JuiceFS v1.3-beta1:新增 Python SDK,特定场景性能 3 倍于 FUSE
在当前众多 AI 和数据科学应用中,Python 已成为最主流的编程语言之一。为了方便用户在这些场景中更高效地使用 JuiceFS,我们在社区版 v1.3 中推出了 JuiceFS Python SDK(下文简称 Python SDK)。它不仅简化了对 JuiceFS 的访问方式,还提升了在受限环境下的可用性。例如在 Serverless 场景中,用户通常无法自己挂载文件系统,通过 Python SDK,无需挂载即可直接读写 JuiceFS 中的数据,极大提升了灵活性。同时,在特定高性能场景下,Python SDK 提供了更优的性能和体验。
本文将简要介绍 Python SDK 的功能特性,以及我们在性能方面的一些探索实践。欢迎社区用户尝试这一新功能,并反馈使用体验和建议。
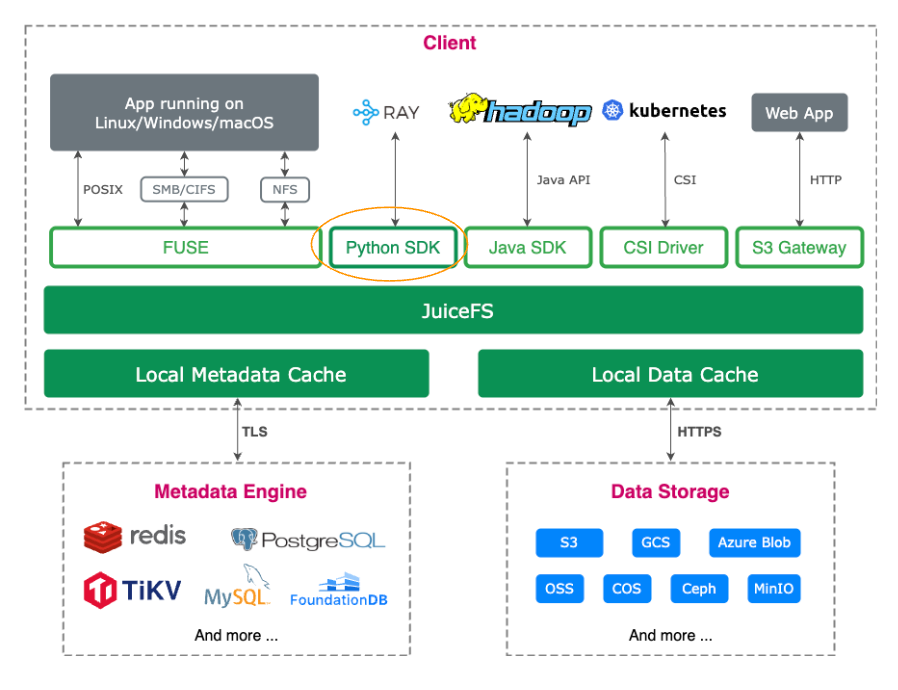
01 Python SDK 功能概览
JuiceFS Python SDK 提供了多类接口,从文件操作到生态集成,覆盖多样的使用场景。
JuiceFS 客户端接口
juicefs.Client 封装了 JuiceFS 客户端的主要功能。它不仅支持诸如 open、rename 等标准文件系统操作,还提供了如 warmup、summary、rmr 等扩展功能接口,便于开发者实现更复杂的管理需求。
用户可以通过 Python 的 help() 函数快速查看相关文档和接口说明,针对每个类和对象都可以单独查看其方法和用途,从而快速了解其功能。
初始化 JuiceFS 客户端的方式也非常简洁。用户只需传入文件系统的名称(name)与元数据地址(meta)两个参数即可完成初始化。完成初始化后,开发者便可以像使用本地文件系统一样,列出根目录内容或进行文件操作。
兼容 Python 原生文件接口
JuiceFS Python SDK 提供的文件操作接口,与 Python 原生的 open() 方法返回的文件对象保持兼容。也就是说,当用户使用 client.open() 打开一个文件后,返回的对象支持与标准 Python 文件对象一致的操作方法,例如 read()、write()、seek()、close() 等。用户可以非常方便地将 JuiceFS 的文件系统无缝集成进已有的 Python 代码逻辑中,而无需额外学习或适配新的 API。无论是在数据预处理、模型训练,还是日志管理等场景中,都可以直接使用 Python SDK 进行文件读写操作。
支持 fsspec 接口,轻松集成 Ray
为了更好地支持 AI 训练与数据科学等高性能数据处理场景,JuiceFS Python SDK 提供了对 fsspec 接口的原生支持。fsspec 是 Python 生态中用于统一文件系统访问的标准抽象层,已被广泛集成到如 Ray 等主流 AI 框架中。
