Contrastive Learning 对比学习 | RL 学 representation 时的对比学习
记录一下读的三篇相关文章。
01. Representation Learning with Contrastive Predictive Coding
- arxiv:https://arxiv.org/abs/1807.03748 ,2018 年的文章。
- 参考博客:知乎 | 理解 Contrastive Predictive Coding 和 NCE Loss
- (发现 lilian weng 也写过 对比学习的博客 )
1.1 文章解读
这篇文章的主要思想是,我们维护一个 discriminator,负责判断两个东西是否是一致的(也可认为是一个判断相似性的函数);比如,我的 encoding 和我下一时刻的 encoding(这篇文章所做的),两个相同类别的样本,两个正样本,我的 encoding 和我数据增强后的 encoding 等等。
在这篇文章(CPC)里,我们定义 discriminator 是 \(f_k(x_{x+k},c_t)=\exp(z_{x+k}^TW_kc_t)\),这个函数大概计算了 z 和 c 的内积。其中,\(z_{x+k}\) 是 \(x_{x+k}\) 真实值的 encoding,而 \(c_t\) 是序列预测模型(比如说 RNN 或 LSTM)最后一步的 hidden 值,我们一般用这个值来预测。
这篇文章的 loss function 是
\]
这是一种 maximize [exp / Σ exp] 的形式。(照搬原博客)怎么理解这个 loss function 呢,\(p(x_{t+k}|c_t)\) 指的是,我们选正在用的那个声音信号的 \(x_{t+k}\) ,而 \(p(x_{j})\) 指的是我们可以随便从其他的声音信号里选择一个片段。
回忆一下,我们刚才说过, \(f_k()\) 其实是在计算 \(c_t\) 的预测和 \(x_{t+k}\) (未来值)符不符合。那么对于随便从其他声音信号里选出的 \(x_j\),\(f_k(x_j,c_t)\) 应是相对较小的。
在具体实践时,大家常常在对一个 batch 进行训练时,把当前 sample 的 \((x_{t+k}^i,c_t^i)\)(这里上标表示 sample 的 id)当作 positive pair,把 batch 里其他 samples 和当前 sample 的预测值配对 \((x_{t+k}^j,c_t^i)\) 作为 negative pair (注意上标)。
1.2 个人理解
这篇文章主要在说 InfoNCE loss。InfoNCE loss 大概就是 maximize [exp / Σ exp] 的形式,公式:
\]
这貌似是比较现代的对比学习 loss function。还有一些比较古早的 loss function 形式,比如 Contrastive loss(Chopra et al. 2005),它希望最小化同类样本(\(y_i=y_j\))的 embedding 之间的距离,而最大化不同类样本的 embedding 距离:
+ \mathbb 1[y_i\neq y_j] \max\big(0,\epsilon- \|f(x_i)-f(x_j)\| \big)
\]
第一项代表,如果是同类别样本,则希望最小化它们 embedding 之间的距离;第二项代表,如果是不同类样本,则希望最大化 embedding 距离,但不要超过 ε,ε 是超参数,表示不同类之间的距离下限。
Triplet Loss 三元组损失(FaceNet ,Schroff et al. 2015) :
0, \|f(x)-f(x^+)\| - \|f(x)-f(x^+)\| + \epsilon \big)
\]
其中,x 是 anchor,x+ 是正样本,x- 是负样本。我们希望 x 靠近 x+、远离 x-。可以理解为,我们希望最大化 \(\|f(x)-f(x^+)\| - \|f(x)-f(x^+)\| - \epsilon\) ,即,anchor 离负样本的距离应该大于 anchor 离正样本的距离,距离差超过一个超参数 margin ε。
02. CURL: Contrastive Unsupervised Representations for Reinforcement Learning
- arxiv:https://arxiv.org/pdf/2004.04136 ,ICML 2020。
- GitHub:https://www.github.com/MishaLaskin/curl
curl 也应用了这种 maximize [exp / Σ exp] 的形式,它的 loss function 是:
\]
其中,q 是 query,貌似也可理解为 anchor,k 是 key,k+ 是正样本,ki 是负样本。anchor 和正样本 貌似都是图像裁剪得到的。
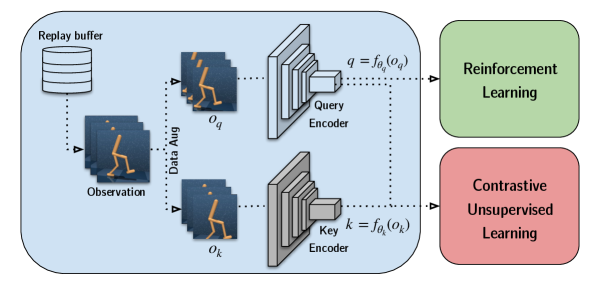
key encoder 的参数是 query encoder 的参数的 moving average,\(\theta_k=m\theta_k+(1-m)\theta_q\) 。
HIM 中,curl 是一个 baseline,HIM curl 的正样本是 adding gaussian perturbation ∼ N (µ = 0.0, σ = 0.1) 得到的。
03. Representation Matters: Offline Pretraining for Sequential Decision Making
做了很多 RL 相关的 representation learning 的 review 和技术比较,比较了各种实现在 imitation learning、offline RL 和 offline 2 online RL 上的效果。
arxiv:https://arxiv.org/pdf/2102.05815
Contrastive Learning 对比学习 | RL 学 representation 时的对比学习的更多相关文章
- ICLR2021对比学习(Contrastive Learning)NLP领域论文进展梳理
本文首发于微信公众号「对白的算法屋」,来一起学AI叭 大家好,卷王们and懂王们好,我是对白. 本次我挑选了ICLR2021中NLP领域下的六篇文章进行解读,包含了文本生成.自然语言理解.预训练语言模 ...
