table_by_name(self, table_name):
"""
读取table_name表
:return: dataframe对象 所有的评价对象及其数据
"""
field_list = [] # target表的所有字段的列表
field_data = [] # 存放某一字段的所有数据
frame_data = pd.DataFrame() self._cursor = self._connect.cursor()
sql = "select COLUMN_NAME from information_schema.COLUMNS where table_name = '%s'"
self._cursor.execute(sql % table_name)
results = self._cursor.fetchall()
for row in results:
field_list.append(row[0]) name_sql = "select %s from %s"
i = 0
for field in field_list:
self._cursor.execute(name_sql % (field, table_name))
column_data = self._cursor.fetchall()
field_data.clear()
for j in range(len(column_data)):
field_data.append(column_data[j][0])
frame_data.insert(i, field, field_data) # frame_data 插入数据 i += 1 return frame_data
看起来,十分麻烦。那么有没有简单的办法呢?当然有,目前我已知的有以下几种:
1:使用pandas.io.sql模块中sql.read_sql_table(table_name,conn)直接将一个table转到dataframe中
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
result = pd.io.sql.read_sql_table('employee', engine)
print(type(result), '\n', result)
注意:read_sql_table 仅支持 SQLAlchemy 连接
输出结果如下:

2:使用pandas.io.sql模块中的sql.read_sql_query(sql_str,conn)或者sql.read_sql(sql_str,conn),效果相同,都使用sql语句
import pandas as pd
import pymysql
from sqlalchemy import create_engine
# conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='test')
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
sql_str = 'select * from employee'
result = pd.io.sql.read_sql_query(sql_str, engine)
print(type(result), '\n', result)
import pandas as pd
import pymysql
from sqlalchemy import create_engine
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='test')
# engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
sql_str = 'select * from employee'
result = pd.io.sql.read_sql_query(sql_str, conn)
print(type(result), '\n', result)
注意:read_sql_query 不仅支持 SQLAlchemy 连接,pymysql也可以
问题2:如何从数据库中读取表的指定列的数据到DataFrame中?
先来看比较容易想到的办法:
def read_indexs_by_index(self, table_name, index_list):
"""
根据选择的指标名列表读取table_name表
:param self:
:param table_name: 表名
:param index_list: 指定列的列表
:return:
"""
index_data = []
frame_data = pd.DataFrame()
sql = "select %s from %s"
i = 0
for index in index_list:
self._cursor.execute(sql % (index, table_name))
column_data = self._cursor.fetchall()
index_data.clear()
for j in range(len(column_data)):
index_data.append(float(column_data[j][0]))
frame_data.insert(i, index, index_data) # frame_data 插入数据
i += 1 return frame_data
再看使用使用 pd.io.sql.read_sql_query模块的方法:
def read_indexs_by_index(self, table_name, index_list):
"""
根据选择的指标名列表读取table_name表
:param self:
:param table_name:
:param index_list:
:return:
"""
sql = "select * from %s"
df = pd.io.sql.read_sql_query((sql % table_name), self._connect) data_frame = df.loc[list(range(0, df.shape[0])), index_list] # df.loc[:,index_list]也可以 return data_frame
只需要四行
pandas 读mysql数据库(整个表或者表的指定列)的更多相关文章
- mysql数据库为什么要分表和分区?
一般下载的源码都带了MySQL数据库的,做个真正意义上的网站没数据库肯定不行. 数据库主要存放用户信息(注册用户名密码,分组,等级等),配置信息(管理权限配置,模板配置等),内容链接(html ,图片 ...
- Hibernate连接mysql数据库并自动创建表
天才第一步,雀氏纸尿裤,Hibernate第一步,连接数据库. Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个 ...
- MYSQL数据库、用户、表等基础构建
MYSQL数据库.用户.表等基础构建: 1.->:创建数据库: 1.1. create schema [数据库名称] default character set utf8 collate utf ...