JuiceFS 能够无缝对接 AI 工具链,让用户无需修改业务逻辑,即可像操作本地磁盘一样,便捷地接入 JuiceFS 存储,在提升 I/O 性能的同时,降低数据管理和扩展成本。
以下是一个典型示例,展示如何将 JuiceFS 作为 fsspec 的后端文件系统使用:
import fsspec
import ray
import sys
sys.path.append('.')
import sdk.python.juicefs.juicefs.spec
jfs = fsspec.filesystem("jfs", auto_mkdir=True, name="myjfs", meta="redis://localhost")
dsjfs = ray.data.read_csv('/ray_demo_data.csv', filesystem=jfs)
dsjfs.count()
只需提供文件系统名称和元数据地址等必要参数,其余的使用方式则与其他基于 fsspec 的抽象文件系统保持一致。
这一设计进一步提升了 JuiceFS 在如 Ray 等分布式计算框架中的可用性与集成效率,帮助用户更轻松地将 JuiceFS 融入现有的数据加载与处理流程。
扩展 API
除了常规的文件操作接口,JuiceFS Python SDK 还支持一系列扩展 API,例如 summary、info 等。这些接口在命令行工具中广泛使用,很多用户已较为熟悉。
在 Python SDK 中,这些扩展命令的返回结果以字典(dict)形式呈现,便于在脚本中进行访问与索引。例如,使用 summary 接口时,可以直接通过键值方式获取文件或目录的统计信息:
summary_info = client.summary("/path/to/dir")
print(summary_info["fileCount"])
这种字典结构的返回形式使得用户在编写自动化脚本时更加方便,也更易于集成到现有的 Python 数据处理逻辑中。
02 性能探索:FFRecord 数据加载实践 3 倍于 FUSE
在使用 FUSE 访问数据时,单次 I/O 请求的上限为 128KB,即便通过 direct I/O 可提升至 1MB,但一次完整的数据读取,仍然会被内核切分成多个小块,造成额外的 I/O 请求放大。 这些小请求是同步串行提交的,在访问冷数据(即尚未缓存在本地的数据)时,会显著拉高延迟,降低整体吞吐性能;同时,连续的多个请求还会启动 JuiceFS 的预读流程,导致不必要的读放大。
我们希望通过 Python SDK 绕过 FUSE 的请求粒度限制,支持更大尺寸的请求,避免碎片带来的性能影响。为了验证在 Python SDK 的性能表现,我们以幻方开源的数据集格式 FFRecord 为例,设计并实现了一个基于 Python SDK 的 FFRecord 数据加载 demo。FFRecord 是幻方开源的一种数据格式,具有合并小文件、减少读取开销、支持随机批量读取和数据校验等优势。关于 FFRecord 的设计意图和价值可以参考幻方的一篇博客 。
