[转]ConcurrentHashMap原理分析
一、背景:
线程不安全的HashMap
效率低下的HashTable容器
分段锁技术
二、应用场景
三、源码解读
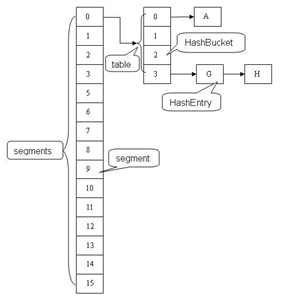
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
不变(Immutable)和易变(Volatile)
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
其它
定位操作:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
数据结构
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* The number of elements in this segment's region.
*/
transient volatileint count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
}
删除操作remove(key)
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}


get操作
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- 是否需要扩容。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
- 如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
}
size()操作
参考文章:http://www.cnblogs.com/ITtangtang/p/3948786.html
[转]ConcurrentHashMap原理分析的更多相关文章
- ConcurrentHashMap原理分析(1.7与1.8)-put和 get 需要执行两次Hash
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Seg ...
- [转载] ConcurrentHashMap原理分析
转载自http://blog.csdn.net/liuzhengkang/article/details/2916620 集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的 ...
- Java集合:ConcurrentHashMap原理分析
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章主 ...
- 【Java并发编程】1、ConcurrentHashMap原理分析
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章主 ...
- Java 中 ConcurrentHashMap 原理分析
一.Java并发基础 当一个对象或变量可以被多个线程共享的时候,就有可能使得程序的逻辑出现问题. 在一个对象中有一个变量i=0,有两个线程A,B都想对i加1,这个时候便有问题显现出来,关键就是对i加1 ...
- ConcurrentHashMap原理分析(二)-扩容
概述 在上一篇文章中介绍了ConcurrentHashMap的存储结构,以及put和get方法,那本篇文章就介绍一下其扩容原理.其实说到扩容,无非就是新建一个数组,然后把旧的数组中的数据拷贝到新的数组 ...
- ConcurrentHashMap原理分析
当我们享受着jdk带来的便利时同样承受它带来的不幸恶果.通过分析Hashtable就知道,synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,安全的背后是巨大的浪费,而现在的解 ...
- ConcurrentHashMap 原理分析
1 为什么有ConcurrentHashMap hashmap是非线程安全的,hashtable是线程安全的,但是所有的写和读方法都有synchronized,所以同一时间只有一个线程可以持有对象,多 ...
- ConcurrentHashMap原理分析(1.7与1.8)
前言 以前写过介绍HashMap的文章,文中提到过HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新 ...
- 【转】ConcurrentHashMap原理分析(1.7与1.8)
https://www.cnblogs.com/study-everyday/p/6430462.html 前言 以前写过介绍HashMap的文章,文中提到过HashMap在put的时候,插入的元素超 ...
随机推荐
- easyui datagrid 首次不加载做法
我们一般遇到首次不执行查询,只有你点击查询按钮才查询的功能 我使用easyui的datagird做法是这样的: onBeforeLoad: function (param) { var firstLo ...
- set,pair容器使用方法
题目链接:http://codeforces.com/gym/100989/problem/D In this cafeteria, the N tables are all ordered in o ...
- 实力封装:Unity打包AssetBundle(四)
→→前情提要:窗口初现←← 让用户选择要打包的文件 时至今日,我们选择打包文件的方式依然是在Project面板或Hierarchy面板中用鼠标点选.现在既然有了窗口,我们自然希望可以将所有文件罗列在窗 ...
- vue 自定义过滤器 格式化金额(保留两位小数)
1.js部分 import Vue from 'vue' Vue.filter('money', function(val) { val = val.toString().replace(/\$|\, ...
- 《团队-Python 爬取豆瓣电影top250-成员简介及分工》
杨继尧,没有什么擅长的,会一点python,一点c#,爬取利用数据库,有些用法不太会,但是会在实现项目中查资料.
- 引用google字体
1.很简单直接 @import url(http://fonts.font.im/css?family=Shadows+Into+Light); 引入页面即可 2. 使用: font-fami ...
- 大数据-04-Hbase入门
本文主要来自于 http://dblab.xmu.edu.cn/blog/install-hbase/ 谢谢原作者 本指南介绍了HBase,并详细指引读者安装HBase. 前面第二章学习指南已经指导大 ...
- 测试之法 —— mock object
mock object 与真实对象相比,用来构造测试场景. 1. 一个实例 一个闹钟根据时间来进行提醒服务,如果过了下午5点钟就播放音频文件提醒大家下班了,如果我们要利用真实的对象来测试的话就只能苦苦 ...
- JavaScript中的内置对象-8--1.Array(数组)-Array构造函数; 数组的栈方法; 数组的转换方法; 数组的操作方法; 删除-插入-替换数组项; ECMAScript为数组实例添加的两个位置方法;
JavaScript内置对象-1Array(数组) 学习目标 1.掌握任何创建数组 2.掌握数值元素的读和写 3.掌握数组的length属性 如何创建数组 创建数组的基本方式有两种: 1.使用Arra ...
- C高级第三次作业
C高级第三次作业(1) 6-1 输出月份英文名 1.设计思路 (1)算法: 第一步:定义整型变量n,字符指针s,输入一个数赋给n. 第二步:调用函数getmonth将值赋给s. 第三步:在函数getm ...