scrapy 爬虫框架(一)
一 . scrapy 的安装
安装scrapy框架时,需要先安装依赖包。
#Linux:
pip3 install scrapy
#Windows:
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install pywin32
e. pip3 install scrapy
二.简介
文档:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/firefox.html
1.Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。
2.集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。
3.Scrapy一个开源和协作的框架,Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域。
4.可应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
5.Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。
因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
整体架构大致如下:

Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)。 - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回.可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
二.创建爬虫项目
1. 进入项目文件: 该爬虫项目存放的位置
1.创建项目命令: scrapy startproject 项目名
D:\study\爬虫\day7 > scrapy startproject XiaoHua 2.创建爬虫
1.先 cd 项目目录下
D:\study\爬虫\day7 > cd XiaoHua
2.再 执行: scrapy genspider 爬虫名 爬虫网站
D:\study\爬虫\day7\XiaoHua > scrapy genspider xiahua xiaohuar.com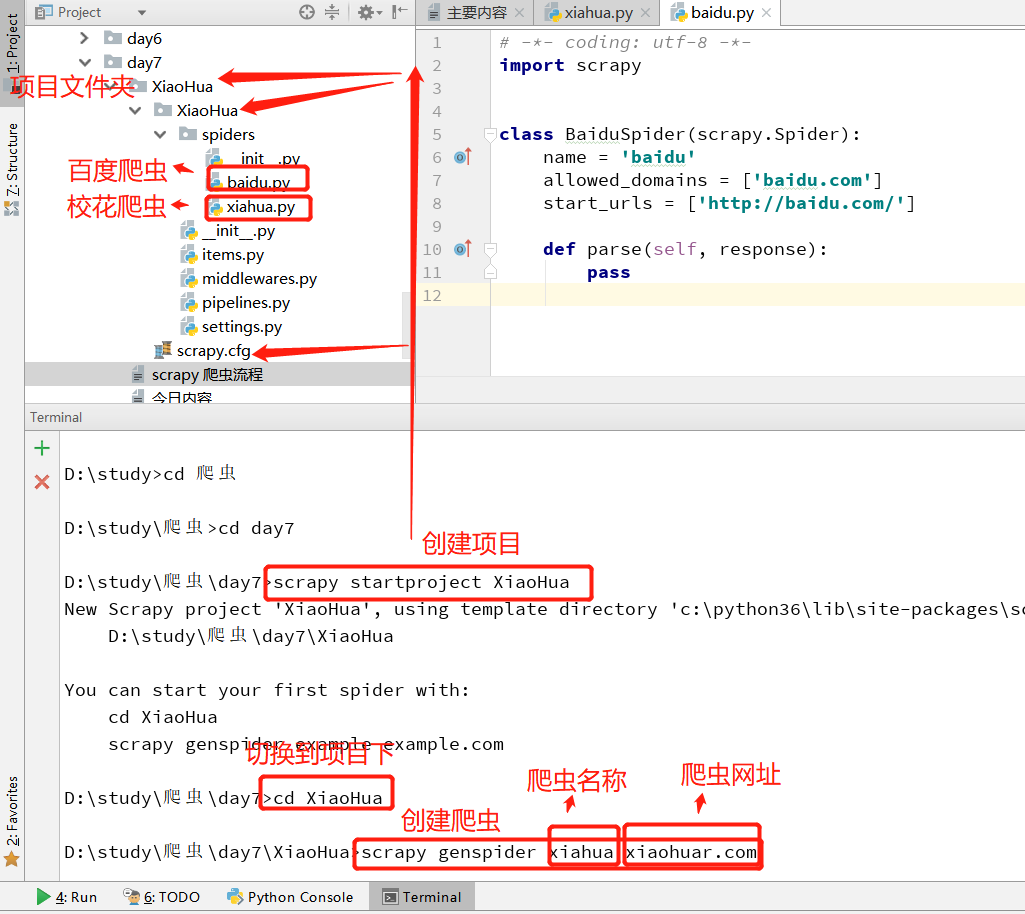
scrapy 爬虫框架(一)的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
随机推荐
- Python3 tkinter基础 Canvas background 创建白色的画布 create_line width 画宽的线
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- 古堡算式|2012年蓝桥杯B组题解析第二题-fishers
(4')古堡算式 福尔摩斯到某古堡探险,看到门上写着一个奇怪的算式: ABCDE * ? = EDCBA 他对华生说:"ABCDE应该代表不同的数字,问号也代表某个数字!" 华生: ...
- 【示例】Spring Quartz入门
JAVA 针对定时任务,有 Timer,Scheduler, Quartz 等几种实现方式,其中最常用的应该就是 Quartz 了. 一. Quartz的基本概念 在开始之前,我们必须了解以下的几个基 ...
- ES6中的函数和数组补漏
对象的函数解构 我们在前后端分离时,后端经常返回来JSON格式的数据,前端的美好愿望是直接把这个JSON格式数据当作参数,传递到函数内部进行处理.ES6就为我们提供了这样的解构赋值. let json ...
- Unity3D学习笔记(三十五):Shader着色器(2)- 顶点片元着色器
Alpha测试 AlphaTest Great:大于 AlphaTest Less:小于 AlphaTest Equal:等于 AlphaTest GEqual:大于等于 AlphaTest LEqu ...
- Docker7之Docker overview
Docker is an open platform for developing, shipping, and running applications. Docker enables you to ...
- HDU 6249 Alice’s Stamps(dp)
http://acm.hdu.edu.cn/showproblem.php?pid=6249 题意: 给出n个区间,求选k个区间的最大区间并. 思路: 可能存在左端点相同的多个区间,那么此时我们肯定选 ...
- SpringLog4j日志体系实现方式
1.通过web.xml读取log4j配置文件内容 2.通过不同的配置信息,来实现不同的业务输出,注意:log4j可以写入tomcat容器,也可以写入缓存,通过第三方平台读取 #输入规则#log4j.r ...
- 【Python】一些练习代码用的图片
- 【转】Windows下selenium+python自动化测试环境搭建
原文链接:http://www.cnblogs.com/test-of-philosophy/articles/4322918.html 搭建平台:windows 1.安装python,下载地址:ht ...