在使用 FUSE 加载 FFRecord 数据时,遇到的核心问题之一是上文提到的请求粒度受限——FUSE 默认每次最大读取请求为 128KB。当读取请求被切分为多个 128KB 的块,会显著放大 I/O 延迟。同时,JuiceFS 客户端在处理连续的读取请求时,会自动进行一定范围内的预读。这会造成 2~4 倍的数据读放大,进一步增加系统负担。
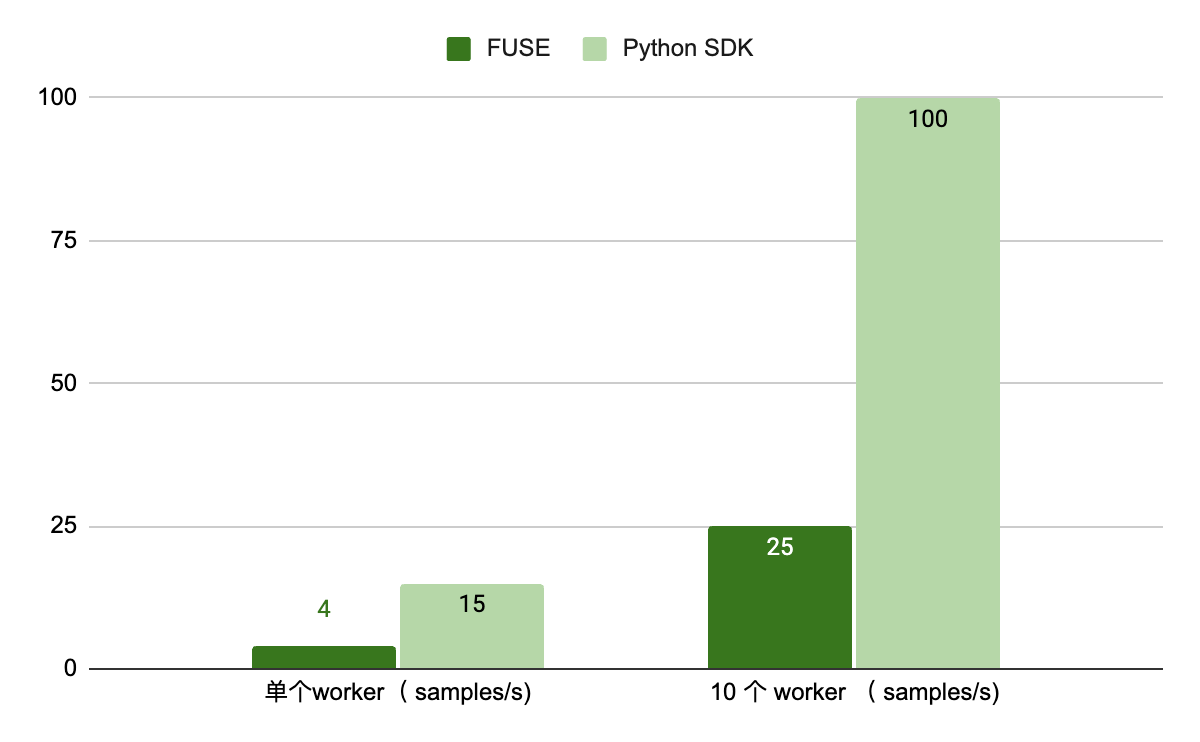
为此,我们基于 Python SDK 实现一个 FFRecord dataloader 来优化性能。在我们设计的一组测试中,生成了一个包含 1000 个样本的数据集,单个 sample 大小约为 3MB±500KB。实验结果显示,使用 Python SDK 加载数据,相较于默认的 FUSE 挂载方式,单 worker 和多 worker 场景下的加载性能分别提升了约 3.75 倍和 4 倍。
该 demo 的实现逻辑:底层通过 file_reader 类解析并校验 FFRecord 文件格式,包括对 sample 和文件头的处理。header 部分在初始化时加载并按格式记录所有样本的 offset 信息,为后续读取提供支持。此外,file_reader 提供了 read_one 和 read_batch 两种接口,便于在单样本或批量样本读取时灵活调用,也为后续开发和扩展提供了便利。
在当前 Python SDK 实现中仍存在一些限制,例如不支持并发 read_ batch,只能串行执行。后续会将并发 read_batch 下沉至动态链接库中完成,或在 Python 中实现异步逻辑。此外,在支持 num_workers 并发加载时,需要在每个 worker 进程中初始化 JuiceFS 客户端实例。这是因为主进程 fork 子进程时,客户端资源无法共享,因此需要单独初始化。这一设计虽带来额外开销,但总体负担不大。
上层的 dataset 和 dataloader 实现相对简单,直接调用底层 reader 即可完成加载流程。我们还提供了一个数据集生成脚本,用于生成 demo.ffr 文件并进行加载,相关代码都已经整理进社区版代码库,供大家参考。
03 Python SDK 安装
目前,JuiceFS 的 Python SDK 已经在 v1.3-beta1 版本发布。该 SDK 复用了JuiceFS Java SDK中依赖的底层动态链接库,该库中实现了 JuiceFS 客户端的核心对象与功能。
在 Python SDK 中,我们通过 Python 接口将这些底层功能进行了暴露,方便用户直接在 Python 环境中调用。因此,安装过程并不复杂,主要包括两个步骤:一是编译动态链接库,二是打包并安装 Python 模块即可。详情,可参考官网文档。
