Python实现KNN算法
Python实现Knn算法
关键词:KNN、K-近邻(KNN)算法、欧氏距离、曼哈顿距离
KNN是通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
KNN算法的思想总结:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
#coding:utf-8
import requests, json, time, re, os, sys, time
import urllib2
import random
import numpy as np #设置为utf-8模式
reload(sys)
sys.setdefaultencoding( "utf-8" ) #读取文本文件,构建二维数组
def readDataFile(filename,format):
if format:
pass
else:
format = ','
list = []
#去除首位空格
filename = filename.strip()
#判断数据文件是否存在
if os.path.isfile(filename):
pass
file_object = open(filename,'rb')
lines = file_object.readlines()
for line in lines:
tmp = []
line = line.strip()
for value in line.split(format)[:-1]:
tmp.append(float(value))
tmp.append(line.split(format)[-1])
list.append(tmp)
else:
print "%s is not exists " % (filename)
return list #读取文本数据,拆分原始数据为特征和标签,返回特征值和标签值
def createData(filename,format=','):
data_label = readDataFile(filename,format)
if len(data_label) > 0:
label = []
data = []
#data_label = [[1,100,123,'A'],[2,99,123,'A'],[100,1,12,'B'],[99,2,23,'B']]
for each in data_label:
label.append(each[-1])
data.append(each[:-1])
return data,label #根据输入数据和测试数据,进行分类
def calculateDistance(input,data,label,k):
classes = 'Error' if len(data[0])==0 or len(label) == 0:
print 'data or label is null'
pass
elif k > len(data) :
print "k : %s is out of bounds" % (k)
pass
elif len(input) <> len(data[0]):
print "特征变量值不够,输入变量特征个数为:%s,训练特征变量个数为:%s" % (len(input),len(data[0]))
pass
else:
result = []
length = len(input)
for i in range(len(data)):
sum = 0
for j in range(length):
#pow(5,2) 标识5的平方为25,取两点之间的距离的平方并累加
sum = sum + pow(input[j] - data[i][j],2)
#取平方根
sum = pow(sum,0.5)
result.append(sum)
#print result
result = np.array(result) #argsort()根据元素的值从小到大对元素进行排序,返回下标
sortedDistIndex = np.argsort(result) #统计前k个数中各个标签的个数
classCount={}
for i in range(k):
voteLabel = label[sortedDistIndex[i]]
###对选取的K个样本所属的类别个数进行统计
#dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回默认值None。
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
###选取出现的类别次数最多的类别
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes filename = '/home/shutong/jim/crawl/data.csv'
data,label = createData(filename)
input = [1,20]
k = 4
result = calculateDistance(input,data,label,k)
print input,result
其中测试数据如图:
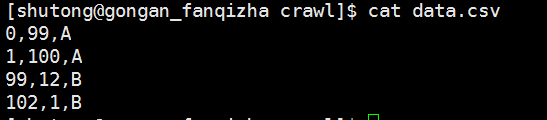
输入数据为:input = [1,20],预测它的标签为A还是B?
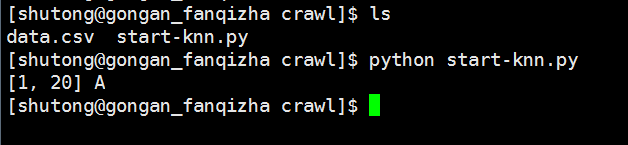
最终预测结果为:A
Python实现KNN算法的更多相关文章
- Python实现KNN算法及手写程序识别
1.Python实现KNN算法 输入:inX:与现有数据集(1xN)进行比较的向量 dataSet:已知向量的大小m数据集(NxM) 个标签:数据集标签(1xM矢量) k:用于比较的邻居数 ...
- [Python] 应用kNN算法预测豆瓣电影用户的性别
应用kNN算法预测豆瓣电影用户的性别 摘要 本文认为不同性别的人偏好的电影类型会有所不同,因此进行了此实验.利用较为活跃的274位豆瓣用户最近观看的100部电影,对其类型进行统计,以得到的37种电影类 ...
- ML一:python的KNN算法
(1):list的排序算法: 参考链接:http://blog.csdn.net/horin153/article/details/7076321 示例: DisListSorted = sorted ...
- 利用Python实现kNN算法
邻近算法(k-NearestNeighbor) 是机器学习中的一种分类(classification)算法,也是机器学习中最简单的算法之一了.虽然很简单,但在解决特定问题时却能发挥很好的效果.因此,学 ...
- 基于python 实现KNN 算法
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/11/7 14:50 # @Author : gylhaut # @Site ...
- 吴裕雄 python 机器学习-KNN算法(1)
import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, ...
- knn算法详解
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 机器学习回顾篇(6):KNN算法
1 引言 本文将从算法原理出发,展开介绍KNN算法,并结合机器学习中常用的Iris数据集通过代码实例演示KNN算法用法和实现. 2 算法原理 KNN(kNN,k-NearestNeighbor)算法, ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
随机推荐
- 监控和安全运维 1.7 nagios配置邮件告警
8. 配置邮件告警 服务端 vim /etc/nagios/objects/contacts.cfg 增加: define contact{ contact_name use generic-cont ...
- Python基础学习四 列表、元组、字典、集合
列表list,用中括号“[ ]”表示 1.任意对象的有序集合 列表是一组任意类型的值,按照一定顺序组合而成的 2.通过偏移读取 组成列表的值叫做元素(Elements).每一个元素被标识一个索引,第一 ...
- 19-EasyNetQ:用EasyNetQ.Hosepipe重新提交错误信息
EasyNetQ.Hosepipe是EasyNetQ队列管理工具.用来取回队列中的消息并重新发布这些消息.还可以用它来检测错误队列,并重试发布消息. 用法 EasyNetQ.Hosepipe.exe ...
- Scala中的函数
Scala中的函数 提纲 1.Scala中的函数简介 2.Scala中的函数的各种写法 1.Scala中的函数简介 =================== Scala是函数式编程和面向对象式编程的混合 ...
- 从SQL Server中清除msdb备份和恢复记录
正如我在前面的技巧“您的数据库上次恢复是什么时候呢?”中提到的,SQL Server使msdb数据库内系统表中的备份和恢复记录保持激活状态.没有正常的维护,这些系统表将变得很大,从而导致对于msdb数 ...
- java基础之多线程四:简单案例
多线程案例: 有一个包包的数量为100个,分别从实体店和官网进行售卖.使用多线程的方式,分别打印实体店和官网卖出包包的信息.分别统计官网和实体店各卖出了多少个包包 第一种方法 继承Thread类: p ...
- fhq-treap模板
模板保存. #include<iostream> #include<cstdio> #include<cstring> #include<ctime> ...
- Linux 各文件系统配置
区分目录跟文件 可执行文件:可以拿出来直接运行的命令. 符号链接 重要的目录 bin 里面是命令. etc 重要的配置文件.各种软件的配置文件.以后要配置网络环境,linux运行环境都是在这里进行配置 ...
- 面试题:bootstrap栅格系统
Bootstrap是一个支持响应式的Css框架它提供了很多组件,如导航条,面板,菜单,form表单,还有栅格,而且他们这些都是支持响应式的,可以在各种设备上进行完美的展现.这里面我感觉最有价值的就是b ...
- 面试题:servlet jsp cook session 背1
一.Servlet是什么?JSP是什么?它们的联系与区别是什么? Servlet是Java编写的运行在Servlet容器的服务端程序,狭义的Servlet是指Servlet接口,广义的Servlet是 ...