【python数据挖掘】批量爬取站长之家的图片
概述:
站长之家的图片爬取
使用BeautifulSoup解析html
通过浏览器的形式来爬取,爬取成功后以二进制保存,保存的时候根据每一页按页存放每一页的图片
第一页:http://sc.chinaz.com/tupian/index.html
第二页:http://sc.chinaz.com/tupian/index_2.html
第三页:http://sc.chinaz.com/tupian/index_3.html
以此类推,遍历20页
源代码
# @Author: lomtom
# @Date: 2020/2/27 14:22
# @email: lomtom@qq.com
# 站长之家的图片爬取
# 使用BeautifulSoup解析html
# 通过浏览器的形式来爬取,爬取成功后以二进制保存
# 第一页:http://sc.chinaz.com/tupian/index.html
# 第二页:http://sc.chinaz.com/tupian/index_2.html
# 第三页:http://sc.chinaz.com/tupian/index_3.html
# 遍历14页
import os
import requests
from bs4 import BeautifulSoup
def getImage():
url = ""
for i in range(1,15):
# 创建文件夹,每一页放进各自的文件夹
download = "images/%d/"%i
if not os.path.exists(download):
os.mkdir(download)
# url
if i ==1:
url = "http://sc.chinaz.com/tupian/index.html"
else:
url = "http://sc.chinaz.com/tupian/index_%d.html"%i
#发送请求获取响应,成功状态码为200
response = requests.get(url)
if response.status_code == 200:
# 使用bs解析网页
bs = BeautifulSoup(response.content,"html5lib")
# 定位到图片的div
warp = bs.find("div",attrs={"id":"container"})
# 获取img
imglist = warp.find_all_next("img")
for img in imglist:
# 获取图片名称和链接
title = img["alt"]
src = img["src2"]
# 存入文件
with open(download+title+".jpg","wb") as file:
file.write(requests.get(src).content)
print("第%d页打印完成"%i)
if __name__ == '__main__':
getImage()
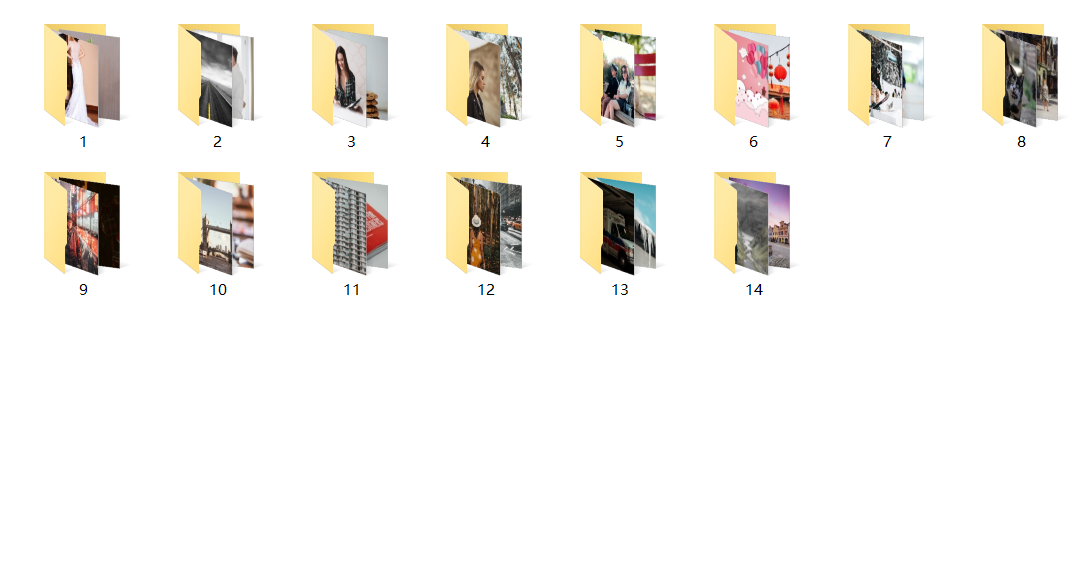
效果图
作者
【python数据挖掘】批量爬取站长之家的图片的更多相关文章
- python爬取站长之家植物图片
from lxml import etree from urllib import request import urllib.parse import time import os def hand ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 【Python】批量查询-提取站长之家IP批量查询的结果v1.0
0 前言 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 1 使 ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 【Python】批量查询-提取站长之家IP批量查询的结果加强版本v3.0
1.工具说明 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 某 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- 【Python】批量爬取网站URL测试Struts2-045漏洞
1.概述都懒得写了.... 就是批量测试用的,什么工具里扣出来的POC,然后根据自己的理解写了个爬网站首页URL的代码... #!/usr/bin/env python # -*- coding: u ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
随机推荐
- 亲测可用!在线购书系统项目分享(Java)
项目简介 项目来源于:https://gitee.com/suimz_admin/BookShop 一个基于JSP+Servlet+Jdbc的书店系统.涉及技术少,易于理解,适合JavaWeb初学者学 ...
- 当vps服务器被墙,如果用xshell连接
当然你的被墙了,肯定是访问不了,你得去找一个新的可用的节点去访问,在xshell里面设置代理就能连接上.上图. 然后是两个不同的结点 鼠标放在小火箭上面就能显示
- Message: 'chromedriver' executable needs to be available in the path.
环境:windows10 python:3.7.3 已经把 executable.exe 添加到了环境变量中,但还是会提示以上错误. 解决办法: from selenium import webdri ...
- GetWindowRect与GetClientRect 的区别
GetWindowRect 函数功能:该函数返回指定窗口的边框矩形的尺寸.该尺寸以相对于屏幕坐标左上角的屏幕坐标给出. 函数原型:BOOL GetWindowRect(HWND hWnd,LPRECT ...
- ajax 原生js封装ajax [转]
/* 封装ajax函数 * @param {string}opt.type http连接的方式,包括POST和GET两种方式 * @param {string}opt.url 发送请求的url * @ ...
- centos6.5下oracle11g下OGG单向复制
命名规范: local==> l remote==> r extract==> x data pump==> p ------------------------------- ...
- 用EFCore的 FluentAPI 方式生成MySql 带注释的数据库表结构
采用的是net Core 3.1框架下的 的WebAPI项目. 1. 创建ASP.NET Core Web项目 2. 添加NuGet引用包,包如下 Microsoft.EntityFramewor ...
- 详解Java8的日期和时间API
详解Java8的日期和时间API 在JDK1.0的时候,Java引入了java.util.Date来处理日期和时间:在JDK1.1的时候又引入了功能更强大的java.util.Calendar,但是C ...
- vue插件介绍
1.插件和组件的关系 在没有封装组件之前,如果不使用第三方插件,那么很多情况下我们会编写几个常用的组件来提供给页面使用,如Alert/Loading组件,而你可能需要在很多页面中引入并且通过compo ...
- css实现文字过长显示省略号的方法
<div class="title">当对象内文本溢出时显示省略标记</div> 这是一个例子,其实我们只需要显示如下长度: css实现网页中文字过长截取. ...