- 论文解读(S^3-CL)《Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 迁移学习(PCL)《PCL: Proxy-based Contrastive Learning for Domain Generalization》
论文信息 论文标题:PCL: Proxy-based Contrastive Learning for Domain Generalization论文作者:论文来源:论文地址:download 论文代 ...
- 论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息 论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning ...
- 迁移学习(DCCL)《Domain Confused Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Domain Confused Contrastive Learning for Unsupervised Domain Adaptation论文作者:Quanyu Long, T ...
- 迁移学习(CLDA)《CLDA: Contrastive Learning for Semi-Supervised Domain Adaptation》
论文信息 论文标题:CLDA: Contrastive Learning for Semi-Supervised Domain Adaptation论文作者:Ankit Singh论文来源:NeurI ...
- 论文解读(CDCL)《Cross-domain Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Cross-domain Contrastive Learning for Unsupervised Domain Adaptation论文作者:Rui Wang, Zuxuan ...
- Remote Sensing Images Semantic Segmentation with General Remote Sensing Vision Model via a Self-Supervised Contrastive Learning Method
论文阅读: Remote Sensing Images Semantic Segmentation with General Remote Sensing Vision Model via a Sel ...
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 谣言检测(GACL)《Rumor Detection on Social Media with Graph Adversarial Contrastive Learning》
论文信息 论文标题:Rumor Detection on Social Media with Graph AdversarialContrastive Learning论文作者:Tiening Sun ...
随机推荐
- .NET 压缩/解压文件
本文为大家介绍下.NET解压/压缩zip文件.虽然解压缩不是啥核心技术,但压缩性能以及进度处理还是需要关注下,针对使用较多的zip开源组件验证,给大家提供技术选型 目前了解到的常用技术方案有Syste ...
- [学习笔记] 2-SAT
引入 有 \(n\) 个变量 \(x_1 \cdots x_n\),每个变量的取值范围为 \(\{0,1\}\),另有 \(m\) 个条件,每个条件都是对其中两个变量的取值限制,形如要么 \(x_i ...
- 查看tensorflow pb模型文件
""" @Author: Qiangz @Date: 2019/7/5 @Description: """ import tensorflo ...
- VS2019 查看源码,使用F12查看源码
前几天在微软社区看到VS的功能演示时,偶然看到此功能,对于开发人员来说太有用了,特此记录分享出来希望可以帮助到家. 具体设置步骤,打开vs2019,在工具>选项>文本编辑器>c#&g ...
- 想好新年去哪了吗?合合信息扫描全能王用AI“留住”年味
还有不到十天,除夕就要到了.近几年春节假期中,有人第一次带着孩子直击海面冰风,坐船回老家:也有人选择"漫游"国内外,在旅行中迎接新春的朝气.合合信息旗下扫描全能王APP通过AI扫描 ...
- 嵌入式Linux ubi文件系统制作、分区设置、只读文件系统,uboot启动参数root
当前平台, 基于君正的X10000平台的嵌入式Linux 系统 0 目的 我要设置根文件系统为可读写, 设置data分区上的文件系统为只读 1 设置各文件系统的读写属性 /bin/mount -o ...
- [Tkey] CodeForces 1267G Game Relics
太神了这题,膜拜出题人 orz. 思考一 首先是大家都提到的一点,先抽卡再买.这里来做个数学分析. 假设我们还剩 \(k\) 种没有买,其实我们是有式子来算出它的花费期望的.WIKI 上提到,假设一个 ...
- vue 赶鸭子上架入门笔记(一) 安装开发环境
准备接手一个 vue 的前端项目,从零开始学习 vue.目标不高大上,能看得懂代码,能进行简单的修改,改完能打包和部署. 首先解决 vue 开发环境的准备.访问 Node.js 官方网站,下载适合你操 ...
- Guava中的Joiner和Splitter
目录 Guava 介绍 Joiner list转string map转string 处理嵌套集合 处理null值 Splitter string转list string转map 多个拆分符 输出 代码 ...
- 16 Transformer 的编码器(Encodes)——我在做更优秀的词向量
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https:// ...