04 小结
Python SDK 为 JuiceFS 带来了更灵活的集成方式,既兼容 Python 原生文件接口,也适配了 fsspec 统一抽象层,能够更方便地集成到如 Ray 等 AI 组件中使用。在高性能访问方面,我们在 FFRecord 数据加载这一特定场景进行了探索,初步验证了它的性能潜力。
完整的示例代码已提交至社区版仓库,欢迎大家参考使用。我们也期待更多社区用户参与试用和反馈,共同推动 Python SDK 能力的持续完善。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。
JuiceFS v1.3-beta1:新增 Python SDK,特定场景性能 3 倍于 FUSE的更多相关文章
- JuiceFS v1.0.0 Beta1 发布,加强数据安全能力
在 JuiceFS 开源一周年之际,我们迎来了首个里程碑版本 JuiceFS v1.0.0 Beta1,并将开源许可从 AGPL v3 修改为 Apache License 2.0. JuiceFS ...
- JuiceFS v1.0 beta3 发布,支持 etcd、Amazon MemoryDB、Redis Cluster
JuiceFS v1.0 beta3 在元数据引擎方面继续增强,新增 etcd 支持小于 200 万文件的使用场景,相比 Redis 可以提供更好的可用性和安全性.同时支持了 Amazon Memor ...
- 【Azure Developer】使用 Python SDK连接Azure Storage Account, 计算Blob大小代码示例
问题描述 在微软云环境中,使用python SDK连接存储账号(Storage Account)需要计算Blob大小?虽然Azure提供了一个专用工具Azure Storage Explorer可以统 ...
- JuiceFS V1.0 RC1 发布,大幅优化 dump/load 命令性能, 深度用户不容错过
各位社区的伙伴, JuiceFS v1.0 RC1 今天正式发布了!这个版本中,最值得关注的是对元数据迁移备份工具 dump/load 的优化. 这个优化需求来自于某个社区重度用户,这个用户在将亿级数 ...
- 七牛云存储Python SDK使用教程 - 上传策略详解
文 七牛云存储Python SDK使用教程 - 上传策略详解 七牛云存储 python-sdk 七牛云存储教程 jemygraw 2015年01月04日发布 推荐 1 推荐 收藏 2 收藏,2.7k ...
- <Chapter 2>2-1-1.安装Python SDK
App Engine包含两个Python运行时环境:一个基于Python2.5的传统环境,以及一个运行Python2.7的新环境.这个新环境不仅仅是有一个轻微的新版本的Python解释器.主要是,这个 ...
