Spark笔记之使用UDF(User Define Function)
一、UDF介绍
UDF(User Define Function),即用户自定义函数,Spark的官方文档中没有对UDF做过多介绍,猜想可能是认为比较简单吧。
几乎所有sql数据库的实现都为用户提供了扩展接口来增强sql语句的处理能力,这些扩展称之为UDXXX,即用户定义(User Define)的XXX,这个XXX可以是对单行操作的UDF,或者是对多行操作的UDAF,或者是UDTF,本次主要介绍UDF。
UDF的UD表示用户定义,既然有用户定义,就会有系统内建(built-in),一些系统内建的函数比如abs,接受一个数字返回它的绝对值,比如substr对字符串进行截取,它们的特点就是在执行sql语句的时候对每行记录调用一次,每调用一次传入一些参数,这些参数通常是表的某一列或者某几列在当前行的值,然后产生一个输出作为结果。
适用场景:UDF使用频率极高,对于单条记录进行比较复杂的操作,使用内置函数无法完成或者比较复杂的情况都比较适合使用UDF。
二、使用UDF
2.1 在SQL语句中使用UDF
在sql语句中使用UDF指的是在spark.sql("select udf_foo(…)")这种方式使用UDF,套路大致有以下几步:
1. 实现UDF,可以是case class,可以是匿名类
2. 注册到spark,将类绑定到一个name,后续会使用这个name来调用函数
3. 在sql语句中调用注册的name调用UDF
下面是一个简单的示例:
package cc11001100.spark.sql.udf
import org.apache.spark.sql.SparkSession
object SparkUdfInSqlBasicUsageStudy {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkUdfStudy").getOrCreate()
import spark.implicits._
// 注册可以在sql语句中使用的UDF
spark.udf.register("to_uppercase", (s: String) => s.toUpperCase())
// 创建一张表
Seq((1, "foo"), (2, "bar")).toDF("id", "text").createOrReplaceTempView("t_foo")
spark.sql("select id, to_uppercase(text) from t_foo").show()
}
}
运行结果:
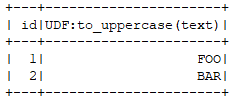
2.2 直接对列应用UDF(脱离sql)
在sql语句中使用比较麻烦,还要进行注册什么的,可以定义一个UDF然后将它应用到某个列上:
package cc11001100.spark.sql.udf
import org.apache.spark.sql.{SparkSession, functions}
object SparkUdfInFunctionBasicUsageStudy {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkUdfStudy").getOrCreate()
import spark.implicits._
val ds = Seq((1, "foo"), (2, "bar")).toDF("id", "text")
val toUpperCase = functions.udf((s: String) => s.toUpperCase)
ds.withColumn("text", toUpperCase('text)).show()
}
}
运行效果:
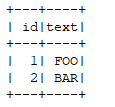
需要注意的是受Scala limit 22限制,自定义UDF最多接受22个参数,不过正常情况下完全够用了。
.
Spark笔记之使用UDF(User Define Function)的更多相关文章
- hive 添加UDF(user define function) hive的insert语句
add JAR /home/hadoop/study/study2/utf.jar; package my.bigdata.udf; import org.apache.hadoop.hive.ql. ...
- Adding New Functions to MySQL(User-Defined Function Interface UDF、Native Function)
catalog . How to Add New Functions to MySQL . Features of the User-Defined Function Interface . User ...
- Spark SQL 用户自定义函数UDF、用户自定义聚合函数UDAF 教程(Java踩坑教学版)
在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等 UDAF( ...
- 详解Spark sql用户自定义函数:UDF与UDAF
UDAF = USER DEFINED AGGREGATION FUNCTION Spark sql提供了丰富的内置函数供猿友们使用,辣为何还要用户自定义函数呢?实际的业务场景可能很复杂,内置函数ho ...
- spark笔记 环境配置
spark笔记 spark简介 saprk 有六个核心组件: SparkCore.SparkSQL.SparkStreaming.StructedStreaming.MLlib,Graphx Spar ...
- What is 'typeof define === 'function' && define['amd']' used for?
What is 'typeof define === 'function' && define['amd']' used for? This code checks for the p ...
- Spark笔记之使用UDAF(User Defined Aggregate Function)
一.UDAF简介 先解释一下什么是UDAF(User Defined Aggregate Function),即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出 ...
- spark 笔记 5: SparkContext,SparkConf
SparkContext 是spark的程序入口,相当于熟悉的'main'函数.它负责链接spark集群.创建RDD.创建累加计数器.创建广播变量. ) scheduler.initialize(ba ...
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
随机推荐
- Arcengine效率探究之一——属性的读取(转载)
http://blog.csdn.net/lk103852503/article/details/6566652 在写一个对属性表的统计函数时,发现执行速度奇慢无比,百思不得其解,其实算法并不复杂,后 ...
- PAT甲题题解-1014. Waiting in Line (30)-模拟,优先级队列
题意:n个窗口,每个窗口可以排m人.有k为顾客需要办理业务,给出了每个客户的办理业务时间.银行在8点开始服务,如果窗口都排满了,客户就得在黄线外等候.如果有一个窗口用户服务结束,黄线外的客户就进来一个 ...
- #个人博客作业Week1——浏览教材后提出的5个问题
1.对于MSF的团队模型,请问是团队中的哪个角色监督9项原则的实现?是否会浪费时间和精力在践行9项原则上?2.在调查用户需求和用户体验时如何让不同阶层的用户更多的参与度?3.想成为一位优秀的PM需要从 ...
- Linux内核分析 计算机是如何工作的——by王玥
1.冯诺依曼体系结构:也就是指存储程序计算机 硬件(存储程序计算机工作模式): 软件(程序员角度): 2.API:程序员与计算机的接口界面 ABI:程序与CPU的接口界面 3.X86的实现: 4.X8 ...
- 安全相关论文--Security and Dependability
安全相关论文--Security and Dependability 所参考的文献来自于Kreutz D, Ramos F M V, Esteves Verissimo P, et al. Softw ...
- [转帖]ESXi 网卡绑定 增加吞吐量的方法
VMware ESX 5.0 网卡负载均衡配置3种方法 http://blog.chinaunix.net/uid-186064-id-3984942.html (1) 基于端口的负载均衡 (Rout ...
- 微信小游戏 4M升8M分包加载
一.微信分包加载 微信分包加载教程 嘛,因为原来的4M太小了,满足不了小游戏内容的需求,现在提升到了8M.这8M可以分包加载,而不需要一次性加载8M. 如果是老版本,则分包加载不起作用,会一次加载8M ...
- python--inspect模块
inspect模块主要提供了四种用处: 1.对是否是模块.框架.函数进行类型检查 2.获取源码 3.获取类或者函数的参数信息 4.解析堆栈 一.type and members 1. inspect. ...
- hihoCoder 1631 Cats and Fish(ACM-ICPC北京赛区2017网络同步赛)
时间限制:1000ms 单点时限:1000ms 内存限制:256MB 描述 There are many homeless cats in PKU campus. They are all happy ...
- Spring点滴十:Spring自动装配(Autowire)
在基于XML配置元数据,在bean的配置信息中我们可以使用<constructor-arg/>和<property/>属性来实现Spring的依赖注入.Spring 容器也可以 ...