- MySQL数据库性能优化:表、索引、SQL等
一.MySQL 数据库性能优化之SQL优化 注:这篇文章是以 MySQL 为背景,很多内容同时适用于其他关系型数据库,需要有一些索引知识为基础 优化目标 减少 IO 次数IO永远是数据库最容易瓶颈的地 ...
- 关于php读mysql数据库时出现乱码的解决方法
关于php读mysql数据库时出现乱码的解决方法 php读mysql时,有以下几个地方涉及到了字符集. 1.建立数据库表时指定数据库表的字符集.例如 create table tablename ( ...
- 使用jdbc将mysql数据库中的内容封装为指定对象的list集合
使用jdbc将mysql数据库中的内容封装为指定对象的list集合 public List<User> findAll() { private JdbcTemplate template ...
- mysql数据库分区和分表
转载自 https://www.cnblogs.com/miketwais/articles/mysql_partition.html https://blog.csdn.net/vbirdbest/ ...
- 检查mysql数据库是否存在坏表脚本
#!/bin/bash #此脚本的主要用途是检测mysql服务器上所有的db或者单独db中的坏表 #变量说明 pass mysql账户口令 name mysql账号名称 data_path mysql ...
- MySql数据库中,判断表、表字段是否存在,不存在就新增
本文是针对MySql数据库创建的SQL脚本,别搞错咯. 判断表是否存在,不存在就可新增 CREATE TABLE IF NOT EXISTS `mem_cardtype_resource` ( ... ...
随机推荐
- BZOJ 5099: Pionek(双指针)(占位)
pro:有N个向量,你可以选择一些向量,使得其向量和离原点最远. 输出这个欧几里得距离的平方. sol:(感觉网上的证明都不是很充分,我自己也是半信半疑吧)日后证明了再补. #include<b ...
- POJ - 1474 :Video Surveillance (半平面交-求核)
pro:顺时针给定多边形,问是否可以放一个监控,可以监控到所有地方,即问是否存在多边形的核. 此题如果两点在同一边界上(且没有被隔段),也可以相互看到. sol:求多边形是否有核.先给直线按角度排序, ...
- HDU2044:一只小蜜蜂...
题目贴不上了︿( ̄︶ ̄)︿http://acm.hdu.edu.cn/showproblem.php?pid=2044 注意数据类型,用int会超范围 #include<stdio.h> ...
- n!的质因子分解
其中k为任意质因子,因为a的数值不确定,所有k的值可以任意选择. 以下代码用于求出m!: #include<bits/stdc++.h> LL getpow(LL n,LL k) { LL ...
- c# 敏捷2 ForEach ToDictionary ToLookup Except比较
using System; using System.Collections; using System.Collections.Generic; using System.Diagnostics; ...
- C++学习(五)(C语言部分)之 运算符
运算符学习时的笔记(其实也没什么用,留着给自己看的) 运算符 用来对数据运算的符号 优先级 3+4*5+6 先乘除 然后加减 运算符优先级高就先算 40多个运算符 15层优先级 不需要背 1.查表 2 ...
- dijksta 模板
#include<bits/stdc++.h> using namespace std; #define INF 0x3f3f3f3f ]; ]; ][]; void dijkstra(i ...
- 简单的Windows应用程序命名规则
读书:<高质量C++编程指南> 作者对“匈牙利”命名规则做了合理的简化,下述的命名规则简单易用,比较适合于Windows应用软件的开发. l [规则3-2-1]类名和函数名用大写字母开头的 ...
- 学习笔记TF014:卷积层、激活函数、池化层、归一化层、高级层
CNN神经网络架构至少包含一个卷积层 (tf.nn.conv2d).单层CNN检测边缘.图像识别分类,使用不同层类型支持卷积层,减少过拟合,加速训练过程,降低内存占用率. TensorFlow加速所有 ...
- python数据类型及字符编码
一.python数据类型,按特征划分 1.数字类型 整型:布尔型(True,False).长整型(L),会自动帮你转换成长整型.标准整型 2.序列类型 字符串(str).元组(tuple).列表(li ...