- openstack python sdk list tenants get token get servers
1,openstack python sdk 获取token 获取租户tenants projects #!/bin/bash export OS_PROJECT_DOMAIN_ID=default ...
- wzplayer for android V1.5.3 (新增YUV文件播放)
wzplayer for android V1.5.3 新增功能 1.使用gl es2 播放 yuv 文件. 联系方式:weinyzhou86@gmail.com QQ:514540005 版权所有, ...
- AWS s3 python sdk code examples
Yet another easy-to-understand, easy-to-use aws s3 python sdk code examples. github地址:https://github ...
- 腾讯云CDN python SDK
腾讯云CDN python SDK 博主在开发时偶尔要用到CDN,感觉适合学生党的应该是腾讯云的CDN了,还提供了每月10G的流量,博主平时学习使用已经足够了. 代码 #coding=utf-8 fr ...
随机推荐
- Deepseek学习随笔(10)--- 本地AI神器Cherry Studio & Chatbox 保姆级教程(附网盘链接)
本篇介绍的 Cherry Studio 和 Chatbox 两款工具,只需简单几步,即可实现本地化部署AI能力,支持对话.编程.绘图等多场景应用.本文将手把手教你从零开始配置使用! 一.软件下载:两步 ...
- DeepSeek引发创业的思考
2025年春节最火的就是DeepSeek,就像08年小沈阳的火一样,越来越多的不是Ai这个行业的人开始越来越关注Ai,作为一个一直从事Ai的工作者,看到了ChatGPT的涌现后,中国再次冲出来的中国式 ...
- Minecraft server.properties 参数含义 1.18.1,Java版
服务器搭建 参照: https://www.spigotmc.org/wiki/buildtools/#latest 参数含义 #Fri Feb 11 15:20:40 CST 2022 # 启用jm ...
- CMD批处理脚本+VBScript脚本+Potplayer 实现文件夹内所有视频的截图任务(指定时间点)
实现自动化视频截图,一般会直接借视频编解码如FFmpeg,动用相关函数来实现,直接从解码源头设计程序.然而我没有接触过FFmpeg,借助cmd批处理,以及vbs,还有现成的播放器potplayer,一 ...
- manim边学边做--场景Scene简介
在 Manim 社区版本中,Scene(场景)是构建动画的核心概念之一,它为我们提供了一个结构化的方式来组织和呈现动画内容. 本文将介绍什么是Scene,它在Manim动画中的作用,以及不同类型的Sc ...
- Vue3路由进阶实战:深度解析参数传递与导航守卫核心技术
一.路由参数传递的进阶应用技巧 1.1 路由配置与参数验证 // router/index.js { path: '/user/:userId(\\d+)', // 使用正则表达式限制只匹配数字 na ...
- CICFlowMeter 使用方法
前言 因实验需要提取流量特征,就找到了这个较为著名的流量特征提取工具 CICFlowMeter .例如 CIC-IDS-2017 数据集就是通过这个工具提取而来. 网络上的教程众说纷纭,但我始终是无法 ...
- KTransformer实战DeepSeek-R1-1.58bit量化模型
技术背景 在上一篇文章中,我们介绍过KTransformers大模型高性能加载工具的安装和使用方法.但是当时因为是在一个比较老旧的硬件上面进行测试,其实并没有真正的运行起来.现在补一个在KTransf ...
- 0003 Failed to build the application: build go_beego/src/hello: cannot load
我使用beego框架快速建立了一个应用,可当我运行 bee run的时候,出现了如下错误 D:\go_beego\src\product>bee run ______ | ___ \ | |_/ ...
- 云服务器下如何部署Django项目详细操作步骤
前期本人完成了"编写你的第一个 Django 应用程序",有了一个简单的项目代码,在本地window系统自测没问题了,接下来就想办法部署到服务器上,可以通过公网访问我们的Djang ...